
3Dマップ上に直接ラベル付けして精度を向上するVLMaps
3つの要点
✔️ VLMap:実世界の3Dマップと、事前に学習されたVisual-Languageモデルの特徴量を組み合わせた空間地図表現
✔️ LLMと組み合わせることで移動ロボットの行動生成が行える
✔️ 広範な実験から既存の手法よりも複雑な言語命令に従ったナビゲーションが可能
Visual Language Maps for Robot Navigation
written by Chenguang Huang, Oier Mees, Andy Zeng, Wolfram Burgard
(Submitted on 11 Oct 2022 (v1), last revised 8 Mar 2023 (this version, v4))
Comments: Accepted at the 2023 IEEE International Conference on Robotics and Automation (ICRA)
Subjects: Robotics (cs.RO); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
近年、人工知能でロボットの行動生成を行う研究が盛んに行われています。例えば、人が移動ロボットに「机の上のりんごを持ってこい」と命令し、それを移動ロボットが持ってくるような行動生成が多いです。このような移動ロボットの行動生成には、命令を処理する自然言語処理、物体を認識するために画像処理の人工知能が使用されています。このようなナビゲーションでは、事前学習されたVisual-Languageモデルを使用することが出来ます。
しかし、既存のVisual-Languageモデルは、画像と自然言語によるオブジェクトゴールの記述とのマッチングには有用ですが、環境をマッピングするプロセスからは切り離されたままであるため、幾何学的マップの空間的精度に欠けてしまいます。
本記事で紹介するVLMapsは、これらの問題に対し、事前に学習されたVisual-Languageモデルの特徴量と、物理世界の3D再構成を組み合わせた空間地図表現です。
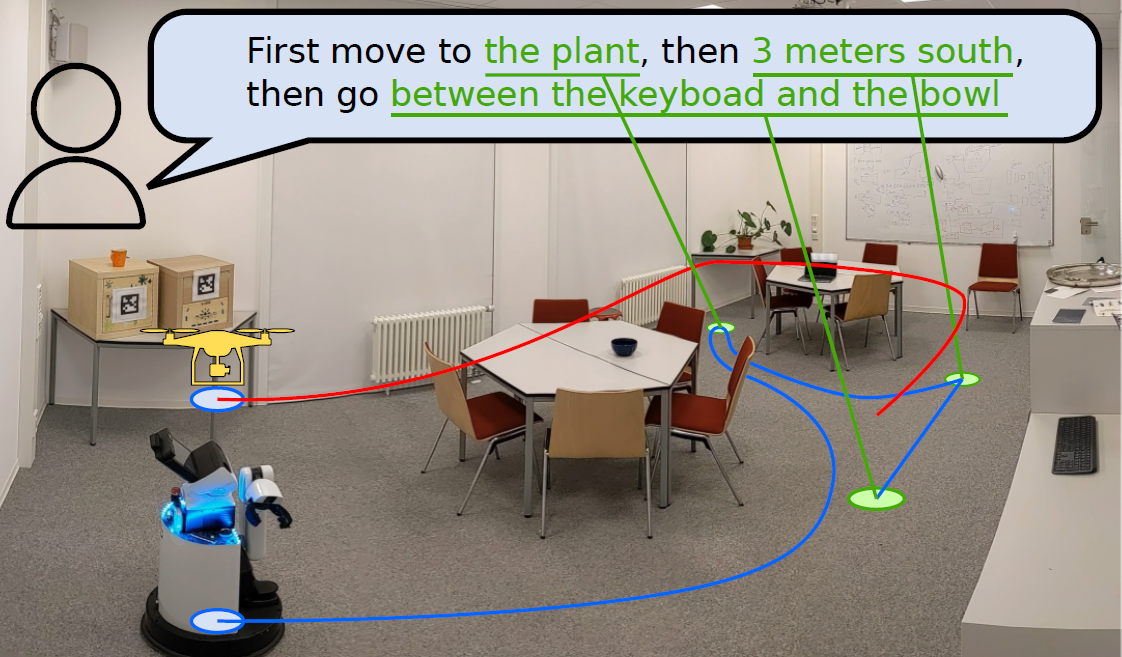
VLMapsの概要
VLMapsは、これらの問題に対し、事前に学習されたVisual-Languageモデルの特徴量と、物理世界の3D再構成を組み合わせた空間地図表現です。
標準的な探索アプローチを用いてロボットのビデオフィードから自律的に構築することができ、ラベル付けされたデータを追加することなくマップの自然言語インデクシングを可能にしています。

具体的には、大規模言語モデル(LLM)と組み合わせることで、以下のことが可能になります。
- 自然言語コマンドを、マップに直接ローカライズされたopen-vocabulary navigation goalsのシーケンスに変換します。例えば、「ソファとテレビの間」や「椅子の右3メートル」など。
- 新しい障害物マップを事前準備なしで生成するために、障害物カテゴリのリストを使用することで、異なる実施形態を持つ複数のロボット間で共有することができます。
VLMapsのメソッド
VLMapsの目標は、ランドマーク(「ソファー」)や空間参照(「ソファーとテレビの間」)を自然言語で直接特定できる空間視覚言語マップ表現を構築することです。VLMapsは、off-the-shelf visual-language models (VLMs)と、標準的な3D再構成ライブラリを用いて構築することが出来ます。
 それでは、VLMapsのメソッドを以下のセクションごとに分けて説明します。
それでは、VLMapsのメソッドを以下のセクションごとに分けて説明します。
- VLMapsの構築方法
- マップを使ってopen-vocabularyランドマークをローカライズする方法
- 異なるロボットの実施形態に対応した障害物カテゴリのリストからopen-vocabularyの障害物マップを構築する方法
- どのようにVLMapsを大規模言語モデル(LLM)と併用し、自然言語コマンドから実際のロボットのゼロショット空間ゴールナビゲーションを行うか
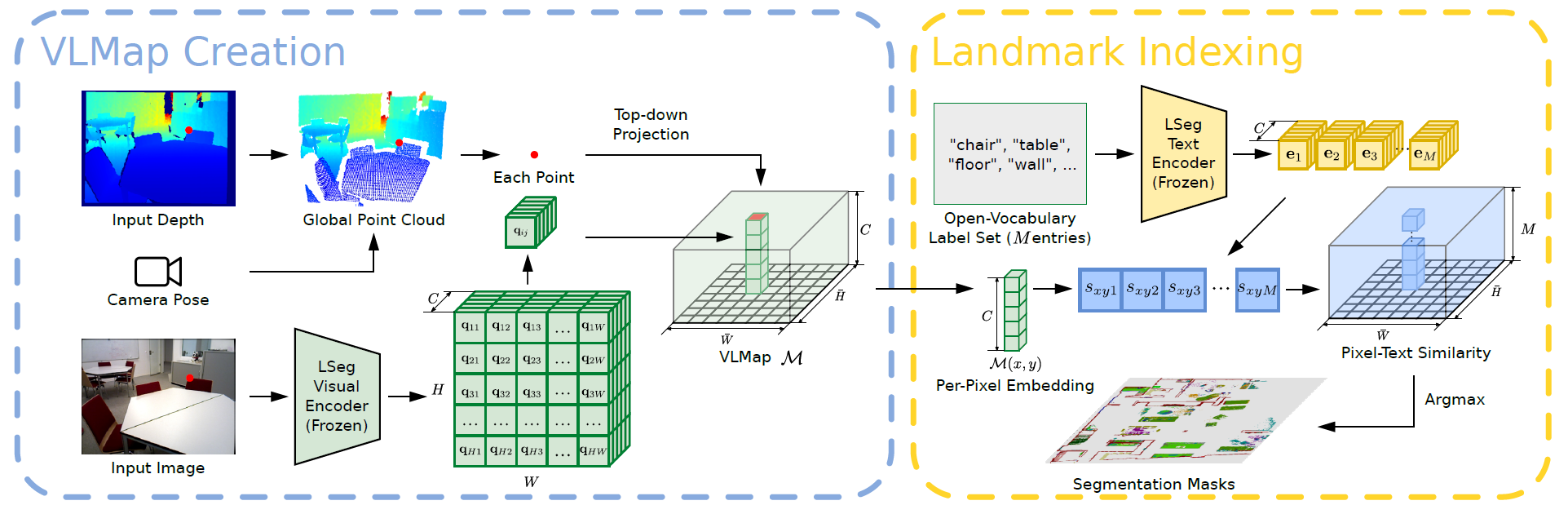
Building a Visual-Language Map
VLMapsの主なアイデアは、事前に学習された視覚言語特徴と3D再構成を融合させることです。これは、既存の視覚言語モデルからロボットのビデオフィード上で、高密度のピクセルレベルの埋め込みを計算し、深度データからキャプチャされた環境の3D表面上に逆投影することによって実現されます。
VLMapsでは、視覚言語モデルとしてLSegを利用します。LSegは、language-driven semantic segmentationモデルであり、自由形式の言語カテゴリ・セットに基づいてRGB画像をセグメンテーションします。
VLMapsのアプローチでは、LSegのピクセル埋め込みと、それに対応する3Dマップの位置と融合させます。これにより、明示的な手作業によるセグメンテーションラベルを用いず、VLMの汎化能力を持つ強力なlanguage-drivenの意味的事前分布を組み込みます。
ここで、HとWはトップダウングリッドマップのサイズを表し、Cは各グリッドセルのVLM埋め込みベクトルの長さを表す。スケール・パラメータsとともに、VLMapsMはH ×W メートルの大きさの領域を表します。
マップを構築するために、RGB-Dフレームごとに、すべての深度ピクセルuを逆投影し、ローカル深度点群を形成し、ワールドフレームに変換します。
点PWを地上面に投影し、グリッドマップ上の画素uの対応する位置を得ます。以下は、マップMにおける投影点の座標を表すpx mapとpy mapの数式です。
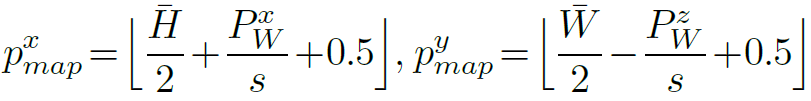
Localizing Open-Vocabulary Landmarks
ここでは、自由形式自然言語を使ってVLMapsのランドマークをローカライズする方法を説明します。
入力言語リストは、["椅子", "ソファ", "テーブル", "その他"]または["家具", "床", "その他"]のようなものです。このようなテキストリストをベクトル埋め込みリストに変換するため、事前に訓練されたCLIPテキストエンコーダを適用します。また、マップ埋め込みは行列に平天下されます。さらに、各行はトップダウングリッドマップにおける画素の埋め込みを表します。
最終的に得られた行列を用いて、グリッドマップの各画素について、最も関連性の高い言語ベースのカテゴリを計算します。
Generating Open-Vocabulary Obstacle Maps
VLMapsを構築することで、使用したVLM(LSegとCLIP)のopen-vocabularyの性質を継承した障害物マップを生成することができます。具体的には、自然言語で記述された障害物カテゴリのリストが与えられれば、衝突回避や最短経路計画のためのバイナリマップを生成するために、実行時にそれらの障害物をローカライズすることができるからです。このための顕著なユースケースは、異なる実施形態を持つロボット間で同じ環境のVLMapsを共有することで、マルチエージェント協調に有用である。
例えば、障害物カテゴリの2つの異なるリストを提供するだけで、1つは("テーブル "を含む)大型移動ロボット用に、もう1つは("テーブル "を含まない)ドローン用に、2つのロボットがそれぞれ使用する2つの異なる障害物マップを、同じVLMapsから事前準備なしに生成することができる。
そのために、まず障害物マップOを抽出します。ここで、トップダウン・マップにおける奥行き点群の各投影位置には1、そうでなければ0が割り当てられる。
床や天井からの点を避けるために、点PWはその高さに応じてフィルタリングされます。
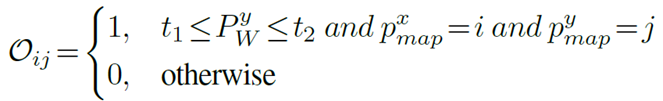
次に、ある実施形態に合わせた障害物マップを得るために、潜在的な障害物カテゴリのリストを定義します。open-vocabularyランドマークインデクシングを適用し、定義されたすべての障害物のセグメンテーションマスクを得ます。特定の実施形態に対して、潜在的な障害物リスト全体からクラスのサブセットを選択し、それらのセグメンテーションマスクの和を取って障害物マスクが得られます。Oの床領域上の障害物の誤った予測を、Oとの交点を取ることで無視し、最終的な障害物マップを得る。
Zero-Shot Spatial Goal Navigation from Language
このセクションでは、次のような自然言語の指示によって指定されたランドマーク記述のセットが与えられた場合の、ロングホライズン(空間的)ゴールナビゲーションに対する我々のアプローチについて説明する。

VLMapsでは、"テレビのソファーの間 "や "椅子の東3メートル "などといった正確な空間的目標を参照することができる。具体的には、LLMを使用して、入力された自然言語コマンドを解釈し、サブゴールに分解します。これらのサブゴールを言語で参照し、semantic translationやアフォーダンスを用いて、LLMのコード記述能力を活用することで、実行可能なロボット用のPythonのコードを生成します。
ロボット用コードは、関数や論理構造を表現し、API呼び出しをパラメータ化することができます。テスト時、モデルはその後、新しいコマンドを取り込み、APIコールを自律的に再構成して、それぞれ新しいロボットコードを生成することができます。
下の二つの図で、プロンプトは灰色、入力タスクコマンドは緑色、生成された出力は強調して表示されています。
 |
 |
LLMgは、言語コマンドで言及された新しいランドマークを参照するだけでなく、新しいAPI呼び出しシーケンスを連鎖させて、未知の命令に従うコードを生成します。
これにより、言語モデルによって呼び出されるnavigation primitive関数は、事前に生成されたVLMapsを使用して、事前にスクリプトで定義されたオフセットで修正されたマップ内のopen-vocabularyランドマークの座標を特定します。次に、身体固有の障害物マップを入力とする既製のナビゲーションスタックを使用して、これらの座標に移動します。
実験
本記事では、VLMapsのベースライン比較と、実際に移動ロボットに適応した結果を示します。
ベースライン比較
マルチオブジェクトゴールナビゲーションという標準的なタスクにおいて、最近のオープンボキャブラリーナビゲーションベースラインに対して、VLMapsアプローチを定量的に評価を行いました。
物体ナビゲーションを評価するため、91のタスクシーケンスを収集しました。各シーケンスにおいて、1つのシーンにおけるロボットの開始位置をランダムに指定し、サブゴールオブジェクトタイプとして30のオブジェクトカテゴリーから4つを選択します。
ロボットは、これら4つのサブゴールに順次ナビゲートすることが求められます。サブゴールの各シーケンスにおいて、ロボットが1つのサブゴールカテゴリーに到達したとき、その進捗を示すために停止アクションを呼び出す必要があります。
正しい物体からの停止位置の距離が1メートル以内であれば、1つのサブゴールへのナビゲーションは成功とみなします。
エージェントのロングホライズンナビゲーション能力を評価するために、1つから4つのサブゴールに連続して到達する成功率(SR)を計算しました(下図)。
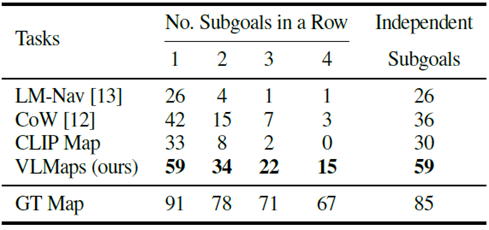
複数オブジェクトのナビゲーション(成功率[%])において、VLMapsアプローチは他のopen-vocabularyベースラインよりも高い結果を示し、特に複数のサブゴールを持つ長いホライズンタスクにおいて優れています。
また、LM-Navは、グラフノードに格納された画像で表現された場所にしかナビゲートできないため、性能は低いです。マップベースの手法をより深く理解するために、VLMaps、CoW、CLIP Mapによって生成されたオブジェクトマスクを、GTと比較して、下図に示します。

CoW(図:4d)とCLIP(図:4c)によって生成されたマスクは、どちらもかなりの偽陽性予測が含まれています。プランニングは最も近いマスクされた目標領域への経路を生成するため、これらの予測は誤った目標に向かうプランニングにつながります。これに対し、図:4eに示すVLMapsで得られる予測はノイズが少なく、物体ナビゲーションの成功率が高くなりました。
移動ロボットでの実験
また、HSR移動ロボットを用いて、自然言語コマンドによる屋内ナビゲーションの実世界での実験を行いました。10以上の異なるクラスのオブジェクトを含む、意味的に豊かな屋内シーンでVLMapsをテストしました。テスト用に20種類の言語ベースの空間目標を定義しています。
推論中、RTAB-Mapのグローバルローカリゼーションモジュールも使用してロボットポーズを初期化する。
その結果、「椅子と木箱の間に移動する」や「テーブルの南に移動する」のような空間目標で6つの試行、「3メートル右に移動してから2メートル左に移動する」のようなロボットの現在位置からの相対的な目標で3つの試行で成功しました。
おわりに
いかがでしたか?今回取り上げたVLMapsは、事前学習済みのVisual-Languageモデルの特徴量を3Dマップに直接適応するため、オブジェクトがマップ上のどこにあるのか明示的に認識できるものでした。今後は、他の情報を追加し、さらに精度上げる方向へ研究が進むと考えられます。
また、LLMと組み合わせることで移動ロボットの行動生成を実現しています。将来的に、ロボットの行動生成だけでなく、自動車の自動運転への適用も考えられそうです。






この記事に関するカテゴリー





