RRL: ImageNetを利用した強化学習のサンプル効率性の向上
3つの要点
✔️ ImageNetで事前学習されたResNetを利用しVisual RLのサンプル効率性の向上
✔️ 複雑なタスクにおいて他手法と比較して高いパフォーマンスを示す
✔️ Visual RLのベンチマークはもっと現実世界に寄せたタスクを利用するべき
RRL: Resnet as representation for Reinforcement Learning
written by Rutav Shah, Vikash Kumar
(Submitted on 7 Jul 2021 (v1), last revised 9 Jul 2021 (this version, v2))
Comments: Accepted by ICML 2021.
Subjects: Robotics (cs.RO)
code:
はじめに
本記事では、ICML2021に採択された、RRL: Resnet as representation for Reinforcement Learningという論文について紹介します。ロボットに対するRL(Reinforcement Learning, 強化学習)の応用は近年注目されていますが、画像を入力としてRL agentを学習するにはサンプル効率性の悪さからとても困難になっています。しかし、現実世界への応用を考えたときに、ロボットが入力として受け取れる情報として、ロボットのjointの角度や、ロボットに付いているカメラからの画像情報などで、物体の座標などの情報を手にすることはとても困難です。では、このように画像やロボット自身のjoint角度などの入力からどのようにタスクを効率的に解くことができるのでしょうか。
この問題に関して既存研究でも様々な手法が提案されており、supervised learningもしくはunsupervised learningによる事前学習によりエンコーダーを獲得し、それを強化学習に利用するというものがあります。しかし、基本的に表現を獲得するために、特定のタスクのためのデータ等を集める必要があるという問題点があります。それに対して、本論文は、ImageNetの画像データをResNetで事前学習したエンコーダーを利用するというとてもシンプルな手法で、効果的にサンプル効率性が上がることを示しました。
手法
そもそも、良い表現というものはどのようなものでしょうか。これは主に4つ考えられます。
1. 低次元なコンパクトな表現であること
2. 汎用性を高くするために、多様な情報を含んだ特徴量
3. ノイズや光、視点などタスクに関係のない情報による影響を受けにくい
4. RLのPolicyが必要とする分布全体をカバーするような効果的な表現
このような表現を獲得するには、ドメイン特有のデータが必要になることがほとんどですが、本論文では、どのようにして特定のドメインのデータを使わずに上記のような表現を手に入れることができるかを探りました。
そこで、本論文は、下図のようなとても単純な手法を提案しました。この手法では、エンコーダーを特定ドメインのデータで学習するのではなく、十分に広い分布を持った現実世界の画像データであるImageNetを用いて、エンコーダーを事前学習し、エンコーダーの重みを固定した上で、強化学習により方策を学習するというものです。では、この手法についてもう少し詳しく説明していきます。

RRL: Resnet as Representation for RL
強化学習において、一番理想的なシナリオは、agentが低次元のstate (物体の座標など)を受け取って、actionを実行し、そして次のstateとrewardを受け取ることで学習を進めていくことで、これは特にシミュレーション環境だと低次元のstateを簡単に得ることが出来るのでうまくいきます。しかし、現実世界では、物体などの座標などが手に入らず、その代わりに、カメラからの画像情報とロボットであれば自身のjointの角度などから学習から学習をしなければなりません。よって、このような状況下の中、高次元な情報である画像から、低次元な特徴量を効果的に学習し利用することが重要になってきます。そこで、上記に上げたような良い特徴表現の項目を満たすために、本論文では、ResNetをImageNetで事前学習し、そのエンコーダーを使うことで、広い分布のデータに対応することができるということを実験的に示しました。手法に関しては、上図の通りで、入力画像を事前学習されたエンコーダーが受け取り特徴量を出力し、ロボット自身のjointの角度などの情報があるのであれば、joint情報などと画像から得た特徴量を結合し、それを入力としてagentに受け渡します。ここで、事前学習済みのエンコーダーの重みは固定します。
実験
本論文では、DAPGとよばれる強化学習アルゴリズムを利用して実験を行っています。DAPGは低次元のstateを入力とした場合、効果的に学習することが出来ますが、画像などの高次元のデータを入力とした場合、学習がうまくいかないことが言われています。よって、本研究では、画像から得た低次元の特徴表現を利用して、DAPGのアルゴリズムによりagentを効果的に学習することができるかどうかを、実験的に示しました。この実験では以下の5つのことについて確認しています。
- 大規模画像データにより事前学習された特徴量により、RRLが複雑なタスクを画像から学習できるかどうか?
- RRLのパフォーマンスは、最新の他の手法と比べて良いかどうか?
- 事前学習のモデル(ResNet)の選択によってパフォーマンスが影響するかどうか?
- RRLのモデルの大きさなどによって大きくパフォーマンスが影響するかどうか?
- 通常使われる画像を入力とした連続制御のタスクは効果的なベンチマークかどうか?
実験では、Adroit manipulation suiteの下図のようなmanipulation taskに関して実験を行いました。これらのタスクは、stateから学習するのも難しく、そして画像も複雑であることから、学習を成功させるためには、効果的な特徴量表現が必要になります。

結果
下図は、RRLと他のベースラインであるFERM、DAPG、NPG (Natural Policy gradient)との比較です。下図の通り、NPGではstateのみでも学習に失敗していることが多く、これらのことからタスク自体が比較的難しいことがわかります。DAPGを画像ではなくstateのみで学習した際は、タスクを解くことに成功しており、これをoracle baselineとしてみなす事ができます。そして、RRLは画像からの学習ではありますが、どのタスクもよく解けており、タスクによってはstateを入力としたDAPGとほとんど変わらない結果を示しています。最後に、FERMと呼ばれる最新の画像を入力としたサンプル効率性を高めたフレームワークを利用して学習させたagentは、タスクをある程度解くことに成功しているものもありますが、結果の分散が大きいことから、学習がとても不安定であることが分かります。FERMはRRLとは異なり、ImageNetではなくそのタスクのデータを用いてエンコーダーを学習するので、タスク特有の特徴量が学習されます。

Visual Distractorsによる影響
下図中央と右のグラフは、光や物体の色を変えたとき(Visual distractors)のRRLとFERMのパフォーマンスに対する影響を調べた結果です。下図の結果の通り、RRLはFERMと比較して、visual distractorの影響が受けにくいことが分かります。これは、RRLのエンコーダーが広い分布の大規模画像データから学習されたものなので、encoder自体がvisual distractorの影響を比較的受けにくく、その結果学習されるpolicyもvisual distractorに対する影響を受けにくくなります。それに対して、FERMはタスク特有(固定の光の条件や物体の色)のデータで学習したエンコーダーを利用しているので、visual distractorによる影響を受けやすく、結果パフォーマンスが大きく悪化しました。

特徴量表現による影響
そもそもResNetというモデルの選択が偶然にも効果的な特徴量を学習できるだけではないかという疑問があります。これを解決するために、ResNetを用いたRRLと、ShuffleNet、hierarchical VAE (VDVAE)、そしてMobileNetを用いたRRLとでパフォーマンスを比較しました。VAEに関してはパフォーマンスが少し低いですが、基本的に大きなパフォーマンスが見られないことから、ResNet以外のモデルでも有効であることが示すことができました。

下図は特定のタスクデータを利用して学習したVAEのエンコーダーを利用したRLL(VAE)と広い分布のデータで学習したResnetをベースとした RRLの比較を表しています。下図から、Resnetを利用したほうが、パフォーマンスが高い。そして広い分布の大規模データから学習したエンコーダーのほうが、タスク特有なデータを用いて学習した非常に脆いエンコーダーと比べて効果的であることがいえます。

異なる入力によるパフォーマンスへの影響
入力の種類やノイズによってRRLのパフォーマンスがどのように変化するかを調べました。下図は、sensorから得られるロボットのjointの情報がないRRL(Vision)、jointの情報にnoiseを加えたRRL(Noise)と画像とjointの両方のデータを利用したRRL(Vision+Sensors)を比較しました。下図の通り、多少のパフォーマンスの悪化はあるものの、ノイズに強くそして、画像のみでもある程度良いパフォーマンスを出すことを示す事ができました。

RRLの方策の大きさや報酬関数によるパフォーマンスへの影響
では、報酬関数がsparseかdenseでは結果に影響を与えるのでしょうか?下図左は、報酬関数がsparseのときとdenseのときの結果を表しており、どちらも高いパフォーマンスを出すことができました。これにより、RRLを用いることで、本来dense rewardを定義するためにドメイン特有の知識が必要なところ、sparseな報酬関数を利用してもとけることから、そのようなドメイン特有の知識が必要ないという利点を示しました。また、policyのnetworkのサイズを変えて比較したものが、下図右に表されており、こちらも大きなパフォーマンスの違いを示すことなく、安定して良い結果を出すことに成功しています。

現在主に使われているVisual RLのベンチマークの有用性
DMControlという環境は、画像を入力としたRLのベンチマークとしてよく使われます(RAD、SAC+AE、CURL、DrQなど)。しかしこのような手法はDMControldではうまくいきますが、Adroit Manipulation benchmarkなどでは、高いパフォーマンスを示めさないことがわかっています。例えば、ベースラインとして紹介したFERMはExpert demonstrationとRADを利用して学習する手法になりますが、学習が不安定もしくは良いパフォーマンスを示しませんでした。
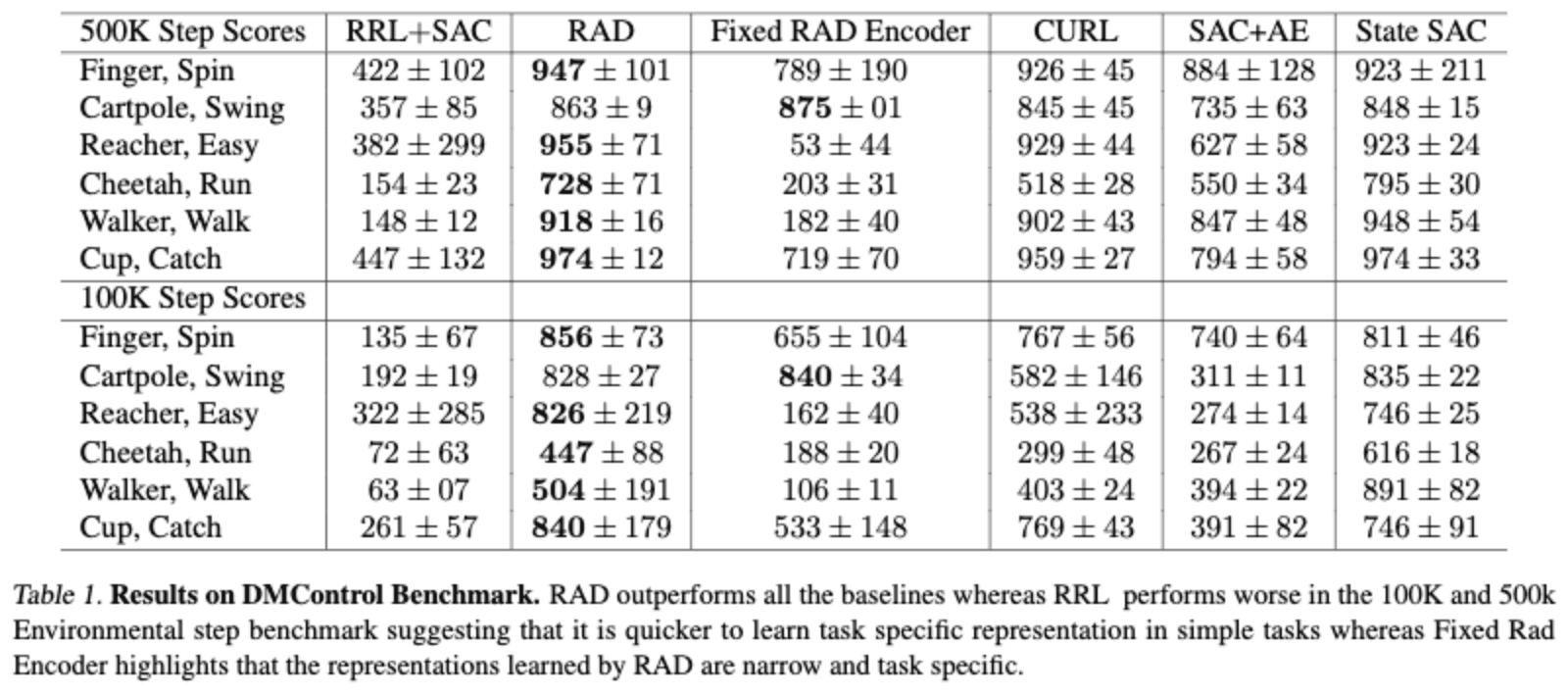
下のテーブルはDMControlのタスクにおける、パフォーマンスを示しています。RADなどの手法は画像の情報が複雑でないDMControlのタスクで提案手法であるRRLより高いパフォーマンスを出していることが分かります。ここで、RRLのパフォーマンスが低いのは、現実世界の画像データであるImageNetとDMControlの画像情報のドメインのギャップが大きいからと考えられ、より現実の画像に近いようなタスクをベンチマークにすることを訴えています。
また、RADをCartpoleのデータを用いて学習したエンコーダーを固定し、似たような画像情報を提供するタスクでRL agentを学習したFixed RAD Encoderを見てみると、RADと比べて大きくパフォーマンスが落ちていることから、このEncoderがタスク特有の特徴量を学習していることがわかり、そのエンコーダーの汎用性の低さが分かります。そして、そのようなタスク特有の特徴量表現は、単純な画像を入力とした場合は簡単に学習できますが、複雑な画像になればなるほど、難しくなっていきます。
まとめ
強化学習において、画像を入力とした場合のサンプル効率性の悪さは重要な課題となっており、ImageNetで事前学習したResNetの特徴量を利用するという、とてもシンプルな方法でサンプル効率性が上がることを示した論文を紹介しました。ただし、ImageNetと大きなドメインのギャップがあると効果的でなく、特に現実世界でのロボットを用いた実験でどの程度うまくいくかは気になるところです。また、RoboticsのためのImageNetのような広い分布をカバーした大規模データセットがあると、おもしろい研究ができるのではないかと考えています。



この記事に関するカテゴリー






