
TaPA:LLMを使用したロボットの行動生成エージェント
3つの要点
✔️ LLMとvisual perception modelsによる、場面に存在するオブジェクトに従って実行可能なプランを生成するTAsk Planing Agent (TaPA)
✔️ 現実での複雑なタスクに対応するために、open-vocabulary object検出器の一般化を行った
✔️ ChatGPT3.5と比較し、ロボットの行動ステップの平均成功率が高まった
Embodied Task Planning with Large Language Models
written by Zhenyu Wu, Ziwei Wang, Xiuwei Xu, Jiwen Lu, Haibin Yan
(Submitted on 4 Jul 2023)
Comments: Project Page
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Robotics (cs.RO)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
最近、ChatGPTの登場と共に、自然言語処理の名前を耳にする機会が増えたのではないでしょうか。自然言語処理は、ChatGPTのようなタスクだけでなく、ロボットへの活用が求められています。例えば、家事代行サービスや医療、農業といった分野へロボットを導入する際に、それらの複雑なタスクを達成する必要があります。これらが抱える問題として、分野によりロボットが代替する行動や自律走行のシチュエーションが違うことが挙げられます。また、分野ごとやシチュエーションを予想し、ロボットを訓練することは実質、不可能です。
しかしながら、昨今の大規模言語モデル(LLM)の進歩により、膨大なデータから豊富な"知識"を獲得することが出来るようになりました。これにより、ロボットは、人間からの(自然言語による)命令に対し、様々なシチュエーションにあった行動生成を行える可能性があります。
課題
しかし、LLMを活用したロボットの行動生成にも問題点があります。それは、LLMが周辺の場面を認識することが出来ないということです。また、ロボットの行動生成には、存在しない物体との相互作用が要求されるため、実行不可能な行動を生成する可能性が挙げられます。
例えば、「ワインをくれ」という人間の命令が与えられたとき、GPT-3.5が生成する行動ステップは「ワインをボトルからグラスに注ぐ」です。しかし、現実では、グラスの代わりにマグカップしか存在しない可能性があり、実行可能な行動は「ボトルからマグカップにワインを注ぐ」となるはずです。そのため、LLMによって生成されたタスク計画を現実世界で実行することは、複雑なタスクの達成のため、具体化されたAgentを構築するために必要になります。
※ここでのAgentは、LLMがユーザの要求に沿って手段・順番を選択し実行する機能のことです。
本記事で紹介するTAsk Planing Agent (TaPA)は、LLMとvisual perception modelsを組み合わせることにより、場面に存在するオブジェクトに従って実行可能なプランを生成するAgentです。
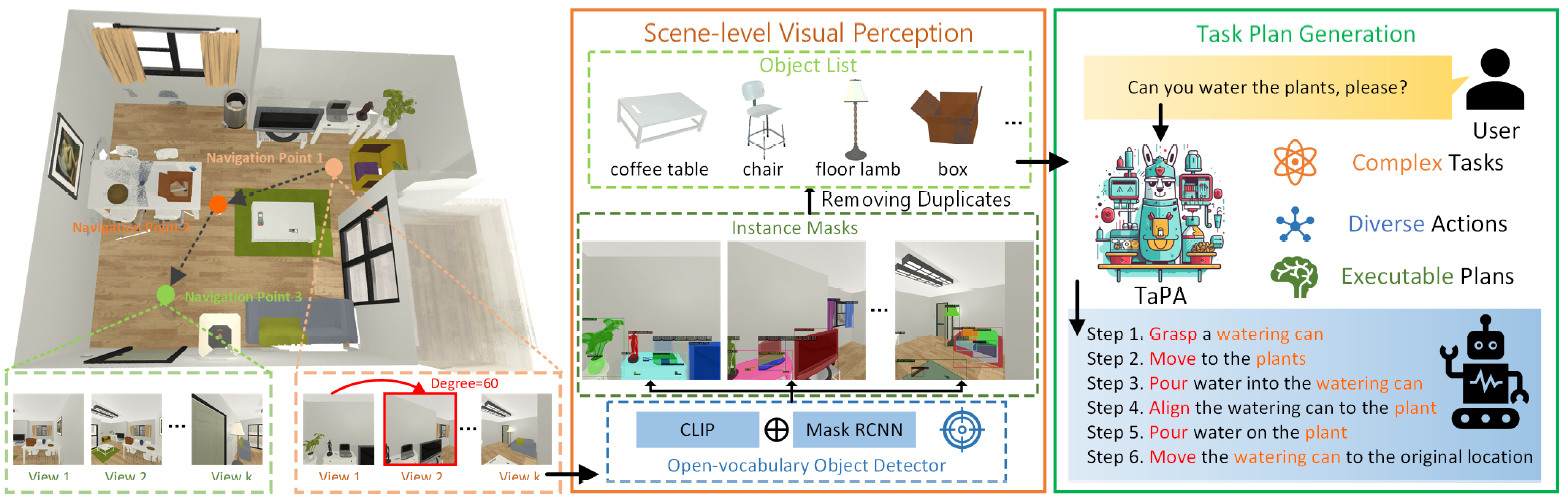
TaPA:TAsk Planing Agent
TAsk Planing Agent(以下、TaPA)は、LLMとvisual perception modelsを組み合わせることにより、場面に存在するオブジェクトに従って実行可能なプランを生成するAgentです。
具体的には、まず、屋内での場面、指示、行動計画の3つを含むマルチモーダルデータセットを構築します。次に、GPT-3.5で生成されたプロンプトと場面に存在するオブジェクトのリストを提供することで、多数の指示と対応する行動計画を生成します。
生成されたデータは、事前に訓練されたLLMの現実への実行計画のチューニングに活用されます。推論中、達成可能な異なる場所で収集されたマルチビューRGB画像にオープン語彙オブジェクト検出器を拡張することにより、場面内のオブジェクトを発見します。
TaPAは以下のように、大きく二つのアプローチで実現されています。
Data Generation of Embodied Task Planning
ここでは、TaPAタスクプランナーのチューニングに活用するマルチモーダル命令データセットの構築について説明します。
具体化された3D場面Xsが与えられたとき、我々はすべてのオブジェクトのクラス名を場面の表現として直接利用します。Xl=[テーブル、椅子、キーボード、...]のように、LLMに場面情報を提供するために、重複する名前はすべて取り除かれます。
上記の場面情報に基づいて、具体化されたタスクプランのデータセットに従うマルチモーダル命令を生成するLFREDベンチマークのアプローチは、対応するstep-by-stepのアクションを含む一連の命令を人為的に設計することです。しかし、人為的な設計では、トイレの片付けやサンドイッチ作りなどの現実的なサービスロボットに実用的で複雑なタスクプランを生成するためには、高いアノテーションコストを必要とします。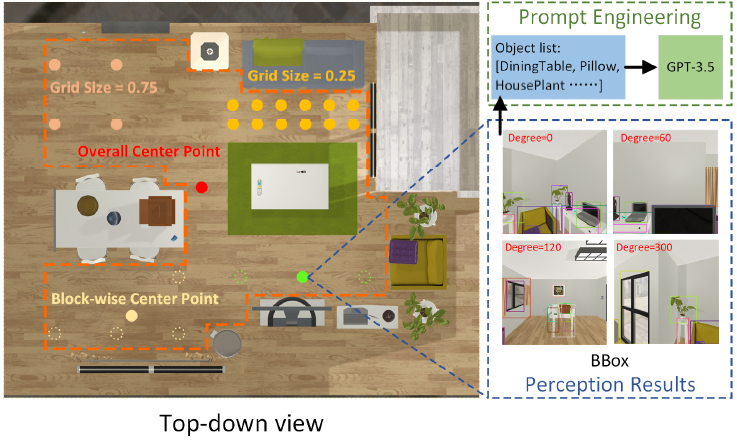
そこで、TaPAでは、提示された場面表現と、Agentのチューニングのため大規模なマルチモーダルデータセットを生成するために設計されたプロンプトと共にGPT-3.5を活用します。
GPT-3.5では、与えられた3次元場面に対して、大規模で複雑な命令Xqと実行可能な対応計画Xaを効率的に生成するために、物体名リストXlに基づいてデータを自動合成する、具現化タスク計画のシナリオをシミュレートするプロンプトを設計しました。
具体的には、このプロンプトは、サービスロボットと人間との会話をデザインし、実行可能な指示と行動を生成することで、具体化した環境におけるロボットの探索をシミュレートし、人間からの要求を提供します。生成される指示は、リクエスト、コマンド、クエリなど多様であり、明示的に実行可能なアクションを持つ指示のみがデータセットに追加されます。データセット生成のためのプロンプトで利用されるオブジェクトリストについては、場面内に存在するインスタンスのgroundtruthラベルを利用します。
下図に、場面のオブジェクト名リスト、命令、実行可能なアクションステップを含む生成サンプルの例を示します。具体化されたタスク計画では、Agentは、全ての対話オブジェクトを含むビジュアル場面に、真実のオブジェクトリスト無しでしかアクセスできません。

そのため、各サンプルに対してX = (Xv,Xq,Xa)を定義することで、マルチモーダルなデータセットを構築します。タスクプランナーの学習では、不正確な視覚認識の影響を避けるため、各場面のgroundtruthオブジェクトリストを利用します。推論では、拡張されたオープン語彙オブジェクト検出器により、場面に存在する全てのオブジェクトのリストを予測します。
また、AI2-THORシミュレータをAgentの具体的環境として採用し、80場面を訓練用に、20場面を評価用に分割しました。効果的なタスクプランナーの微調整のために、訓練サンプルの指示と行動ステップのスケールと多様性を拡大するために、groundtruthオブジェクトリストを変更することにより、元の80の訓練場面を6400の訓練場面に拡張します。
各場面について、まず、同じ部屋タイプの全ての部屋を列挙することで、このタイプの場面に出現する可能性のあるオブジェクトのリストを取得します。次に、存在するオブジェクトを、同じ部屋タイプに存在する可能性があるため、観測されていない他のオブジェクトでランダムに置き換えます。
Grounding Task Plans to Surrounding Scenes
ここでは、画像収集とオープンボキャブラリー検出による場面の具体的タスクプランの根拠付けの詳細を説明します。
具体化されたタスクプランを実現可能な現実に適合させるためには、インスタンス欠損や誤検出を発生させることなく、場面内の物体リストを正確に取得する必要です。周辺の場面を3Dで探索するため、いくつかの画像収集のための戦略を設計します。場所の選択基準には、トラバーサル位置、ランダム位置、全体中心点、ブロック単位の中心点が含まれます。Agentはカメラを回転させ、それぞれの場所選択基準に対してマルチビュー画像を取得します。
画像収集のため戦略Sを以下の数式で表されます。
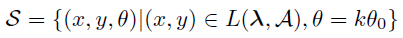
(x,y,θ):位置とカメラの向き、L(λ,A):ハイパーパラメータλによる位置の選択基準
θ0:カメラ回転の単位角度、k:異なる場面の方向を定めるため整数
すべての位置選択基準に共通するハイパーパラメータはグリッド辺の長さで、達成可能領域をグリッドに分割します。
トラバーサル位置はRGB画像の収集のため全てのグリッド点を選択します。全体の中心点は、ハイパーパラメータなしで場面全体の中心を表します。ブロック単位の中心点は、場面内の各分割の中心を選択することで、きめ細かい視覚情報を効率的に取得することを目的としています。
クラスタリング法は、場面全体をいくつかのサブ領域に分割することで、知覚性能を向上させることができるため、K-meansクラスタリング法を用います。また、各場面に対して最適なクラスタ数を選択するために、クラスタ内二乗誤差和(WCSS)原理を採用します。
さらに、訓練された検出器にはない新しいオブジェクトが場面に現れることを想定すると、オブジェクトリストの取得が必要となるます。そのため、オープンボキャブラリオブジェクト検出器を一般化します。さらに、Agentは、場面に存在する物体を発見のため、異なる場所でのRGB画像を収集します。
予測オブジェクトリストXlは、以下の数式で表されます。
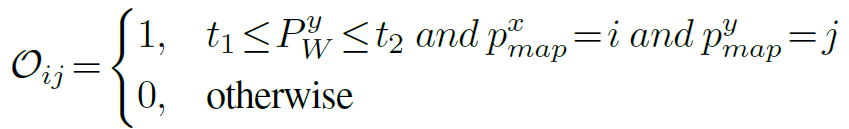
予測オブジェクトリストは、マルチビュー画像の検出結果から重複するオブジェクト名を除去し取得します。ここで、Rdは重複するオブジェクト名を削除する操作で、D(Ii)は場面内で収集されたi番目のRGB画像について検出されたオブジェクト名を表します。
この二つのアプローチにより、場面に存在するオブジェクトに未知のオブジェクトを予測しながら実行可能なプランを生成するAgentを実現しています。
実験
実験では、60 個の検証サンプルを用いて,TaPA 手法と,LLaMA や GPT-3.5 を含む最先端の LLM,LLaMA を含む LMM を比較しました。異なる手法から生成された行動ステップの成功率を以下の表に示します。

TaPAは、キッチン、リビング、ベッドルーム、バスルームを含む4つの場面すべてにおいて、すべての大規模モデルの中で最適な性能を達成しました。また、TaPAの平均成功率は、GPT-3.5よりも6.38%高いです。
また、キッチンでの場面のAgentは通常、より多くのステップで複雑な調理指示を扱うため、現在の大型モデルの性能は他の部屋のタイプよりも低です。一方、LLaVAの性能の低さは、視覚的質問応答タスクにおいて、全体的な場面情報が単一の画像で表現できず、不十分な場面情報がタスク計画の成功率の低さに繋がることが示唆されます。

さらに、上図に、与えられた場面に対して、異なる大きなモデルから生成されたアクションステップの例を示します。場面はトップダウンビューで示され、参考のためにグランドトゥルースのオブジェクトリストも提供します。LLaMAからの内容は人間の指示とは無関係であり、LLaVAは存在しないオブジェクトのために実行不可能な計画を提供します。また、GPT-3.5は、具体化されたタスク計画を得ることができますが、TaPAのアクションステップは、より完全で、より人間の価値観に近づきました。
おわりに
最近では、自然言語処理によるロボットの行動生成の研究が盛んになってきました。人が命令することでロボットが行動するような技術がさらに進めば、自動運転技術で問題である天候などの環境変化に対応できるロボットが生まれるかもしれません。
また、今後、今回取り上げた研究のようにインタラクティブな技術が発展すれば、人とロボットの安全な協働が実現でき、人の働き方も変化していくと予想します。






この記事に関するカテゴリー





