
画像と自然言語から操作するロボット学習システムRT-1
3つの要点
✔️ 移動式のロボットアームを使用したTransformerを元にしたロボット学習システムRobotics Transformer 1
✔️ 画像と自然言語の命令からロボットアームの動きの生成やタスク管理を行う
✔️ ロボットのリアルタイム制御モデルと、実世界でのロボットタスクから得られるデータセットを使い、モデルの一般化を行う
RT-1: Robotics Transformer for Real-World Control at Scale
written by Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang-Huei Lee, Sergey Levine, Yao Lu, Utsav Malla, Deeksha Manjunath, Igor Mordatch, Ofir Nachum, Carolina Parada, Jodilyn Peralta, Emily Perez, Karl Pertsch, Jornell Quiambao, Kanishka Rao, Michael Ryoo, Grecia Salazar, Pannag Sanketi, Kevin Sayed, Jaspiar Singh, Sumedh Sontakke, Austin Stone, Clayton Tan, Huong Tran, Vincent Vanhoucke, Steve Vega, Quan Vuong, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Tianhe Yu, Brianna Zitkovich
(Submitted on 13 Dec 2022)
Comments: Published on arxiv.
Subjects: Robotics (cs.RO); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
AI-SCHOLARイベント
AI技術は日進月歩で進み、皆さんもAI技術に関して多くのブームから衰退までを見ていると思います.そんな中,昨今のブームといえば,GPTからの大規模言語モデルだと思います.そこで,今回はAI-SCHOLARのメンバーを集めて,GPTの総論から話題にも上がるセキュリティ周りなどの技術者・研究者目線でのイベントを実施いたします.

はじめに
最近では、コンピュータビジョンや自然言語処理、音声認識などで人工知能を使った技術をよく耳にするようになりました。また、これらの技術を使ったロボット(ドローンや配膳ロボット)を目にする機会が増えたのではないでしょうか。しかし、ロボット工学におけるの機械学習モデルを一般化することは難しことが知られています。その理由の一つとして、モデル一般化のために実世界でのデータ収集が必要であることが挙げられます。
ロボット工学におけるモデル一般化するための課題として、 以下2つが挙げられます。
- 適切なデータセットの収集 - さまざまなタスクや設定をカバーする規模とその幅の両方を兼ね備えたデータセットが必要であること
- 適切なモデルの設計 - リアルタイムで動作するのに十分な効率性と、マルチタスク学習に適した大容量モデルが必要であること
これらの解決として、本記事で紹介する Robotics Transformer 1(以下、RT-1)は、ロボットのリアルタイム制御を行えるモデルを構築し、実世界での幅広いロボットタスクから得られるデータセットを使い、よりモデルの一般化に近づけています。
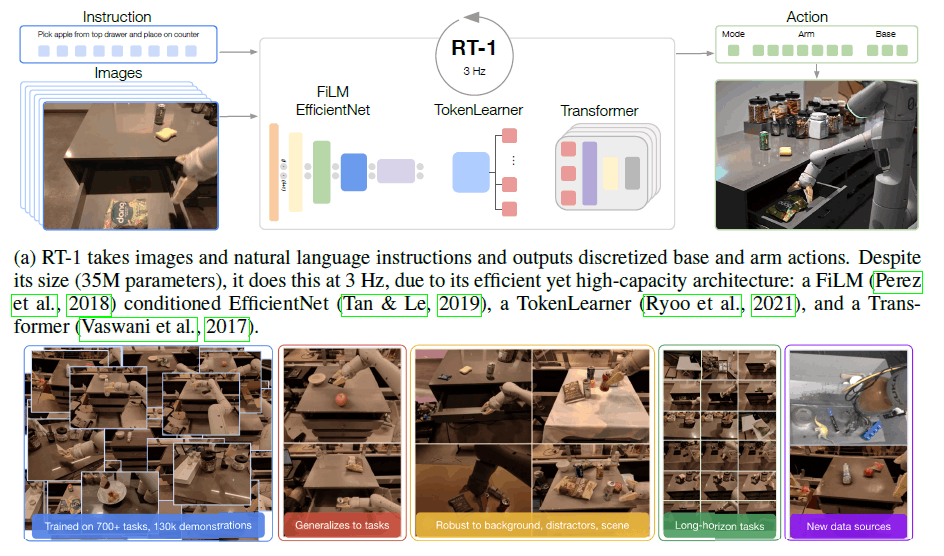
概要
この研究の目標は、大量のデータを取り込み、効果的に汎化できる一般的なロボット学習システムを構築し、その性能を実証することです。使用したロボットは、7自由度のアーム、2本指のハンドグリッパー、移動可能なベースを持つEveryday Robots社の移動式マニピュレータです。(下図(d))

RT-1は大量のデータを取り込み、効果的に汎化し、実用的なロボット制御のためにリアルタイムレートで動作を出力することができる効率的なモデルです。短い画像シーケンスと自然言語による指示を入力とし、各時間ステップでロボットのアクションを出力します。
RT-1のアーキテクチャ
以下に示す図はRT-1モデルのアーキテクチャです。モデルの構成要素について図の上から順に説明していきます。
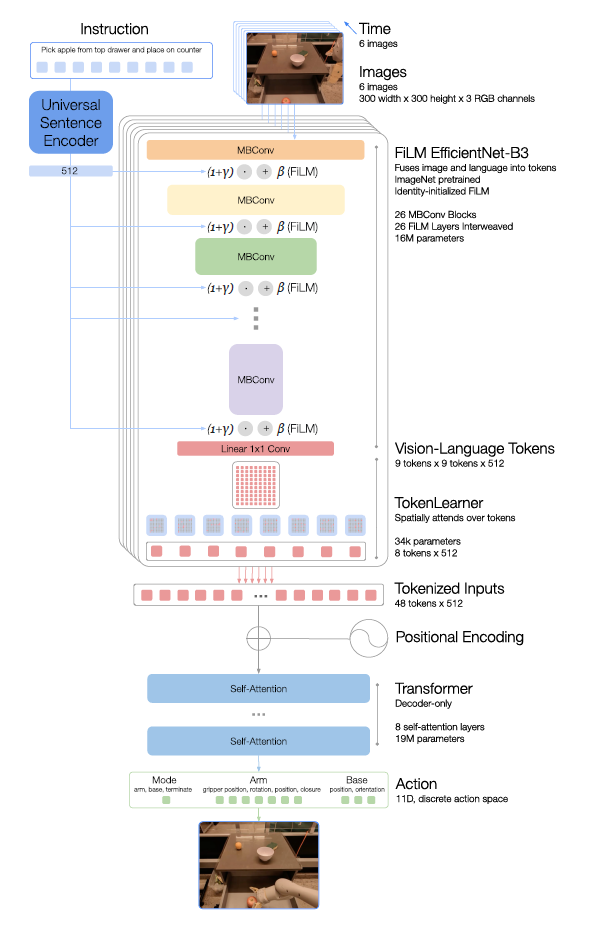
Instruction and image tokenization
RT-1アーキテクチャは、画像と言語命令のデータ効率的でコンパクトなトークン化に依存しています。Imagesには、解像度300×300の6枚の画像が入力され、 ImageNetの事前学習済みEfficientNet-B3モデルを通して、最後の畳み込み層から形状9×9×512の空間特徴マップを出力します。
Instructionには、命令として自然言語が入力されます。この命令は、Universal Sentence Encoderで自然言語処理され、画像エンコーダの条件付けのために事前学習されたEfficientNetに追加されるidentity-initialized FiLM layersの入力として使われます。
TokenLearner
RT-1がアテンションする必要のあるトークン数をさらに圧縮して、推論を高速化するためにTokenLearnerを使用します。TokenLearnerは、多数のトークンをより少ない数のトークンにマッピングすることを学習するElement-Wise Attentionモジュールです。これにより、重要なトークンの組み合わせのみをTransformer層に渡すことが出来ます。
Transformer
Transformerは、8つのself-attentionレイヤーと、19Mのパラメータを持つデコーダのみのシーケンスモデルであり、アクショントークンを出力します。
Action tokenization
アクションをトークン化するために、RT-1の各アクション次元は256ビンに離散化されます。ロボットアームの動きなどに定義した各変数について、ターゲットを256個のビンの1つにマッピングします。
Loss
関連研究の Transformerベースのコントローラで利用された標準的なカテゴリカルクロスエントロピーのエントロピー目的および因果関係マスキングを用います。
Inference speed
同じ動作を行う人間の速度(約2~4秒)に近い推論時間バジェットを100ms未満になるように設定します。
このような流れで、入力された画像と命令(自然言語)からロボットアームのアクションを生成します。 また、使用するデータセットと、ロボットに送る指示やロボットが行う行動(スキル)は以下の通りです。
データセット
主要なデータセットは、13台のロボットで17ヶ月かけて収集した~130kのロボットデモで構成されています。この大規模なデータ収集は、下の図(a)~(c)に示すように、オフィスキッチンで実施しました。また、下の図(e),(f)に示されるように、ロボットアームの動きに多様性を持たせるため様々なオブジェクトを用意しています。
スキルや指示
システムが実行できる言語命令の数をカウントします。命令は、1つまたは複数の名詞で囲まれた動詞に対応し、「水筒を立てて置く」、「コーラ缶を緑色のチップスの袋に移す」、「引き出しを開ける」などの文章となります。RT-1は、実験で評価し複数の現実のオフィスキッチン環境において、700以上の言語指示を実行することができます。
実験・結果
RT-1モデルの性能を図るため、以下の実験ポリシーを定めました。
- 見えているタスクの性能
- 見えていないのタスクの汎化
- ロバスト性
- ロングホライズンシナリオ
以上を踏まえ、Everyday Robotsのモバイルマニピュレータを用いて、2つの実際のオフィスキッチンと、これらの実際のキッチンを模したトレーニング環境の3つの環境でRT-1を評価しました。本記事では、RT-1とベースラインの性能比較と、データセットにシミュレーション環境上のデータを加えた場合の結果を掲載します。
RT-1とベースラインの総合的な性能比較
すべてのモデルはRT-1と同じデータで学習され、タスクセット、データセット、ロボットシステム全体を比較するものではなく、評価はモデルアーキテクチャを比較するだけです。

カテゴリーにおいて、RT-1は先行モデルを大きく上回っていることがわかります。見て行うタスクでは、RT-1は200以上の命令のうち97%を成功させることができ、これはBC-Zより25%、Gatoより32%も高い数値です。このような新しい指示への汎化は、ポリシーが既視概念の新しい組み合わせを理解することができます。また、すべてのベースラインも自然言語条件付けされており、原理的には同じ利点を享受することができます。
RT-1エージェントの軌跡の例として、異なるスキル、環境、オブジェクトをカバーする指示を含む軌跡を板の図に示します。

RT-1にシミュレーションデータを組み込んだ場合の実験結果

Real Onlyデータセットと比較して、シミュレーションデータを追加しても性能が落ちないことがわかります。しかし、シミュレーション上にあるオブジェクトやタスクの性能は、23%から87%へと大幅に向上し、実データとほぼ同じ性能となっています。また、未知の指示に対するパフォーマンスも7%から33%へと大幅に向上しています。これは、対象物を実機で確認したことと、未知の指示であることを考えると、興味深い結果となりました。
おわりに
RT-1は、 Data-Absorbentモデルによる大規模なロボット学習へ貢献する一方で、多くの制約を伴います。模倣学習法であるため、デモ機の性能を超えることができない可能性があるなどアプローチの課題を引き継いでいます。また、新たな指示への汎化は、既視概念の組み合わせに限られ、RT-1は全く未知の新しい動作に汎化することができません。
しかし、RT-1のバージョンアップにより背景や環境に対するロバスト性をさらに向上させることができます。そのため、RT-1はオープンソース化されており、誰でも発展に貢献することが出来ます。
研究者のみならず、企業や一般のユーザがRT-1の技術発展を担うことにより、様々な視点からモデルの構築が行え、さらに一般化が進むと考えます。様々な技術が融合し、ロボットモデルの一般化が出来れば、ロボットが街の中で当たり前に動いている日常も遠くなさそうです。




この記事に関するカテゴリー





