
【動画認識】YouTubeを利用した教師あり学習!?動画認識フレームワークOmniSourceが新登場!!
3つの要点
✔️ 新たな動画認識フレームワークOmniSourceがSOTAを達成
✔️ InstagramやYouTubeなどウェブ上の画像や動画を利用した教師あり学習
✔️ Joint Trainingにより、画像、短い動画、トリミングされていない長い動画などのデータフォーマット間の違いを克服
Omni-sourced Webly-supervised Learning for Video Recognition
written by Haodong Duan, Yue Zhao, Yuanjun Xiong, Wentao Liu, Dahua Lin
(Submitted on 29 Mar 2020 (v1), last revised 25 Aug 2020 (this version, v2))
Comments: Accepted to ECCV2020.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
official
comm
概要
本論文は、ECCV2020に採択された論文で、動画認識のための新しいフレームワークOmniSourceを提案したものです。ウェブ上の様々なデータ(画像・短い動画・トリミングされていない長い動画など)のデータフォーマット間の違いを克服し、ウェブ教師付き学習により高精度な動画認識を実現しています。
まず、タスクに特化したデータが収集され、teacher modelによって複数のフォーマットを持つデータが単一のフォーマットに変換されます。次に、複数のデータソースとフォーマットの間のドメインギャップに対処するために、ジョイントトレーニングという手法が提案されています。ジョイントトレーニングでは、data balancing、 resampling、 cross-dataset mixupなどの手法が採用されています。
実験では、複数のデータソースとフォーマットからのデータを利用することで、OmniSourceがトレーニングにおいてデータ効率が優れていることが示されています。人間がラベリングを行わずにインターネット上でクローリングしたわずか350万枚のがぞうと80万分の動画(先行研究の2%未満)で、OmniSourceで学習したモデルは、Kinetics-400ベンチマークにおいて、2Dおよび3D-ConvNetベースラインモデルのTop-1 accuracyを3。0%と3。9%向上させました。OmniSourceは、この他にも事前トレーニングによってSOTAを達成しています。
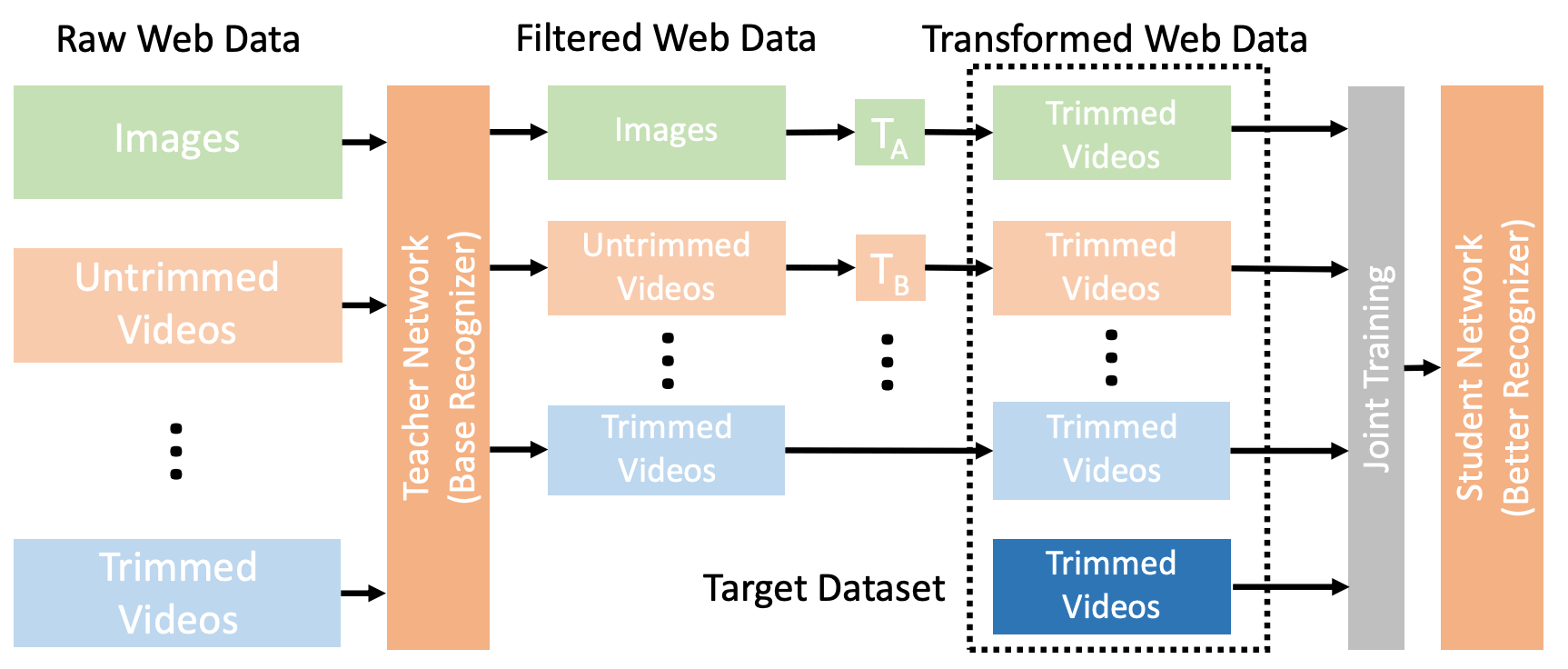
上図はOmniSourceの概念図になります。まず、対象となるデータセット上で教師ネットワークを訓練します。次に、この教師ネットワークを用いて、収集した様々なウェブデータを抽出し、ノイズを減らし、データの品質を向上させます。また、抽出されたデータに対しては、それぞれのフォーマットに対応した特殊な変換を行います。対象となるデータセットと補助的なウェブデータセットを用いて、教師ネットワークのJoint Trainingを行います。
続きを読むには
(5660文字画像13枚)AI-SCHOLARに
登録いただく必要があります。



この記事に関するカテゴリー






