Pruningには大きなモデルは必要ない?自動的にスパースネットワークを見つける!
3つの要点
✔️ $ l_0 $正則化の新しい近似法による新しいPruning手法の提案
✔️ 大きさや勾配などのヒューリスティックベースのPruningよりも高性能
✔️ サブネットワーク探索を並列で実行した場合、特に効率的
Winning the lottery with continuous sparsification
written by Pedro Savarese, Hugo Silva, Michael Maire
(Submitted on 11 Jan 2021)
Comments: Published as a conference paper at NeurIPS 2020
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
code:
はじめに
Pruningはディープニューラルネットワークの重みを削減し、軽量なモデルを作成するために使用される手法です。従来は、ネットワークの重みや勾配を用いたヒューリスティックな方法で枝を刈る手法が主でしたが、それらの指標が本当に枝刈りの指標として適しているかは明瞭ではありません。
本論文では、ヒューリスティックではない手法として$ l_0 $正則化を用いて最適な枝刈りを提供します。また、Lottery Ticket Hypothesis(宝くじ仮説)と組み合わせることで、$ l_0 $正則化によるサブネットワーク探索手法を提供します。
実験では宝くじ仮説のIterative Magnitude Pruningと比較してサブネットワークの探索において、よくスパース化されたネットワーク、より精度の良いネットワークを見つけています。
$ l_0 $正則化によるPruning
ネットワークの重みがゼロになる、すなわち疎になるように制約をかける正則化手法が $ l_0 $正則化です。$ l_0$ をロス関数に追加することで、ネットワークの学習中に適切にネットワークの刈込が可能になります。また、ヒューリスティックな指標ではないため、ネットワークが自動的に削除するべき重みを見つけてくれます。
しかしながら、$ l_0 $正則化は微分不可能です。そのため、対応策として従来の研究では0、1のマスクを生成する確率分布を使用していました。ですが、分布のバイアスや分散によって生成されるマスクが安定しない問題があります。また、宝くじ仮説におけるサブネットワーク探索手法ではヒューリスティックな指標でネットワークを削減していますが、それらの指標が明確に削減すべき重みを示しているかは明らかではありません。
したがって、本論文では$ l_0 $正則化の数式を見直し、決定論的な$ l_0 $正則化を近似する手法を提案し、その手法をサブネットワーク探索に応用することで、SOTAを達成しています。
提案手法(Continuous Sparsification)
始めにネットワーク$ f $のロスを最小化する際にペナルティ項として、重み$ w $に対して$ l_0 $正則化を使用します。正則化項を含んだロス最小化問題は$$\min _{w \in \mathbb{R}^{d}} L(f(\cdot ; w))+\lambda \cdot\|w\|_{0}$$
次に、マスク$ m \in\{0,1\}^{d} $を導入します。$$\min _{w \in \mathbb{R}^{d}, m \in\{0,1\}^{d}} L(f(\cdot ; m \odot w))+\lambda \cdot\|m\|_{1}$$
マスク$ m $はブーリアンのため、$ |m\|_{0} = |m\|_{1} $です。そのため、$ l_0 $正則化を$ l_1 $正則化に変えることができます。$m$はブーリアンのため、最急降下法で微分不可能です。ペナルティ項を微分可能にするために最初にヘヴィサイド関数を導入します:$$ \min _{w \in \mathbb{R}^{d}, s \in \mathbb{R}_{\neq 0}^{d}} L(f(\cdot ; H(s) \odot w))+\lambda \cdot\|H(s)\|_{1} 。$$
$s$は新しく最小化するための変数で、ヘヴィサイド関数によって$s$がプラスであれば、マスクは1、マイナスであればマスクは0になります。次に、さらに式を微分可能に変形します。
微分可能に変形した式は、$$ L_{\beta}(w, s):=L(f(\cdot ; \sigma(\beta s) \odot w))+\lambda \cdot\|\sigma(\beta s)\|_{1} $$です。新たにシグモイド関数$\sigma$を使用しています。また、$\beta \in[1, \infty)$は、学習時にユーザが決定するハイパーパラメータになります。
$\beta$を$infty$に近づけると、$\lim _{\beta \rightarrow \infty} \sigma(\beta s)=H(s)$が成り立ちます。一方、$\beta = 1$の時は$\sigma(\beta s)=\sigma(s)$が成り立ちます。したがって、以下の式が成り立ちます。
$$ \min _{w \in \mathbb{R}^{d} \atop s \in \mathbb{R}_{\neq 0}^{d}} \lim _{\beta \rightarrow \infty} L_{\beta}(w, s)=\min _{w \in \mathbb{R}^{d} \atop s \in \mathbb{R}_{\neq 0}^{d}} L(f(\cdot ; H(s) \odot w))+\lambda \cdot\|H(s)\|_{1} $$
$\beta$はハイパーパラメータとして、計算の難しさを制御します。学習中に$\beta$を徐々に増加させることによって、難解な問題を近似することに成功する可能性があります(数値接続に由来します)。
実験結果
本論文では、主に宝くじ仮説に基づくサブネットワーク生成の性能比較と従来のPruningとの性能比較を行っています。最初に提案手法を大きさベースのプルーニングであるIterative Magnitude Pruningとサブネットワークの生成能力の観点から比較しました。
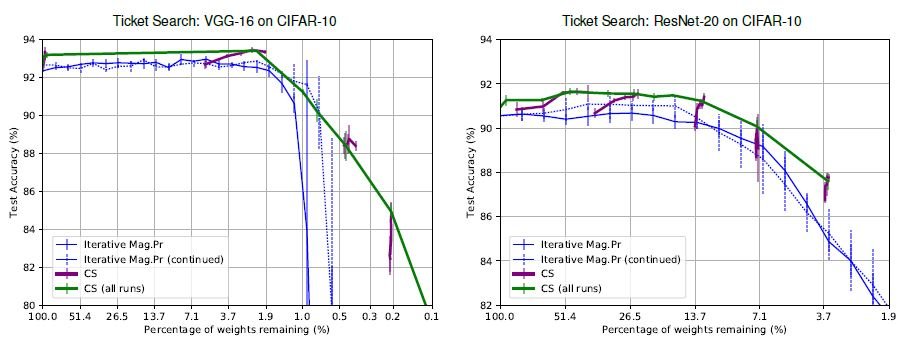
CIFAR-10で学習したVGG-16とResNet-20でサブネットワークの探索を行っており、どちらにおいても提案手法(CS)が優位な結果になっています。
Iterative Mag.Prは通常の宝くじ仮説で使用された大きさベースのサブネットワーク探索手法です。通常は枝刈りを複数のラウンドに分けて行う際に、一回のラウンドで学習した重みを初期の重みにリセットするのですが、Iterative Mag.Pr (continued)では、ラウンドが切り替わる際にも思いをリセットさせなかった場合です。
CSは提案手法で、CS (all runs)は各実験の結果をまとめて、各点をつなげた結果です。ここで面白いのは、提案手法は枝刈り率を高くしても精度が落ちにくいところです。この効果は極限まで枝刈りをする時に有効に働くと思います。
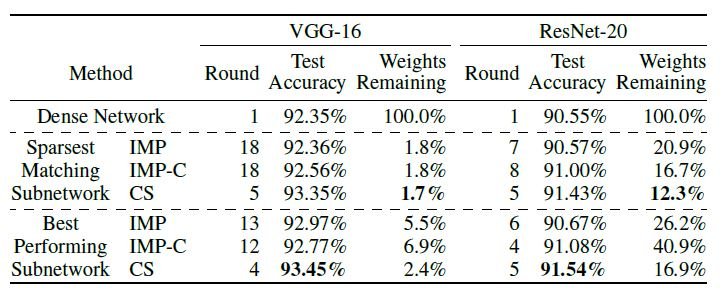
ベースラインのネットワークと同等の性能を維持したまま、最も疎なネットワークの比較においても、提案手法はVGG-16において、1.7 %、ResNet-20においても、12.3 %とより疎なサブネットワークを見つけることができています。
最も良い性能のサブネットワークの比較においてもVGG-16において、93.45 %、ResNet-20においても、91.54 %と高精度なネットワークを見つけています。また、精度が良いにも関わらず、高い枝刈り率を達成しています。IMPと比較すると学習にかかるラウンド数が圧倒的に少ないです。したがって、素早くサブネットワークを見つけることが可能になっています。次に、従来のヒューリスティックなPruning手法と提案手法との比較結果です。
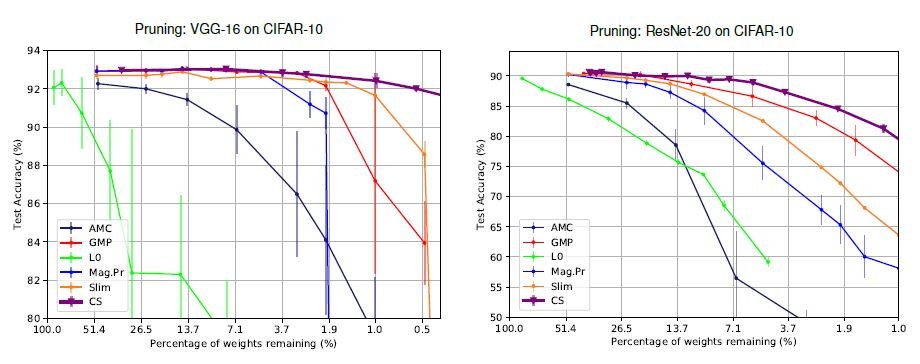
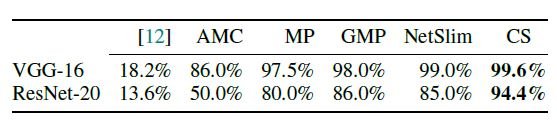
従来のヒューリスティックな手法と違い、突然の精度の低下がなく、高い精度を維持していることが分かります。また、従来のL0正則化による手法は不安定なため、VGG-16及びResNet-20両者において最も悪い結果ですが、提案手法では決定論的な関数を導入したことで、安定性が向上しています。
まとめ
本論文では、従来の$ l_0 $正則化によるPruningが不安定である問題とサブネットワーク探索手法においてヒューリスティックな手法しかなく、その正当性を評価できない問題に対処するために、新しい$ l_0 $正則化近似手法を提案し、サブネットワーク探索に応用することで、サブネットワーク探索及びPruning両者においてSOTAを達成しています。
提案手法は刈込率が高くても、精度を維持しており他の手法より優れている点であるとかんじました。また、並列計算が可能な環境であれば、圧倒的に速くサブネットワークを見つけることができるため、近年の計算環境により適した手法であると思います。
特に興味を引く点は、提案手法は少ないラウンドでスパースかつ高精度のネットワークを見つけていることです。従来のPruningでは、直接小さなモデルを作ることが大変なため、大きなモデルから小さなモデルを作成することが一般的でした。しかし、提案手法では、元のネットワークの学習途中の早い段階で、良いサブネットワークを見つけています。これは、従来のトレーニング後に行うPruningに疑問を投げかけるものであると思います。
本論文でも述べられていますが、サブネットワークは似たような異なるタスク間で移行できることが示されているため、転移学習とPruningの組み合わせも面白いテーマであると思います。





この記事に関するカテゴリー


