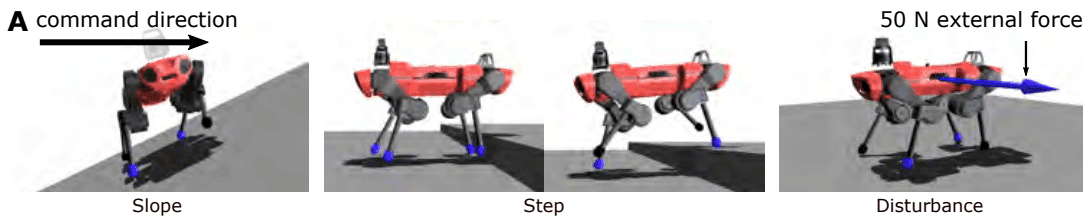
多様な環境下での歩行に成功した4脚ロボットコントローラ!
3つの要点
✔️ 雪原や森林など多様な環境で安定した歩行を実現
✔️ 教師方策と生徒方策による二段階の方策学習
✔️ 地形の難易度の自動調節によるカリキュラム学習
Learning Quadrupedal Locomotion over Challenging Terrain
written by Joonho Lee, Jemin Hwangbo, Lorenz Wellhausen, Vladlen Koltun, Marco Hutter
(Submitted on 21 Oct 2020)
Comments: Published on arxiv.
Subjects: Robotics (cs.RO); Machine Learning (cs.LG); Systems and Control (eess.SY)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
4脚ロボットにおける未知の環境を含む多様な環境下での歩行動作の獲得がロボットの適用可能な領域の拡大に繋がる事は明らかです。しかしこれまで提案されてきた歩行制御コントローラは、人力によるチューニングを必要とし未知の環境に弱いというような問題を抱えており、実応用可能なレベルとは言い難いものでした。またRLを利用したコントローラであっても適用できる環境が研究室内や平坦な地形といった比較的簡単なものに限られていました。
今回紹介する論文は、個別のチューニングなしで雪上・森林・階段・小川など多様な環境下での安定な歩行を実現したコントローラを提案しています。
提案コントローラは、脆かったり滑ったりするような全く学習してない地形でも歩行できるようなロバスト性を持つことが確認され、従来手法に比べて非常に優れた安定性を発揮しています。では元の論文同様、性能・手法の順に見ていきたいと思います。

性能
いくつかの環境に分けて見ていきたいと思います。なお比較対象となる従来手法(Baseline)は環境に応じて当時の最先端のものを使用しています。
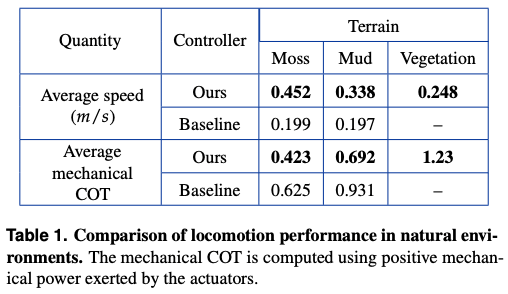
自然環境

湿った苔・泥・雑草の上という3つの環境においてそれぞれ平均速度と移動効率という2点に着目し、従来手法と比較しています。結果として、計6点全ての組み合わせにおいて提案手法が従来手法を上回る事となりました。さらに着目すべき点として、従来手法は雑草が生い茂る環境において草に脚を取られていしまい歩行出来なかったのに対して、提案手法はそのような場合においても自力で雑草を振りほどき歩行したという点が挙げられます。
さらにデータには直接加味されていないものの、従来手法は計測中に何度も転倒したのに対し、提案手法は一度も転倒することがなかったため、実際の数値以上に提案手法は優れていると考えることができるでしょう。
DARPA Subterranean Challenge

DARPA Subterranean Challenge Urban Circuit はトンネルのような地下環境でのタスクを実行できるロボット技術の発展を目的とした大会です。
提案コントローラを組み込んだ ANYmal-B は、急な階段の降下などの4つの課題に挑戦し、一度も転倒することなく60分間稼働を続けることに成功しました。
室内
最後に室内での実験について見ていきたいと思います。
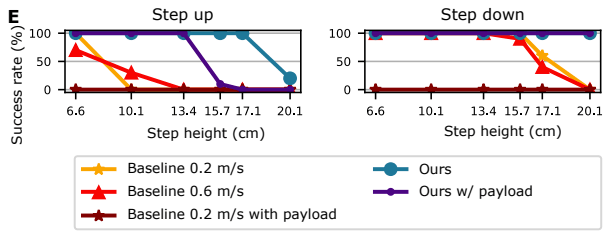
元論文中ではいくつかの設定・基準の下で比較を行っていますが、ここでは段差の昇降に関する部分を抜粋して紹介したいと思います。
下図は段差の幅に対してどの程度の成功率で突破できるかを表したものです。この図を見てもらうと明らかなように、提案手法は重り(10kg)が課されていても広い範囲の段差に対応出来ているのに対し、従来手法は重りがない状態でも成功する範囲が狭く、さらに重りがあると全く成功出来きていないということが分かります。
提案手法の安定性がいかに優れているかを示す結果だと言えるでしょう。
手法
提案手法が素晴らしい性能を持っているのを確認したところで、どのようにコントローラを作成したのかについて詳しく見ていきましょう。
ポイントは以下の3つです。それぞれについて説明していきます。
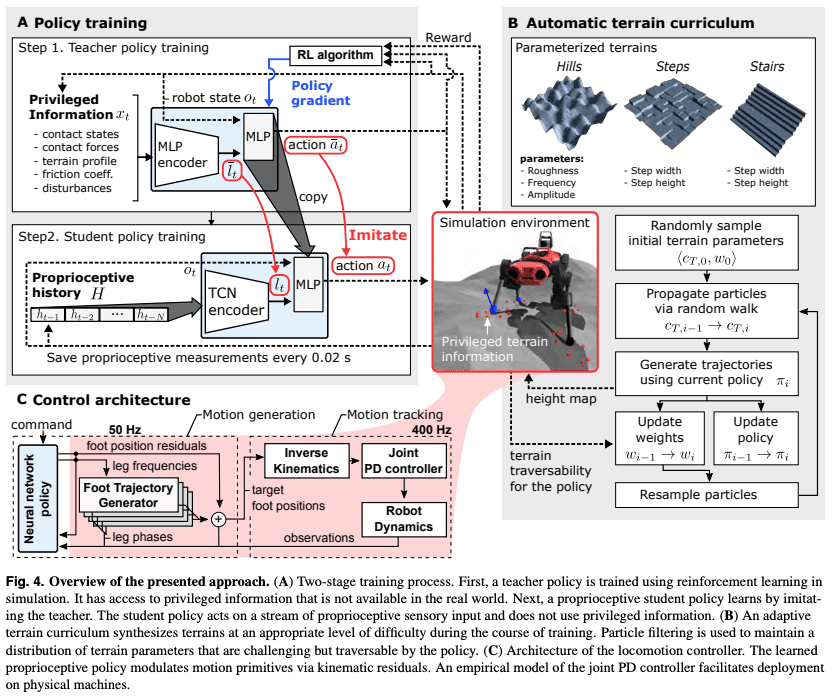
- 特権情報を利用する教師方策と固有受容情報のみを利用する生徒方策による二段階の方策学習
- 自動で地形の難易度を調整するカリキュラム学習
- 動作の生成・追従から成る二段階の制御構造
特権情報を利用する教師方策と固有受容情報のみを利用する生徒方策による二段階の方策学習
まず用語の整理から行いたいと思います。
特権情報(privileged information)とは、各脚に加わる力や摩擦係数などの歩行するには有用だが実世界においては取得することが困難な情報を指します。なおシミュレーター上での学習では参照可能な値になります。
次に固有受容情報(proprioceptive information)とは、各関節の位置や速度などの自己に関する高い精度で取得可能な値のことを指します。
特権情報が取得できない実環境において歩行させるために、リッチな情報を与えて教師方策を学習させ、その後固有受容情報のみで歩行できるように生徒方策を学習させていくというのがこの手法のポイントです。
では具体的な流れについて詳しく見ていきましょう。
初めに教師方策を学習させます。特権情報を組み込めば環境は完全に観測可能であるという仮定を入れ、通常のRLの枠組みを使います。
入力として特権情報xtとロボットの状態otを用い、適切なアクションatを出力できるようTRPOで学習していきます。報酬はゴールに近づく速度に応じて与えられます。
ここでアクションだけでなく、特権情報の潜在表現であるltについても同時に学習を進めます。この章初めに提示した図A(左上)が分かりやすいと思うので適宜参考にしながら見ていただければと思います。
その後生徒方策の学習に移ります。生徒方策は固有受容情報htの系列を用いて学習します。htはロボットの状態otの部分集合として定義され、H={ht-1,...,ht-N-1}をネットワークへの入力に使います。ここでNはどの程度まで遡って考慮するかを表すハイパーパラメータです。
ネットワーク構造としてはTCNを用い、損失関数は次のように定義します。
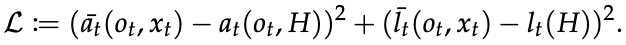
ここでバー( ̄ ̄ ̄ )は教師方策から出力された値であることを意味しています。
この式から明らかなように、生徒方策は教師方策から与えられるアクションと特権情報の潜在表現を模倣するように学習していきます。
なおネットワーク構造には Temporal Convolutional Network(TCN) を用いています。TCNとは簡単に言うと時系列データをCNNの枠組みで扱えるようにしたものになります。時系列データを扱うネットワーク構造というとRNNやGRUが一般的ですが、今回TCNを採用した理由としてはGRUを用いる場合と比べて学習効率が良いという点と長大なデータに対しても透明性のある制御が可能であるという点が指摘されています。
自動で地形の難易度を調整するカリキュラム学習
エージェントは主に3種類の地形(丘・段差・階段)で学習しますが、より効率的に学習を進めるため地形の難しさの自動調整を行います。ここではその手法について見ていきます。
地形の難易度をベクトルCtで表現します。詳細は割愛しますが、地形はこのCtを入力として生成されます。例えば段差の高さなどの情報がCtには入っており、上の図ではパラメータの違いによる地形の変化を確認できます。
このCtを適切な分布からサンプルしてくる訳ですが、パーティクルフィルタを用いて理想的なCtの分布を近似するのがこの手法のポイントです。
理想的なCtについて考えるために、いくつかの変数を定義します。
初めに、ある方策・地形の下で、エージェントの歩行能力(Traversability)を測る指標として以下の値を導入します。
ここでvはエージェントが歩けているかを表す変数で速度が一定値以上の時1、それ以外で0をとります。また、 ξは方策から生成された軌跡を表現しています。
次に、ある方策の下でCtの良さを以下のように表現することとします。
式を見てもらうと分かる通り、Ctの良さを歩行能力が0.5以上0.9以下である確率と定義します。
このように現在の地形パラメータの良さが定量的にわかるようになったので、次は大きいTdを得られるようなCtをサンプリングしてくるアルゴリズムを見ていきます。
それにはSIRパーティクルフィルタという手法を用います。
本記事ではパーティクルフィルタの詳しい解説は行いませんが、粒子の密度によって確率分布を近似する手法になっています。ロボットの自己位置推定などでも使われる手法であり、ネット上に情報も多いのでそちらも参照してみてください。
では簡単に流れを見ていきます。まずCtと対応する重みwのペアをNparticle個用意します。Nparticleは近似に使用する粒子の個数を表すハイパーパラメータであり、本論文では10となっています。
- 次に、Ctと訓練中の方策によって軌跡を生成、Tdを計算します。
- 得られたTdの比率に対応するように重みを更新します。
- Ctをリサンプリングし、システムモデルに従って遷移させます。
- 1に戻る。
というアルゴリズムです。
この手続きによって、エージェントの能力に応じた適切な難易度の地形が生成できるようになります。
動作の生成・追従から成る二段階の制御構造
制御アーキテクチャは大きく二つに分けて考えることができます。動作生成部と動作追従部です。
動作生成部では、RLエージェントの提案するアクションを元に目標となる足先位置を出力します。
具体的な計算過程を見ていきましょう。提案されたアクションatは16次元のベクトルであり、一つの脚に対応する部分は4次元です。周波数fi(1次元)と各次元に対する補正値Δrfi,T(3次元)から構成されます。ここでi∈{1,2,3,4}であり各足に対応しています。これらの値を用いて、目標となる足先位置は下のように構成されます。
なおFは位相に応じた足先軌道を与える関数であり[0, 2π) からR3への写像になります。また、Φiは周波数fiと時刻tに依存しており、各足の位相を表す変数になります。
これによって目標とする足先位置を手に入れることが出来ました。次は、どのようにそれを実現するかについて簡単に見ていきます。
動作追従部においては、動作生成部の出力する足先位置に対して位置に関する逆運動学問題を解析的に解くことでその足先位置を与える関節角度を計算します。その後、各関節においてPDコントローラを使用し目標となる関節角度を実現しています。
今後の研究方針
提案手法の今後の発展について2点著者らは指摘しています。
まず、trot gait (馬の小走りのような歩き方) に近い歩行パターンしか獲得的なかったという点に関して、訓練手法に工夫を加えることで自然界に見られる多種多様な歩行パターンを獲得できるのではないかとの仮説が提示されています。
次に外部知覚の利用についてです。提案手法はLiDARや深度センサなどの外部センサを利用せず安定した歩行を実現しました。しかしこれらのセンサ類を効果的に組み入れることで、障害物を目視して迂回するなどのより実応用に向けた行動が獲得できるだろうと述べられています。
まとめ
未知の環境でも安定した歩行を実現したコントローラの性能とそれを実現した手法について見てきました。
最後にも軽く触れたように、外部センサの利用等によってこれからますます優秀な4脚ロボットが誕生することが期待されます。非常に今後の発展が楽しみな分野だと思います。



この記事に関するカテゴリー






