
Implicit Behaviral Cloning : 模倣学習の新しい定式化!ロボットの複雑な動作を実現!
3つの要点
✔️ 模倣学習での新しい定式化Implicit Policyを提案
✔️ これまでのExplicit Policyでは対処できない多峰性・離散的なケースに対応
✔️ 実機実験においても従来手法に比べて高い性能を発揮
Implicit Behavioral Cloning
written by Pete Florence, Corey Lynch, Andy Zeng, Oscar Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, Jonathan Tompson
(Submitted on 1 Sep 2021)
Comments: Published on arxiv.
Subjects: Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの,紹介スライドのもの,またはそれを参考に作成したものを使用しております.
はじめに
近年,ロボット学習に関する研究が盛んに行われており,多くの成果があげられています.中でも注目を浴びている手法の一つが模倣学習です.これは,人間などのエキスパートが実際にロボットを操作したデータ等から,方策を学習する手法です.模倣学習のメリットとして,報酬関数の設計が不要であることや,直接ロボットを操作したデータを使うことができるので,sim2realで問題になるモデル化誤差を考える必要がなくなるということ等があげられます.これらの利点もあり,適切に調整された模倣学習ベースの方策は実世界でもうまく動作を達成することができることが確認されており,活発に研究されています.
こちらの動画では,著者の方が実際に本研究の内容を説明しており,より理解が深まるかと思いますので是非ご覧ください.
既存研究と課題
Explicit Policy
模倣学習でこれまでよく用いられてきた手法は,Explicit Policyというものです.これは,とある観測からロボットの行動を生成する方策を連続関数としてモデリングする手法で,以下のようにあらわされます. このときθは,例えば人間の与えた軌道と方策の軌道との誤差を最小にするように求められます.
このときθは,例えば人間の与えた軌道と方策の軌道との誤差を最小にするように求められます.
しかし,このExplicit Policyでは以下のような二つの課題に対処することが難しいことが知られています.
Discontinuities(離散性)
これは行動系列などが離散的なケースを含むタスクの特性のことを指しています.以下の画像は,青いブロックを小さい箱に挿入するタスクのものですが,これを実現するには,一度左右から押して,その後奥から箱側に押すという形で,離散的に行動の系列を切り替える必要があります.しかし,連続的なモデリングであるExplicit Policyではこれを表現することができません.
Multimodalities(多峰性)
これは,目的を達成する手段が複数ある場合のことです.以下の画像では,青色と黄色のブロックを分けて2つの箱に入れるタスクを表していますが,目的を達成するには,動かすブロックは青色からでも黄色からでもよく,多峰性のあるタスクになっています.Explicit Policyでは,教えた軌道に近い行動を再現しようとするので,このような多峰性のあるタスクに対処することが難しくなります.
提案手法
これまでの既存研究での課題に対して,本論文では,模倣学習をこれまでとは違う形で再定式化しており,それが以下のImplicit Policyです.
Implicit Policy
具体的には,エネルギーベースモデル(EBM)というものを導入しています.これまでは,目標軌道との近さを測っていたのに対して,Explicit Policyでは,以下のように観測と行動に対するEBMを学習し,行動選択時には,観測した行動の中でEBMを最小化する行動を決定します. EBMにおいては,ある状態においてある行動を選択する確率を以下のようにあらわすことができます.ここで,z(x,θ)は正規化定数です.
EBMにおいては,ある状態においてある行動を選択する確率を以下のようにあらわすことができます.ここで,z(x,θ)は正規化定数です.
 しかし,zの計算のために全てのyについて計算することは難しいため,以下のようにサンプリング近似を行います.また,損失関数はこの確率の負の対数尤度で計算され,これらによって学習・推論が行われます.
しかし,zの計算のために全てのyについて計算することは難しいため,以下のようにサンプリング近似を行います.また,損失関数はこの確率の負の対数尤度で計算され,これらによって学習・推論が行われます.
特性
上記の定式化によって得られる特性について確認します.まず,以下の結果から離散性に対処できていることがわかります.不連続関数を教師データとして与え,それを正しく表現できるかという問題設定ですが,Explicit Policyではどうしても間を補完してしまうのに対し,Implicit Policyでは不連続な形で表現できています.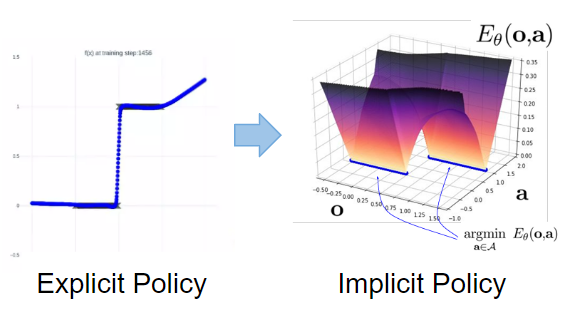 以下の図は,✕がサンプルを表しており,その関数を学習する問題設定を示しています.この問題では,多値関数や多峰性関数が存在し,これまでの手法では近似が困難であったものとなりますが,Implicit Policyはサンプル付近に値が集中しており,Explicit Policyに比べよりよく表現できていることがわかります.
以下の図は,✕がサンプルを表しており,その関数を学習する問題設定を示しています.この問題では,多値関数や多峰性関数が存在し,これまでの手法では近似が困難であったものとなりますが,Implicit Policyはサンプル付近に値が集中しており,Explicit Policyに比べよりよく表現できていることがわかります.
実験
Implicit Policyを用いて実際にロボット制御のタスクを行います.観測としては,画像入力やロボットの関節角・角速度・位置姿勢などがあり,行動としては,関節角の位置制御指令や速度制御指令が設定されています.
実験結果については,こちらで動画を確認できるので,ぜひご覧ください.
シミュレーション実験
様々なシミュレーション環境・タスクを用いて従来手法との比較を行っています.基本的にはほとんどすべてのタスクで従来手法を大きく上回る性能を出しています.
これらすべてのタスクが,離散性や多峰性を含むタスクとなっており,その特性に対処できるImplicit Policyの強みが確認できる結果になったと思われます.
実機実験
マニピュレータを用いて,ブロックを動かすいくつかのタスクを実機で行っています.まず,画像左のような,赤色と緑色のブロックをいずれのゴールに入れるタスクですが,従来手法では約55%の成功率にとどまっているところを,本手法では約90%の成功率を達成しています.このタスクは多峰性の強いタスクですが,Implicit Policiy特有の多峰性への対処が確認できています.次に画像中央のような,1mm単位で調整が必要なブロックの挿入タスクにおいては,図にあるように離散的に行動系列を切り替える必要があります.本タスクにおいても,Implicit Policyの特性から,従来手法に大きく差をつけ,約8割の成功率を記録しています.最後に画像右のような,沢山用意された青色と黄色のブロックを分けてゴールに入れるタスクについて実験しています.このような離散性と多峰性が複雑に組み合わさったタスクでも約50%の成功率を達成しており,学習した動作を組み合わせ,新たな動作を生成できていることが確認できます.また,人が手を加えてブロックを動かすなどしても,即座にロボットが対応してゴールの中に戻すという現象もみられ,得られた方策が非常にロバストであることが確認されています.
まとめ
本論文では,これまでの模倣学習の定式化(Explicit Policy)では対応できなかった離散性や多峰性に着目し,それらに対処できる新たな定式化(Implicit Policy)を提案しました.シミュレーション・実機の双方で実験を行ったところ,従来手法を大きく上回り,実機においても非常にロバストな性能が得られました.
改善点としては,従来のExplicit Policyに比べると計算コストが大きくなったことを挙げているため,さらに計算コストを落とすことができればもう少し動的なタスクもできるようになるかもしれません.
筆者としては,模倣学習の新たな扉が開いたようで,今後の展開が非常に楽しみです.






この記事に関するカテゴリー






