
プロンプトを高性能に最適化するPrompt Tuningとは?
3つの要点
✔️ 凍結した汎用LLMのPrompt部分のみを学習するPrompt Tuningを提案
✔️ Fine-tuningに近い精度を叩き出した
✔️ 大幅なパラメータ削減を可能にする
The Power of Scale for Parameter-Efficient Prompt Tuning
written by Brian Lester, Rami Al-Rfou, Noah Constant
(Submitted on 18 Apr 2021 (v1), last revised 2 Sep 2021 (this version, v2))
Comments: Accepted to EMNLP 2021
Subjects: Computation and Language (cs.CL)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
本記事では、LLMのプロンプト技術の一つである「Prompt Tuning」の研究についてご紹介します。
GPT-4やT5などの近年の高精度LLMは、100億を超えるほどのパラメータ数を持ちます。そのように巨大化することで、様々なタスクを汎用的に解くことが可能になりました。
それに伴い、そのような巨大なLLMを使って、特定の分野のタスクに特化させる取り組みが、盛んに行なわれるようになりました。例えば、医療分野に特化したLLMや、教育分野に特化したLLMなど。このように各分野に特化させるために、事前学習済みのLLMに対して、各分野に特有のデータを追加で学習させるという方法が主流になっています。
この方法は追加学習と呼ばれ、以下の手法が代表的です。
- Model Tuning(Fine-tuning)
- Prompt Design(Prompt Enginnering)
その際、「いかに低コストで追加学習するか」といった課題が、たびたび議論されてきたのも事実です。というのも、やはり何千億ものパラメータを持つLLMの学習となると、かなりの計算コストがかかるため、大企業並みの計算リソースを導入しない限り不可能です。
そのような計算コストの課題を解決するために、本論文では「Prompt Tuning」という手法が提案されたのです。
Model Tuning(Fine-tuning)とは?
そもそもModel Tuningとは、LLMを各タスクに特化させるために、事前学習済みモデルの最終層に、タスクに合わせた層を追加し、モデル全体または一部のパラメータを更新する手法です。その際に、解きたいタスクに応じた大量のデータが必要になり、これを事前学習済みモデルに学習させる必要があります。
こうすることで、汎用的なLLMを各タスクに特化させ、その分野における精度を上げられるのです。
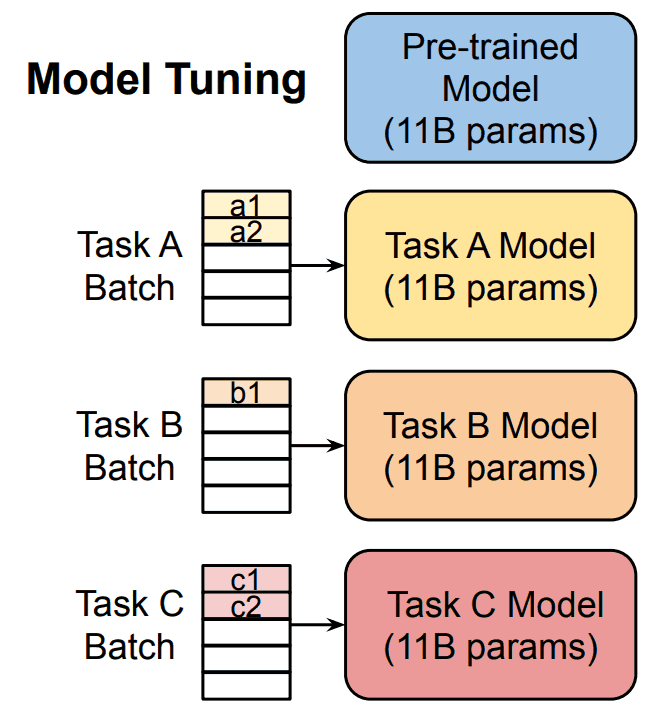
Model Tuning(Fine-tuning)の問題点
しかし、先ほども述べた通り、何千億ものパラメータを持つLLMの学習には、莫大な計算リソースが必要になります。それに加えて、各タスクに特化させたLLMを何個も作るのは、リソースの観点から見ても現実的ではありません。
Prompt Design(Prompt Enginnering)とは?
ChatGPTが話題に上がってから、Promptという言葉もでてきました。このPromptとは、一言でいうと「LLMに与える指示文」のことで、主に以下の2種類があります。
- ハードプロンプト
- ソフトプロンプト
Promptという言葉と同時に、Prompt Design(Prompt Enginnering)という言葉もよく使われるようになりました。これは、人間の手でPromptを適切に設計し、LLMを追加学習することなく、精度をあげようとする手法です。
この手法は、ハードプロンプトに当たり、Few-shotやCoTなど様々なテクニックが発案されてきました。
Prompt Design(Prompt Enginnering)の問題点
このPrompt Designは、比較的低コストで済みます。しかし、これらのハードプロンプトの問題点として、本研究の著者らは以下の問題点を指摘しています。
- プロンプト設計者の技量が必要
- Model Tuningに比べ、はるかに精度が低い
特に、精度の低さに関しては、以下の図で根拠が示されています。
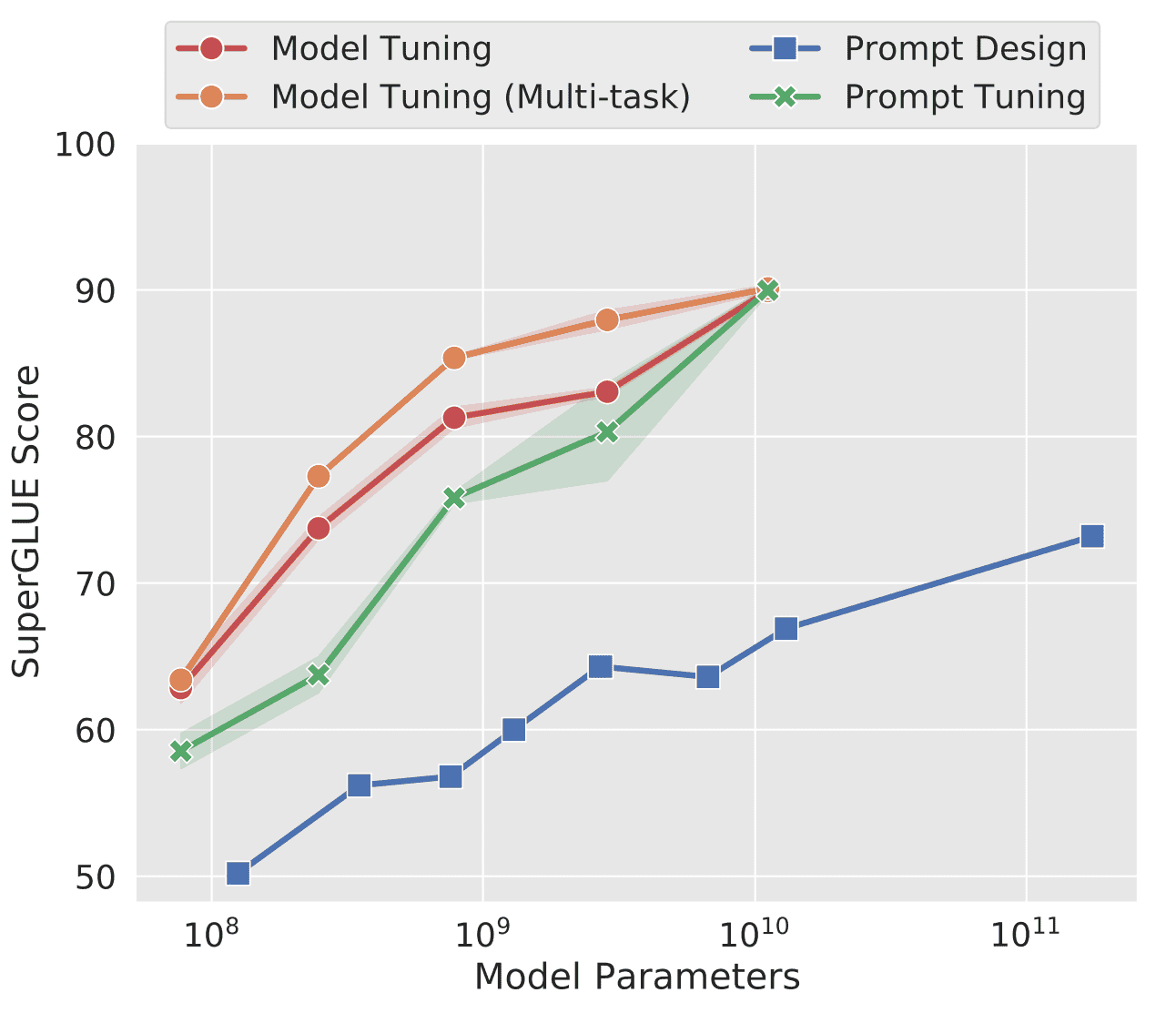
ここで、この図の縦軸はSuperGLUEという「様々なNLPタスク精度を総合的に判断するスコア」を指します。また、横軸はパラメータ数であり、この値が増加するにつれて、当然SuperGLUEは上昇します。
この図を見ても明らかですが、Prompt Designの精度は一番低く、Model Tuningと比べても、最大で25ポイント以上もの差をつけられています。
本論文の提案手法「Prompt Tuning」とは?
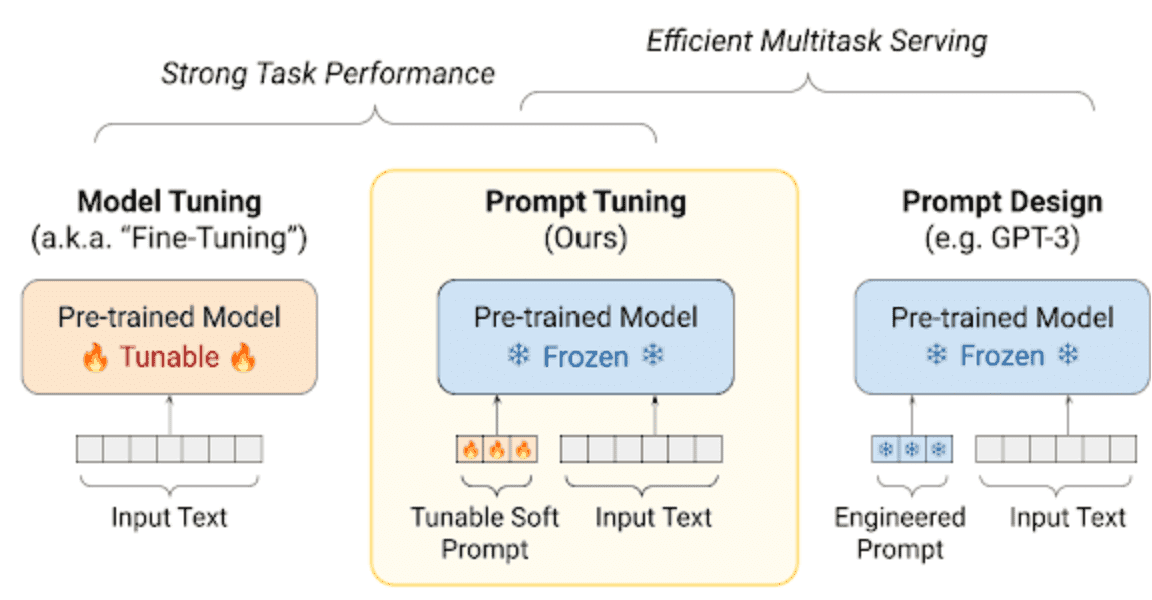
ここでようやく、本論文の提案手法の紹介です。Prompt Tuningの方法とは、ズバリPromptを学習させてしまおうというもの。
https://blog.research.google/2022/02/guiding-frozen-language-models-with.html
上図より、Promptに当たる入力テキストに対して、パラメータ調節可能なPrompt(Soft Prompt)が追加されているのが分かります。これは、学習ベクトルとして与えられます。また、Soft Promptと呼ばれることに注意してください。
Model Tuningでは、このようなSoft Promptは無く、入力テキストのみが入力されます。また、Prompt Designでは、Soft Promptも事前学習済みモデルも凍結され、学習されないことが分かります。
さらに、Prompt TuningではModel Tuningのように、各タスクごとにモデルを作り上げる必要はなく、一つの事前学習済みモデルだけを複数のタスクに特化させられるのです。
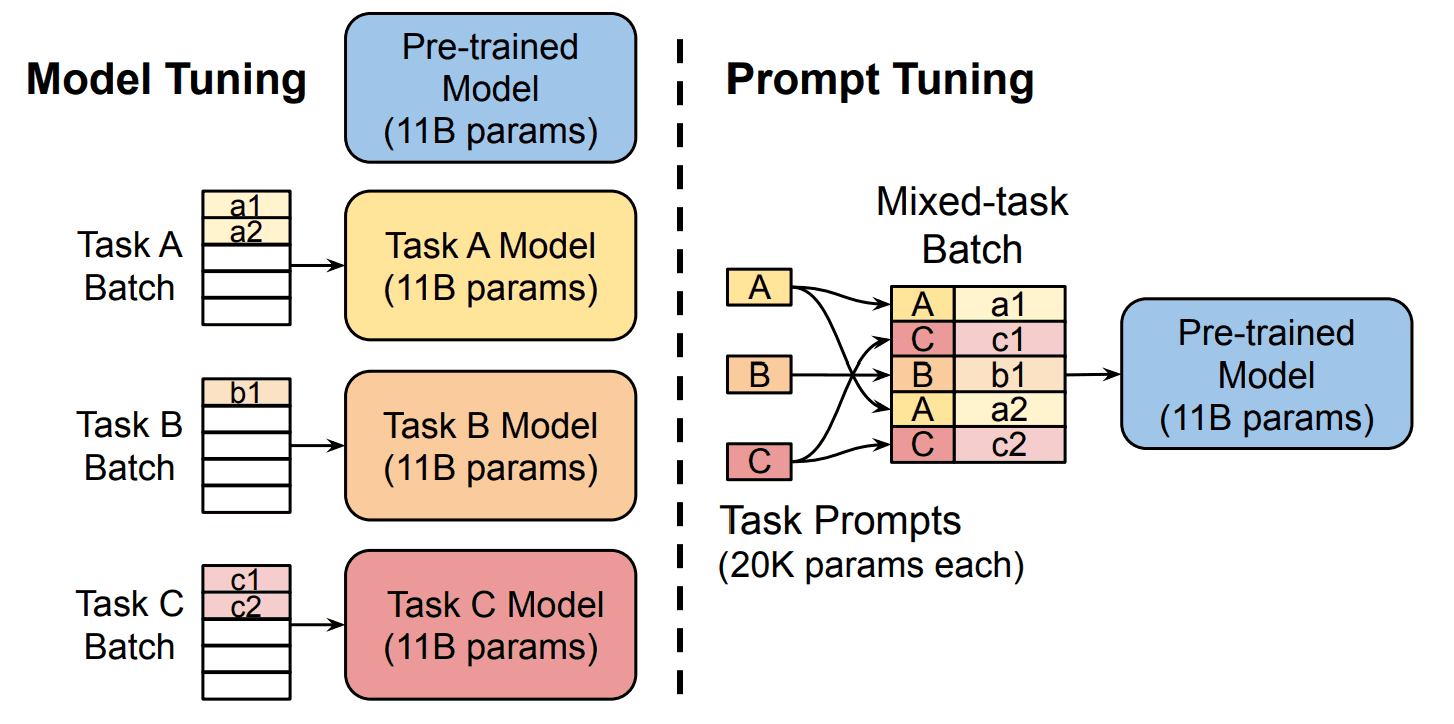
ここで、Soft Promptは「トークン数」と「埋め込み」で構成されます。それぞれの定義は、以下の通りです。
- トークン数: 入力される単語数のようなもの
- 埋め込み: 各トークンをベクトル表現したもの(embedding)
この時、Soft Promptのトークン数をpとし、各トークンの埋め込みのベクトル次元をeとすると、Soft Promtのパラメータ数はp*eで表されます。ここで、Prompt TuningとModel Tuningとの学習パラメータ数を比較してみましょう。
例えば、Soft Promptのトークン数pを100、単語の埋め込み表現の次元数eを4096次元とすると、学習パラメータ数は以下の通りです。
- Prompt Tuning: 100*4096=409600パラメータ
- Model Tuning: 事前学習済みモデルをT5と設定した場合、最大でも110億パラメータ
Model Tuningと比較しても、Prompt Tuningの方がはるかに効率的であることが分かるでしょう。
最適なSoft Promptのトークン数pとは?
Soft Promptのトークン数p、つまりlengthが少ない方が、学習パラメータも少なくなるので、より効率的になります。ただし、一般的にはパラメータ数が少なくなると、精度が低くなるのですが、Prompt Tuningの場合はどうでしょう。
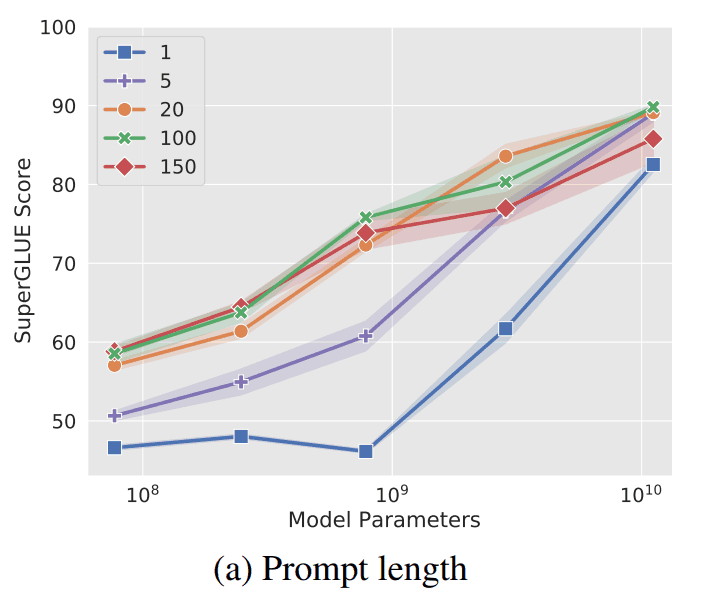
上図を見ると、やはりトークン数が多いほど、精度が高くなるのが明白です。ただし、パラメータ数が1010=100億(T5のパラメータ数に匹敵)の場合、トークン数が1でも高い精度が出ているのが分かります。
そのため、巨大なモデルを事前学習済みモデルに使用する場合は、このトークン数はあまり関係ないでしょう。
結果
本研究では、様々な検証が行われていますが、ここでは以下の3つに絞ってご紹介します。
- 各手法とPrompt Tuningとの精度比較
- ドメインシフトへの適応
- Prompt Ensembling
それでは順番に見ていきましょう。
各手法とPrompt Tuningとの精度比較
本研究では、Prompt Tuningの精度を検証するために、Model Tuning・Prompt Designとの比較実験が行われています。ここで、Model TuningとPrompt Tuningでは事前学習済みモデルとしてT5が、Prompt DesignではGPT-3が用いられています。
結果は、以下の図の通りになりました。これは、再掲になります。
見てわかる通り、Prompt DesignよりもPrompt Tuningの方がはるかに高性能です。それに加えて、パラメータ数が1010=100億まで増加すると、Prompt TuningはModel Tuningとほぼ同じ精度に到達しています。
ドメインシフトへの適応
ドメインシフト問題とは、LLMがデータセットに対して過適合を起こす現象です。例えば、片方のデータセットで学習したモデルが、もう片方のデータセットにも適応できるとは限りません。
そのような過適合を起こさず、ドメインシフトへの適応能力があるかを検証するために、本研究ではQQPとMRPCというデータセットに対して、学習とテストを別に行います。例えば、QQPで学習する場合、MRPCでテストを行います。
加えて、この検証では、Model TuningとPrompt Tuningで精度比較が行われています。結果は以下の通りです。
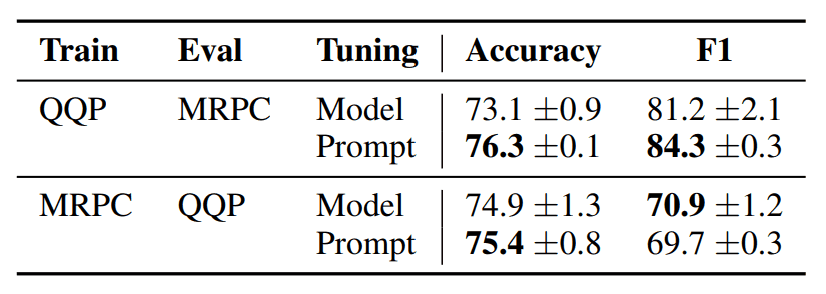 QQP→MRPCの場合、AccuracyとF1ともに、Prompt Tuningの方が高いのが分かります。MRPC→QQPに関しても、AccuracyではPrompt Tuningの方が高いです。
QQP→MRPCの場合、AccuracyとF1ともに、Prompt Tuningの方が高いのが分かります。MRPC→QQPに関しても、AccuracyではPrompt Tuningの方が高いです。
そのため、ドメインシフト問題に関しては、Prompt Tuningの方が適応能力があるのかもしれません。
Prompt Ensembling
複数のモデルの出力から、多数決などによって最終的な出力を算出する「Ensemble学習」というものがあります。
本研究では、このEnsemble学習をPromptに適用した検証も行われています。具体的には、複数のモデルを用意するのではなく、複数のPromptパターンを用意して、それに対してEnsemle学習を適用しています。
結果は以下の通りです。
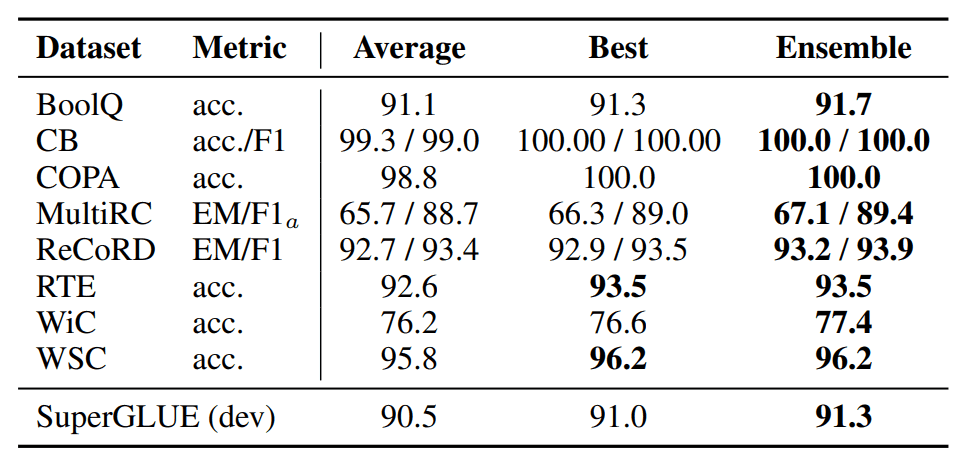
上図の結果より、Prompt TuningでもEnsemble学習によって、高精度を出せることが分かりました。
まとめ
本研究では、「Promptも最適化してしまおう」という動機のもと提案された「Prompt Tuning」が発表されました。
現在に至るまで、プロンプトエンジニア(手動)という、最適なプロンプト文を設計する方法が主流です。しかし、せっかく大量データと計算リソースを使ってLLMを学習したのに、その後の利用に関しては人間が頑張るのは非効率であるため、プロンプトもLLMに自動で作らせた方が良い、という意見もしばしば出てきています。
本研究は、そんな意見に対して、有効なアプローチと根拠を示したと思います。
また本研究自体、それほど新しい研究でもないので、今後もっと有効なアプローチが出てくることが期待されます。そうすれば、自分たち人間がやることは「プロンプトテクニックなんて全く気にせず、直感的にLLMに命令する」だけに留まり、後の「LLMの精度を上げる」という作業は、LLMが勝手にしてくれるようになるのかもしれません。
実際に、エージェントなどの関連技術も出ているので、要チェックです。






この記事に関するカテゴリー



