
LLMにヒントを与えることで推論能力を向上させるアプローチが登場!
3つの要点
✔️ 人間の思考プロセスに従い、過去の回答をヒントとして活用するプロンプティング手法であるProgressive-Hint Prompting(PHP)を提案
✔️ 様々なデータセットとプロンプトを用いた比較実験により、その有効性を実証
✔️ モデルやプロンプトが強力になるほど、PHPの性能が向上することが分かった
Progressive-Hint Prompting Improves Reasoning in Large Language Models
written by Chuanyang Zheng, Zhengying Liu, Enze Xie, Zhenguo Li, Yu Li
(Submitted on 19 Apr 2023 (v1), last revised 10 Aug 2023 (this version, v5))
Comments: Published on arxiv.
Subjects: Computation and Language (cs.CL); Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
大規模言語モデル(LLM)は、様々な自然言語処理タスクにおいて顕著な性能を発揮している一方で、その推論能力はプロンプトの設計に大きく依存しています。
近年の研究で登場したChain-of-Thought(CoT)やself-consistencyは、こうした推論能力を高める重要な手法として注目を浴びていますが、これらの方法ではLLMが生成した回答を十分に利用することができていないという問題点がありました。
一方既存研究において、人間の思考プロセスと同じように、LLMの出力を活用して推論能力を反復的に改良する手法の有効性は検討されてきませんでした。
本稿では、こうした背景から人間の思考プロセスに従い、過去の回答をヒントとして活用し、問題を再評価した後に正解を導き出す新たなプロンプティング手法であるProgressive-Hint Prompting(PHP)を提案し、様々なLLMを用いた包括的な実験によりその有効性を実証した論文について解説します。
Progressive-Hint Prompting(PHP)
人間の思考プロセスの特徴の1つとして、1度回答を考えるだけでなく、自分の回答を再確認する能力が挙げられます。
本論文では、言語モデルにおいて過去の回答を順次使用することで、このプロセスをシミュレートする新たなプロンプティング手法であるProgressive-Hint Prompting(PHP)を提案しています。
PHPは、過去に生成された回答をヒントとして利用することで、ユーザーとLLM間の自動的な複数回の対話を可能にし、正解への段階的な誘導を行うプロンプティング手法となっています。
PHPフレームワークの概要を下図に示します。(紫色の枠=LLMの入力、黄色の枠=LLMの出力)
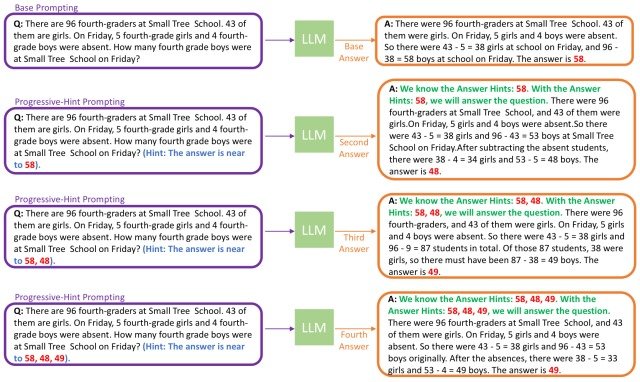
PHPフレームワークは生成された回答と質問を組み合わせてダブルチェックを行う構造になっており、2つの段階に別れています。
第1段階(Base Prompting)では、現在の質問とCoTのような基本プロンプトを連結させたものをLLMに渡すことで、基本的な回答を生成します。
第2段階(Progressive-Hint Prompting)では、後述するPHP-CoTを介して、与えられたヒント(図の赤字)を考慮した回答を生成します。
その後はモデルが与えられたヒントを考慮した回答の生成を繰り返し、ヒントとモデルが生成した回答が一致した時点でやり取りを終了します。(不一致の度にその回答がヒントに追加されていきます)
次に、与えられたCoTプロンプトに対して、本論文で提案されているPHP-CoTプロンプトを生成するプロセスを示します。(青:CoTプロンプトとPHP-CoTプロンプトの違い、赤:設計されたプロンプト内のヒント)

本プロセスは、質問部分での回答の近さを示すフレーズと、回答部分でのヒントを復唱するフレーズの2つのセンテンス構造から構成されています。
CoTプロンプトからPHP-CoTプロンプトを作成する場合、まず最初の質問の後に「The answer is near to A(回答はAに近い)」というフレーズを追加します。(ここでAは回答の候補を表します)
次に、回答の候補の冒頭文に「We know the Answer Hints: A. With the Answer Hints:A, we will answer the question.(私たちはAという回答のヒントを知っています。回答のヒントAを使って、私たちは質問に答えます。)」というフレーズを追加し、LLMに回答のヒントを与えます。
与えるヒントは様々な状況を想定すべきであり、本プロンプトの設計では以下の2つの状況を考慮しています。
- ヒントが正解と同じ場合:ヒントが正しくてもモデルが正解を導き出せるようにするため
- ヒントが正解と同じではない場合:モデルが不正解から正解を導き出せるようにするため
この設計により、PHPは人間の思考プロセスに従い、過去の回答をヒントとして活用し、問題を再評価した後に正解を導き出すことが可能となっています。
Experiments
本論文では、PHPの推論能力を評価するために、7つのデータセット(AddSub・MultiArith・SingleEQ・SVAMP・GSM8K・AQuA・MATH)と4つのモデル(text-davince-002・text-davince-003・GPT-3.5-Turbo・GPT-4)を用いた包括的な比較実験を行いました。
加えて、Standard(通常のプロンプト)・CoT・Complex CoT(プロンプトの複雑さを強調し、最も複雑な質問と回答を選択するCoT)の3つのプロンプトを使用し、それぞれの性能の比較を行いました。
実験結果を下図に示します。
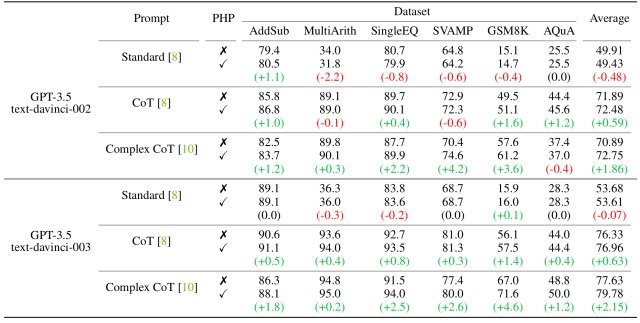
本実験結果で注目すべき点は、モデルとプロンプトが強力であるほどに、PHPは性能を向上させている点です。
モデルに関しては、CoT Promptを用いた検証した際に、text-davince-002はヒントを追加した後に性能が低下する場面が見られるのに対して、text-davince-003に置き換えた際には性能が一貫して大きく改善しています。
同様に、AQuAデータセットにPHP-Complex CoTを使用した際に、text-davince-002では0.4%性能が低下しましたが、text-davince-003では1.2%向上する結果となりました。
本結果より、PHPは強力なモデルに適用された場合に最も効果的であることが示されました。
プロンプトに関しては、標準的なStandard PromptではPHPを組み込むことで小幅な改善が見られましたが、CoT PromptとComplex CoT Promptでは大幅な性能向上が確認できました。
加えて、最も強力なプロンプトであるComplex CoT Promptが、他の2つのプロンプトと比較して最も大幅な性能の向上を示しています。
本結果より、優れたプロンプトがPHPの有効性を高めることが示されました。
さらに本論文では、モデルとプロンプトごとのInteraction Number(=決定的な回答を得るまでにエージェントがLLMを参照する必要のある回数)の変化についても分析しました。
下図がその結果になります。
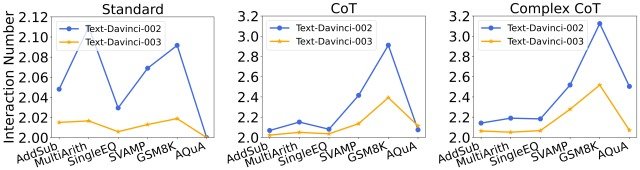
この結果から、以下のことがわかりました。
- 同じプロンプトが与えられた場合、text-davince-003のインタラクション数はtext-davince-002よりも低い
- これはtext-davince-003の精度が高いため、基本の回答とそれに続く回答が正しい確率が高くなり、最終的な正解を得るために必要なInteraction Numberが少なくなるからである
- 同じモデルを使用する場合、プロンプトが強力になるにつれてInteraction Numberは増加する
- これは、プロンプトが強力になるとLLMがより優れた推論能力を発揮し、ヒントを活用して不正解から抜け出すことができるようになり、最終的に正解に到達するために必要なInteraction Numberが多くなるからである
本分析より、より強力なモデルはInteraction Numberを減少させ、より強力なプロンプトはInteraction Numberを増加させることが明らかになりました。
まとめ
いかがだったでしょうか。今回は、人間の思考プロセスに従い、過去の回答をヒントとして活用し、問題を再評価した後に正解を導き出す新たなプロンプティング手法であるProgressive-Hint Prompting(PHP)を提案し、様々なLLMを用いた包括的な実験によりその有効性を実証した論文について解説しました。
本実験にて、PHPは様々なデータセットにてその有効性を実証し、より強力なモデルとプロンプトを使用することでさらにその性能を向上させることが確認されました。
一方で、現状PHPはChain-of-Thoughtなどの他の技術と同様に、人間の手作業によって作成されたものであるため、実装において非効率であるという課題も残されています。
筆者はこの課題を解決するために、今後の研究でAuto Progressive Hintを設計し実装の効率を向上させることを目指していると述べているため、今後の進展が楽しみです。
今回紹介したPHPフレームワークや実験結果の詳細は本論文に載っていますので、興味がある方は参照してみてください。



この記事に関するカテゴリー




