
【MMSEARCH】画像とテキストを統合したマルチモーダル検索システム
3つの要点
✔️ MMSEARCH-ENGINEは、画像とテキストを統合して検索できるマルチモーダル検索システム
✔️ 実験でGPT-4oが優れた検索精度を示し、従来の検索エンジンを超えた
✔️ RequeryとRerankタスクの改善が、さらなる性能向上の鍵
MMSearch: Benchmarking the Potential of Large Models as Multi-modal Search Engines
written by Dongzhi Jiang, Renrui Zhang, Ziyu Guo, Yanmin Wu, Jiayi Lei, Pengshuo Qiu, Pan Lu, Zehui Chen, Guanglu Song, Peng Gao, Yu Liu, Chunyuan Li, Hongsheng Li
(Submitted on 19 Sep 2024)
Comments: Project Page: this https URL
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Information Retrieval (cs.IR)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
背景
従来の検索エンジンは主にテキストのみを扱うため、画像とテキストが組み合わさった情報を十分に検索・処理することが難しい状況にありました。例えば、ウェブサイトの中では画像とテキストが複雑に交差して表示されることが一般的ですが、現状のAI検索エンジンではそのようなコンテンツを効率的に処理できていません。
この問題に対応するため、研究者たちは「MMSEARCH-ENGINE」というシステムを開発しました。このシステムは、どのLMMにも適用可能なマルチモーダル検索機能を持たせるための仕組みです。これにより、LMMが単なるテキスト検索だけでなく、画像情報も活用しながら、より複雑な検索要求に対応できるようになります。実際のウェブ検索の過程では、ユーザーの質問をより検索エンジンに適した形式に変換し、得られた検索結果を再評価・再ランキングし、最後にその情報をまとめて提示する一連の流れが必要です。
このシステムはそのすべてのステップをLMMに任せており、最終的にはより正確で関連性の高い情報を提供できることを目指しています。
提案手法
この論文が提案している手法は、マルチモーダル検索エンジンとしてのLMMに特化した「MMSEARCH-ENGINE」です。
MMSEARCH-ENGINEは、LMMに画像とテキストの両方の情報を同時に処理できるマルチモーダル検索能力を追加するために開発されたフレームワークです。このシステムでは、まずユーザーのクエリ(検索要求)を適切な形式に再変換(Requery)するステップから始まります。多くの場合、ユーザーが入力するクエリは検索エンジンに適していないことがあるため、LMMsがクエリを最適化します。次に、得られた検索結果の中から最も関連性の高いウェブサイトを再ランキング(Rerank)し、最後にその情報を基にした要約(Summarization)を行います。
このMMSEARCH-ENGINEは、視覚的な情報とテキスト情報を統合して処理する能力を持ち、具体的には、Google Lensを利用して画像からの情報を抽出したり、ウェブサイトのスクリーンショットを取得して、それをLMMに渡すことで、視覚的な手がかりも検索プロセスに反映させています。これにより、ユーザーのクエリが画像を含んでいる場合でも、その画像の内容を基にしたより精度の高い検索結果が得られます。
さらに、この手法を評価するために、MMSEARCHというベンチマークが設けられています。これは300件の手動収集されたクエリを用いて、LMMsのマルチモーダル検索能力を測定します。クエリは最新のニュースや専門的な知識分野にわたっており、それぞれのクエリは画像とテキストの情報を組み合わせた複雑な内容を含んでいます。
実験
この論文の実験は、提案されたMMSEARCH-ENGINEの有効性を確認するために、複数の大規模マルチモーダルモデル(LMMs)を用いて評価されています。実験では、クローズドなLMM(例えば、GPT-4VやClaude 3.5 Sonnet)およびオープンソースLMM(例えば、Qwen2-VL-7BやLLaVA-OneVision)を使用して、提案手法のパフォーマンスが測定されています。
実験は、主に3つのコアタスクを含んでいます。それは「Requery(再検索)」、「Rerank(再ランク付け)」、そして「Summarization(要約)」です。まず、ユーザーのクエリを検索エンジンに適した形式に変換するRequeryタスクが行われ、その後、取得した複数のウェブサイトの情報をもとに、最も関連性の高いものを選択するRerankタスクが続きます。最後に、選ばれた情報から適切な答えを抽出するSummarizationタスクが実行されます。
この3つのタスクに加えて、全てのステップを通じて行われる「エンド・ツー・エンド」の評価も行われました。このエンド・ツー・エンドのタスクは、システム全体がユーザーのクエリに対してどれだけ正確に結果を提供できるかを測定するもので、現実世界での使用に最も近いシナリオをシミュレートしています。
結果として、クローズドソースLMMの中ではGPT-4oが最高のパフォーマンスを発揮し、オープンソースのQwen2-VL-72Bも優れた結果を示しました。特に興味深いのは、提案手法を用いることで、商業的なAI検索エンジンであるPerplexity Proを上回る成果が得られたことです。これにより、MMSEARCH-ENGINEが既存のシステムと比較しても優れたマルチモーダル検索能力を持つことが示されました。
実験の結果はまた、RequeryやRerankの部分でモデルが苦手としている点が浮き彫りになり、特にオープンソースモデルにおいては、これらのタスクでの改善が必要であることが分かりました。一方で、Summarizationタスクに関しては、多くのモデルが比較的高いパフォーマンスを示し、抽出された情報の要約能力が強力であることが確認されました。
結論
この論文の結論は、提案されたMMSEARCH-ENGINEが、現在のマルチモーダル検索において非常に有望であることを実証しています。大規模マルチモーダルモデル(LMMs)を利用することで、テキストだけでなく画像も含めた複雑なクエリに対して効果的に対応できる能力が確認されました。
また、提案手法の欠点として、現在のLMMがRequeryやRerankタスクにおいて十分な精度を持たないことが指摘されています。これらのタスクでの性能向上が今後の課題となっており、さらに改善することで、マルチモーダル検索におけるLMMの性能は飛躍的に向上すると考えられます。
図表の解説

この図は、多分野にわたる質問とその回答を示すもので、MMSearchというシステムの機能を評価する例を提供しています。
図は、主にニュースと知識に関する質問をカテゴリー別に分けて示しています。まず、ニュース関連では「金融」「スポーツ」「科学」「エンターテインメント」「一般」「誤った前提」の6つに分かれています。それぞれのカテゴリーには、具体的な質問例とその回答が示されています。たとえば、「金融」のセクションでは、ある企業の株価に関する質問がされています。
次に、知識に関するセクションでは、「天文学」「自動車」「ファッション」「アート」「建築」「アニメ」の6つに分かれています。この中で、「ファッション」のセクションでは、服のリリース日が問われています。
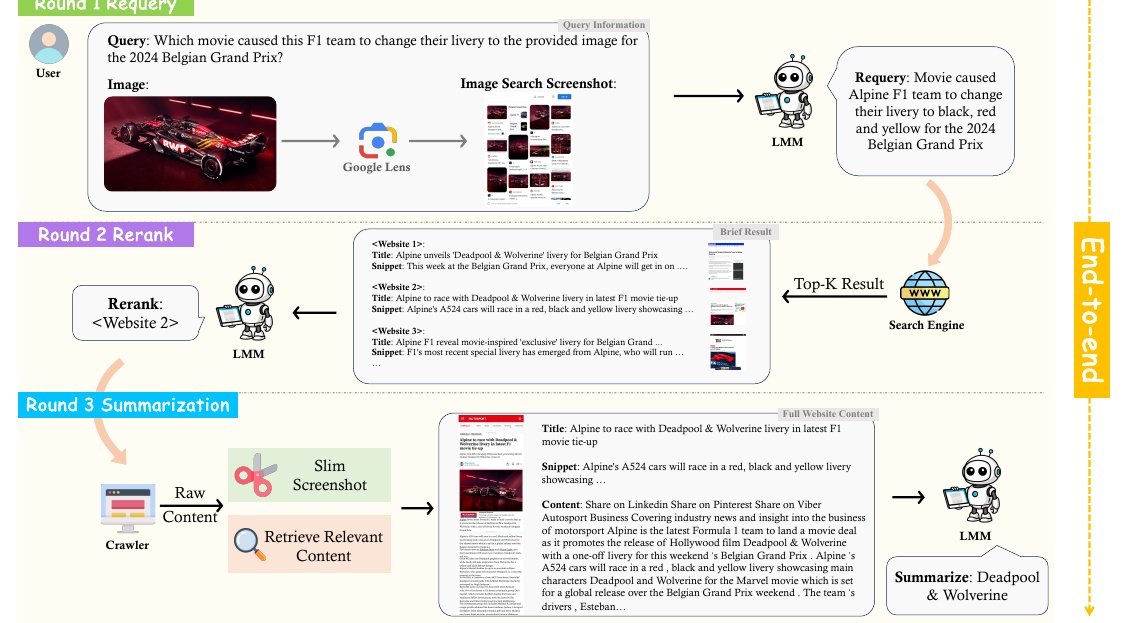
この図は、F1チームのリバリー変更についての情報を検索する手順を示しています。内容は以下の通りです。
まず、ユーザーが「2024年ベルギーグランプリでこの画像に提供されたF1チームのリバリー変更を引き起こした映画は何か?」という質問をします。ユーザーは関連する画像を使用し、その画像はGoogle Lensを通じて検索され、関連情報が取得されます。
次に「Requery(リクエストの再構成)」というステップでは、LMM(大規模マルチモーダルモデル)が画像と取得した情報を基に、検索エンジンで「2024年ベルギーグランプリで黒、赤、黄色にリバリーを変えた映画」という新たな検索クエリを作成します。そして検索エンジンで最も関連性の高いウェブサイトがトップKとしてリストされます。
「Rerank(順位の再評価)」のステップでは、LMMがリストされたウェブサイトから最適な情報を提供するものを選びます。この例では、「Website 2」が選ばれています。
最後に「Summarization(要約)」のステップで、LMMは選ばれたウェブサイトの詳細を解析し、映画「Deadpool & Wolverine」がリバリー変更を引き起こしたと要約します。
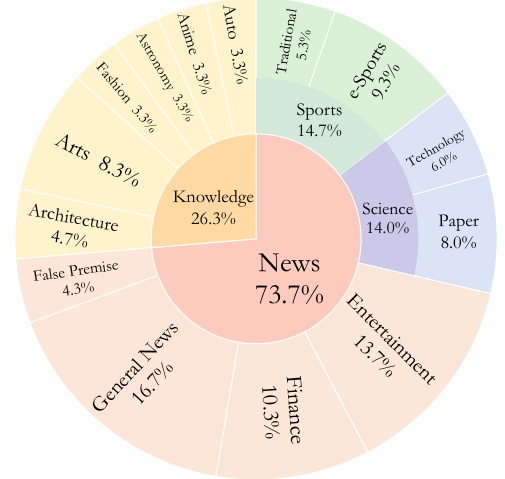
この図は、論文が評価するデータセット「MMSEARCH」のカテゴリとサブカテゴリの割合を示しています。全体の73.7%が「News」カテゴリに属し、26.3%が「Knowledge」カテゴリに該当します。
「News」カテゴリはさらに詳細に分かれており、「General News」が16.7%を占め、「Sports」は14.7%で伝統的なスポーツとeスポーツを含んでいます。「Entertainment」は13.7%を占め、多くの人に関心があるトピックです。加えて、「Finance」が10.3%を占めていることから、経済に関する情報も多く含まれています。「Science」と「Technology」はそれぞれ14.0%と6.0%を占めており、科学技術に関するニュースも豊富です。「Paper」は8.0%で、学術的な情報も含まれています。
「Knowledge」カテゴリでは、「Arts」が8.3%、「Architecture」が4.7%を占め、それぞれ芸術と建築に関する特殊な知識をカバーしています。「False Premise」は4.3%で、誤った前提を含む質問を扱います。「Astronomy」「Anime」「Auto」「Fashion」はそれぞれ3.3%を占め、これらの領域に関する知識を考察します。
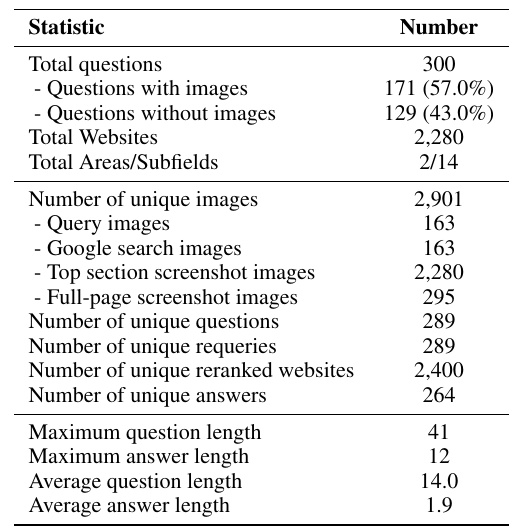
この表は、ある研究におけるデータセットの統計情報を示しています。全体で300の質問が含まれており、そのうち171は画像付き、129はテキストのみの質問です。各質問に関連付けられるウェブサイトの数は2,280にのぼります。また、データセットは14の分野に分けられていますが、主要な分野は2つに絞られています。
ユニークな画像は2,901点あり、その中には問い合わせに使用される163点の画像、Google検索での結果として得られる163点の画像、そしてウェブサイトのトップセクションのスクリーンショットが2,280点含まれています。さらに、ウェブページ全体のスクリーンショットも295点あります。
ユニークな質問数は289で、同じく289のユニークな再クエリが存在します。リランキングされたウェブサイトは2,400点で、ユニークな答えは264通りあります。質問の最大の長さは41語、答えの最大の長さは12語です。質問の平均の長さは14語で、答えの平均の長さは1.9語です。

この図は、論文に関連するデータセットの概要を示しています。まず、質問の総数は300問で、このうち57%が画像付き、43%が画像なしの質問です。ウェブサイトは2,280件使用されています。データは二つの大まかな領域に分けられており、それぞれニュースと知識という14のサブフィールドから成っています。ニュースは73.7%を占めており、具体的には一般ニュース、エンターテインメント、スポーツ、財布、科学技術など多岐にわたります。知識は26.3%を占めています。
画像に関しては、合計2,901のユニークな画像があり、そのうち163はクエリー画像、163はGoogle検索画像です。また、ウェブサイトのトップセクションスクリーンショットが2,280内容、フルページスクリーンショットは295です。ユニークな質問の数は289、ユニークな再クエリー(問合せ)も289で、ユニークな再ランク付けされたウェブサイトの数は2,400です。ユニークな回答は264用意されています。
質問文の最大長は41語、回答の最大長は12文字で、平均的には質問の長さは14.0語、回答の長さは1.9文字です。このデータを基に、さまざまなニュースや知識に関する問題が研究されています。

この図表は、4つの異なるタスク(リクエリ、リランク、サマリ、エンドツーエンド)のそれぞれについて説明しています。具体的には、各タスクに対する入力内容、LMM(Large Multimodal Model)の出力、そして正解(Ground Truth)の対応関係を示しています。
1. リクエリ(Requery):
- 入力: 「クエリ情報」と呼ばれるデータが使用されます。
- LMMの出力: モデルが新たに作り直した「LMMリクエリ」が得られます。
- 正解: 「リクエリ注釈」としてリクエリの正解が示されます。
2. リランク(Rerank):
- 入力: 「クエリ情報」と「簡略結果」が使われます。これによって、どの情報が重要かを判断します。
- LMMの出力: モデルは「LMMリランク」を出力し、最も重要な情報を選び出します。
- 正解: 「リランク注釈」に正しい順位付けが記されています。
3. サマリ(Summarization):
- 入力: 「クエリ情報」と「完全なウェブサイトの内容」が提供されます。
- LMMの出力: モデルが「LMMアンサー」としてクエリに対する要約を行います。
- 正解: 「アンサー注釈」に正確な要約が記されています。
4. エンドツーエンド(End-to-end):
- 入力: 「クエリ情報」が使われ、一連のプロセス(リクエリ、リランク、サマリ)を含む流れを示します。
- LMMの出力: 全プロセスを通して得られた「LMMアンサー」が最終成果物として現れます。
- 正解: エンドツーエンドプロセス全体の結果として「アンサー注釈」が用意されます。
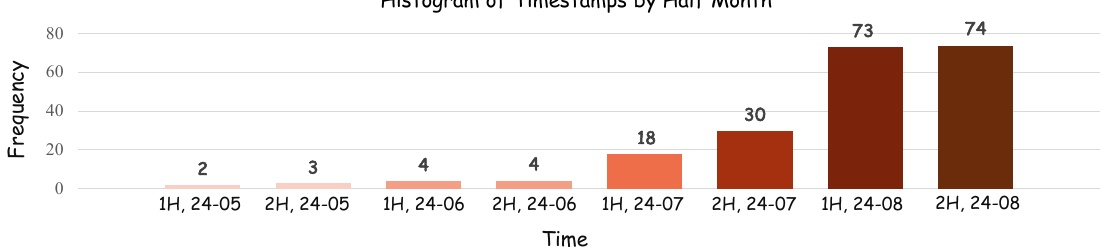
この図は、データの発生時期を半月ごとに区切って頻度を示したヒストグラムです。横軸は時間(年-月)、縦軸は頻度を表しています。図からは、2024年5月から8月までのデータが含まれており、特に8月にデータの頻度が高くなっていることがわかります。
1Hと2Hというラベルは半月の区分を示しており、各期間におけるデータの発生量が視覚的に示されています。特に2024年8月の後半が一番高く、データ収集がこの時期に集中している様子が読み取れます。

この図は、NASAの月面探査計画「VIPER」が中止になった日時を調べるためのプロセスを示しています。図は3つのステップに分かれています。
1. 再クエリ(Task1 Requery):
- 最初の質問は、「この画像で示される月面探査計画は2024年の何日に中止と発表されたか?」というものでした。
- LMM(大規模言語モデル)は、「VIPER was announced to be cancelled」という再クエリを提案しました。これは、正確な情報を得るために質問を改めて構成する段階です。
2. 再ランク(Task2 Rerank):
- 再クエリに基づいて検索エンジンから取得したウェブサイトの候補が示されています。
- 例えば、NASAの公式発表や関連ニュース記事のスニペットが含まれています。
- LMMは「<Website 2>」を最も有用な情報源として選びました。このステップは、どの資料が最も情報を提供してくれるかを判断する段階です。
3. 要約(Task3 Summarization):
- 選ばれたウェブサイトの詳細情報を解析し、最終的な答えを導き出します。
- 図では、「July 17」という答えが得られたことが示されています。この答えは、探査計画が中止された日付を示しています。
このプロセスを通じて、LMMは画像とオンライン情報を用いて正確な情報を抽出する能力を持っていることが分かります。
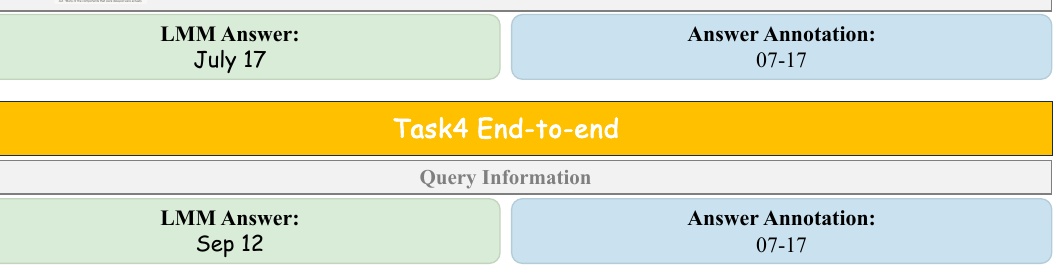
この図は、マルチモーダルモデル(LMM)のエンドツーエンドタスクにおける性能を示しています。図の中には、LMMが7月17日と判定した内容と、答えの正しい注釈としての「07-17」が並んで提示されています。
図の上部にはLMMの回答「July 17」が示され、下部には答えの注釈として「07-17」が提示されています。これらは、モデルが与えられた情報に基づいて正しく答えを導く能力を評価するためのものです。
この情報は、モデルが質問に対してどの程度正確に回答できるかを示しています。したがって、LMMが生成した回答と正しい答えの注釈がどのように比較されるかを見ることで、モデルのパフォーマンスを理解することができます。
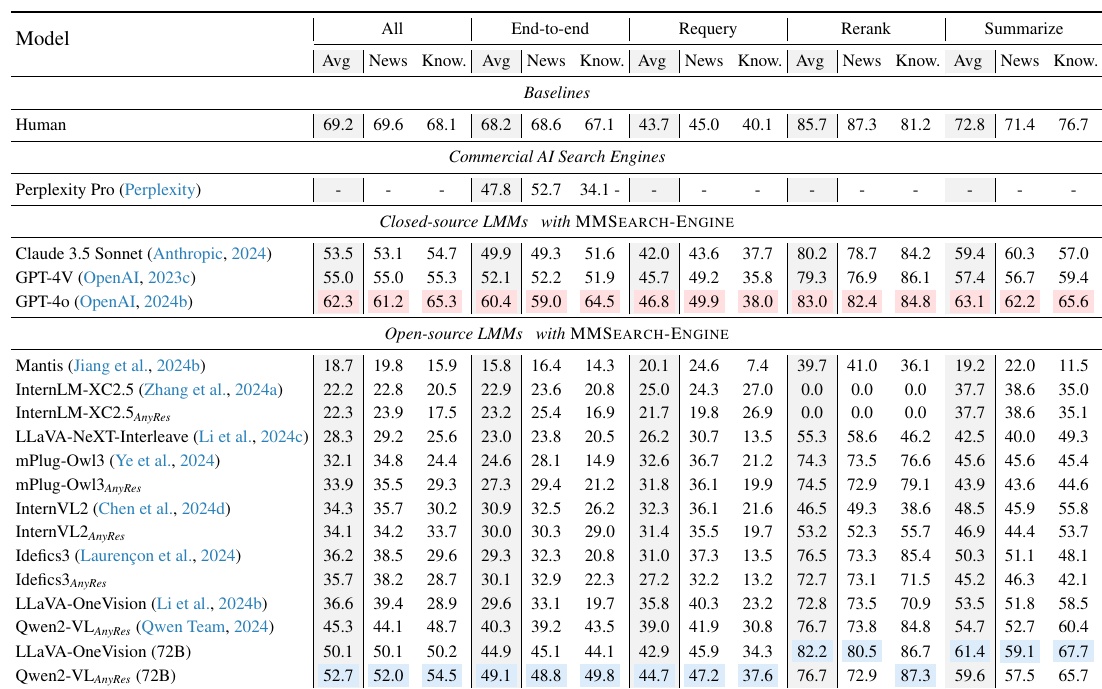
この図表は、異なる大規模マルチモーダルモデル(LMM)が「MMSEARCH-ENGINE」上でどれだけの性能を発揮しているかを示しています。評価は主に4つのタスク、すなわち「End-to-end」「Requery」「Rerank」「Summarize」に分けられています。
- 行と列の構成: 各行は異なるLMMを示し、各列はタスクにおける具体的な評価指標(平均スコア、ニュース領域でのスコア、知識領域でのスコア)を示しています。
- モデルの比較: 「Closed-source LMMs」と「Open-source LMMs」の2つの大きなカテゴリーがあります。「Closed-source LMMs」ではGPT-4oが最も高いスコアを示しています。一方、「Open-source LMMs」ではQwen2-VLが比較的高性能を示しています。
- スコアの分布: 各モデルの性能はタスクごとにかなり異なります。例えば、「End-to-end」タスクでのGPT-4oは64.5のスコアを持ち、このタスクでの最高得点です。また、「Rerank」タスクにおいても高い結果を示しています。
- 人間の基準: 比較の基準として、人間のスコアも示されています。全体的に見て人間のスコアが最も高いですが、いくつかのタスクでは機械が近づいている例もあります。
この図表は、大規模マルチモーダルモデルがどの程度多角的なタスクを実行できるかの指標であり、モデルの改良点や強みを理解するのに役立ちます。

この図は、検索エンジンにおけるモデルのエラーの種類を示しています。左側の円グラフは再検索処理におけるエラーの種類を示しており、右側の円グラフは要約処理におけるエラーの種類を示しています。
再検索エラーの種類:
- Irrelevant(関係性のない):27.6%の割合で、再検索のクエリが不適切であることを示しています。
- Lacking Specificity(特定の情報が不足):24.1%のエラーがクエリの詳細不足が原因です。
- Inefficient Query(非効率的なクエリ):20.7%で、サーチエンジン用に最適化されていないクエリが原因です。
- Excluding Image Search Results(画像検索結果が考慮されていない):こちらも20.7%で、クエリに画像情報が欠けています。
- No Change(変更なし):6.9%で、クエリがそのまま使用されています。
要約エラーの種類:
- Text Reasoning Error(テキスト推論エラー):53.0%で、主にテキストからの推論に失敗しています。
- Informal(形式不適合):24.2%で、出力がフォーマットに適していないことを示します。
- Image-text Aggregation Error(画像とテキストの統合エラー):10.6%で、画像情報とテキスト情報を適切に統合できていません。
- Image Reasoning Error(画像推論エラー):9.1%で、画像からの推論に問題があります。
- Hallucination(幻覚):3.0%で、現実に基づかない情報が含まれています。
この図は、特にユーザーの質問に対するモデルの応答生成プロセスにおける特定の課題を浮き彫りにしています。
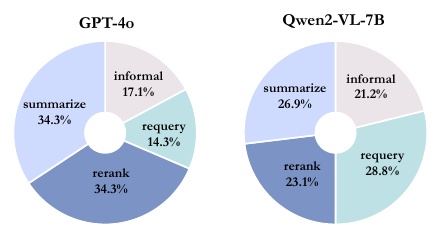
この図は、2つの異なるモデルGPT-4oとQwen2-VL-7Bのエラーの内訳を示しています。各円グラフは、それぞれのモデルがどのような種類のエラーをどれだけの割合で犯したかを視覚的に表しています。
左側はGPT-4oのエラー内訳です。大きな割合を占めるのが「summarize(要約)」と「rerank(再ランク付け)」のエラーで、それぞれ34.3%を占めています。「informal(形式不備)」のエラーが17.1%、そして「requery(再検索)」のエラーが14.3%となっています。これは、特に要約と再ランク付けの作業で改善の余地があることを示唆しています。
右側はQwen2-VL-7Bのエラー内訳を示しており、「requery」のエラーが最も多く、28.8%を占めています。「summarize」のエラーは26.9%、「informal」のエラーは21.2%、「rerank」は23.1%です。このモデルの場合、再検索に関連するエラーが特に多いことがわかります。若干の構造的な違いはありますが、どちらのモデルでも複数の作業ステップでエラーが発生していることがわかります。
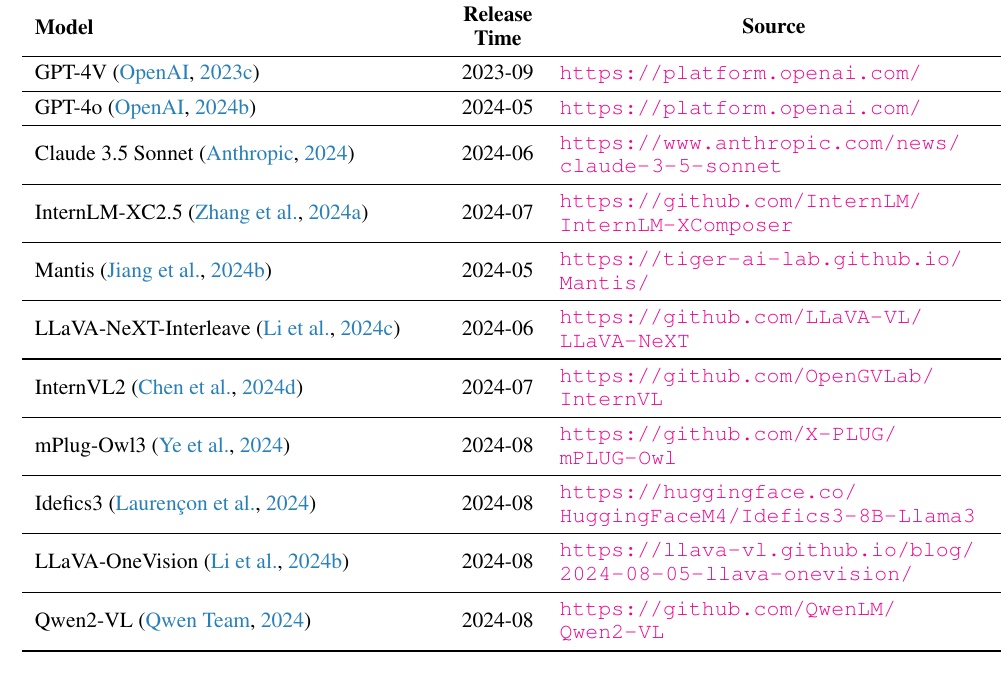
この表は、複数の大規模マルチモーダルモデル(LMM)の情報を整理したものです。各モデルの名称、リリース時期、そしてソースへのリンクが示されています。具体的には、OpenAIやAnthropic、複数のGitHubリポジトリなどの出典が並んでおり、最新の研究開発の状況を把握するのに役立ちます。
表中の左側には、モデル名がリストアップされていて、それぞれの開発者や関連する論文へのリンクが含まれています。このリンクは、さらに詳細な情報を得たい場合に直接アクセスできるようになっています。また、右側の列にはリリース日が記されており、各モデルの公開された時期を比較することができます。

この図は、「LPL 2024年夏シーズンにおいて、Group Ascendにはいくつのチームが所属していたか」という質問に対する回答を示しています。答えは「9チーム」です。
図の上部には、質問内容とその答えが表示されており、スポーツニュースの一環としての情報であることが示されています。
次に、図の中央部分には、モデルが検索エンジンに対して行った3つの異なるクエリの例が示されています。ここでは、GPT-4o、Qwen-VL、LLaVA-OneVisionのそれぞれが類似したクエリを生成し、情報を探そうとしています。
その下には、「Brief Results」セクションがあり、さまざまなウェブサイトから取得した情報のタイトルとスニペットがリストアップされています。これは、モデルがどのようにして最も関連性の高い結果を選別するかの例を示しています。
最後に、図の一番下では、GPT-4oが選んだウェブサイトが示されており、これは「Wikipedia」のページであることが示されています。

この図は、異なる検索エンジンが同じクエリに対するウェブサイトの検索結果をどのように表示するかを示しています。
まず、上部の「Round2 Rerank」と書かれたセクションでは、特定のクエリに基づいて取得された複数のウェブサイトの要約が表示されています。ここには、各ウェブサイトのタイトルとスニペット(簡単な説明文)がリストアップされ、それぞれのコンテンツの概要を示しています。たとえば、サイトは「LPL 2024 Summer - Group Stage」などに関する情報を含んでおり、リーグのグループ分けや試合の形式について述べられています。
図の中央部分は、「Qwen2-VL」が選んだウェブサイトの例を示しています。このモデルは、検索結果を評価し、最適な情報を含むサイトを選び出しています。
下部の「LLaVA-OneVision Brief Results」では、別の検索エンジンが生成した同じクエリに対する結果を提示しています。
この図は、複数のウェブサイトから集めた情報を示しています。各ウェブサイトには、2024年のLPL(League of Legendsプロリーグ)サマーシーズンに関する情報が書かれています。具体的には、ウェブサイトは試合結果やチームの順位、視聴関連の情報を扱っており、LPLの試合フォーマットや参加チームについての詳細も含まれています。
図中では、複数のサイトのサマリーや見出しが一覧で表示され、例えば「LPL 2024 Summer - Liquipedia League of Legends Wiki」などが挙げられています。それぞれのサイトは、LPLサマーシーズンの異なる側面を取り上げていますが、共通してチームや試合の構造、最新の試合結果について説明しています。
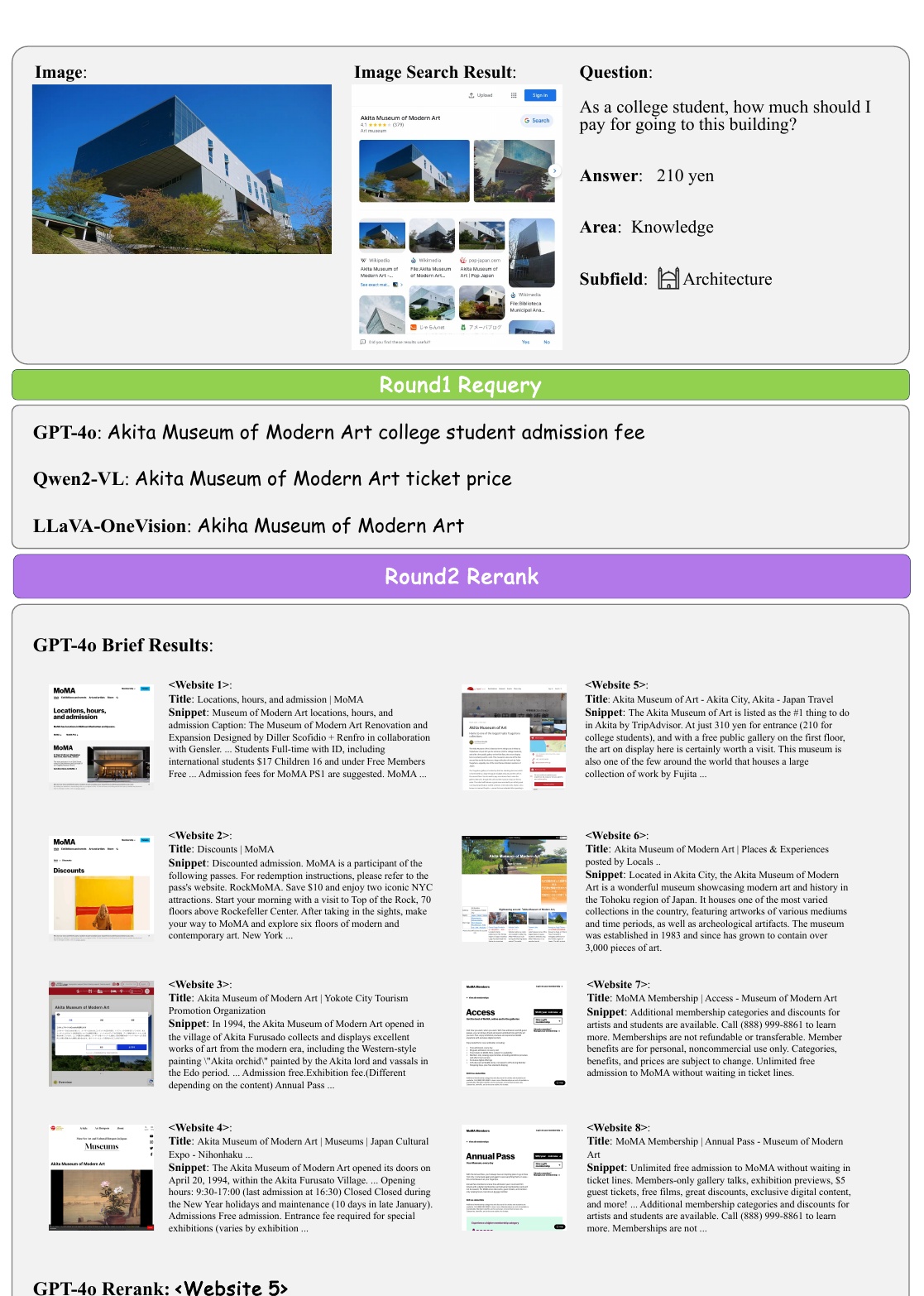
この図は、ある大学生が秋田近代美術館への入館費を調べる過程を示しています。画像検索結果を用いて、適切な情報を探すための手順を説明しています。
最初に、秋田近代美術館の外観を示す画像と、その画像検索結果が示されています。次に、「大学生はこの建物に入るのにいくら支払うべきか?」という質問が提示されており、この建物の入館料について知識を得たいという意図がわかります。
画像検索結果を基に、AIモデルは異なる質問を検索エンジンに入力しています。「GPT-4o」は「大学生の入館料」、「Qwen2-VL」は「チケットの価格」など、それぞれ多少異なるアプローチで情報を探しています。
最終的に、「GPT-4o」は「ウェブサイト5」を最も関連性が高いと判断し、その内容から「210円」が正しい入館料として提示されています。

この画像は建物の外観を示しており、検索結果から「Akita Museum of Modern Art」という美術館であることがわかります。問題では、大学生としてこの建物に入るための費用を尋ねられており、答えは「210円」です。この情報は、知識の中でも「建築」という分野に関連しています。展示されている情報は、画像とその検索結果を活用して具体的な場所と費用を特定することを目的としています。
この図は、論文の「ラウンド2のリランク」プロセスにおける検索結果の選択を示しています。具体的には、Qwen2-VLとLLaVA-OneVisionという2つの異なるモデルが、与えられた情報から適切なウェブサイトを選び出す場面を視覚化しています。
まず、Qwen2-VLの結果から見てみましょう。このモデルは、アキタ現代美術館(Akita Museum of Modern Art)に関する情報を元にしています。検索結果の中、Qwen2-VLは「Website 3」を選んでいます。このウェブサイトは、美術館の開館時間や具体的な住所情報を提供しており、さらに旅行ガイドや近隣のオススメ情報も含まれています。
次に、LLaVA-OneVisionの結果についてです。このモデルもアキタ現代美術館に関する情報を扱っており、提供されたウェブサイトの中から「Website 1」を選択しています。このサイトは、ウィキペディアの情報を元にしており、一般情報や所在地情報を持っています。
どちらのモデルも、自分が与えられた情報から、最も役立つと考えるウェブサイトを選び出しています。

この図は、論文内で「Round2 Rerank」と題された部分で、Qwen2-VLというモデルが再ランキングを行う際に使用したWebサイトの簡単な結果を示しています。図の目的は、どのWebサイトが質問に対して最も有用な情報を提供するかを評価することです。
図には8つのウェブサイトのタイトルとスニペット(簡単な説明)が表示されています。これらのスニペットには、それぞれのサイトが何について書かれているかの概観が含まれています。この過程を通じて、モデルがどのサイトを選ぶかを決定し、その選択が次の情報収集や回答生成にどう影響するかを示しています。
詳しくは、Qwen2-VLモデルが<Website 3>を選択したことが示されています。このウェブサイトは秋田近代美術館に関する詳細な情報を提供しており、特に訪問者が知りたい展示内容や入場料についての情報が含まれています。これによって、モデルが質問に対して最も適切な情報源を特定し、その情報に基づいて回答を生成する手助けをしています。



この記事に関するカテゴリー





