CycleGanをRLに統合したsim2real transfer
3つの要点
✔️ 新たなsim2realの手法 RL-CycleGANの提案
✔️ RL-scene consistency lossによりタスク情報を保持したまま画像の生成が可能
✔️ 物体を掴むタスクにおいて高い成功率を達成
RL-CycleGAN: Reinforcement Learning Aware Simulation-To-Real
written by Kanishka Rao, Chris Harris, Alex Irpan, Sergey Levine, Julian Ibarz, Mohi Khansari
(Submitted on 16 June 2020)
Comments: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2020)
Subjects: Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
Paper Official Code COMM Code
はじめに
本記事では、CVPR 2020でアクセプトされました、RL-CycleGANという手法を使ったロボットのSim2Real Transferについて紹介します。近年、Deep Reinforcement Learning (深層強化学習)を使ったロボットのpolicy (方策)の学習が注目されており、手動による細かい設定なしに、画像の入力を用いて物体を掴むことが出来るようなpolicyを学習することに成功しています。しかし、このDeep Reinforcement Learningを使った手法は、policyを学習するために多くの学習データを集めなければならず、実世界においてロボットを直接学習するのがとてもコストがかかるという問題点があります。そこで、近年注目されている手法として、シミュレーションを用いて予めpolicyを学習し、その学習したpolicyを現実世界に転移させる、sim2real transferというものが注目されています。しかし、simulationは基本的に現実世界の状況に完全に合わせることは難しく、近づけるためにもそのタスク特有のドメイン知識や、それを元とした手動による細かいシミュレーションの調整が必要だったりします。このようなプロセスを自動化させるために、シミュレーション画像を実世界の画像に変換するgenerative model (生成モデル)を学習する手法が考えられますが、これは基本的にtask-agnostic、つまり学習されるタスクに関して既知ではない生成モデルができあがり、最終的に解きたいタスクに関する情報が考慮されない可能性があります。そこで、本論文は、画像をシミュレーションから現実世界のものに変換する際に、RL-scene consistency lossと呼ばれるものを導入することで、タスクに必要な情報を考慮したgenerative model、RL-CycleGANという手法を提案しました。本記事では、この手法についてより詳しく説明していきます。
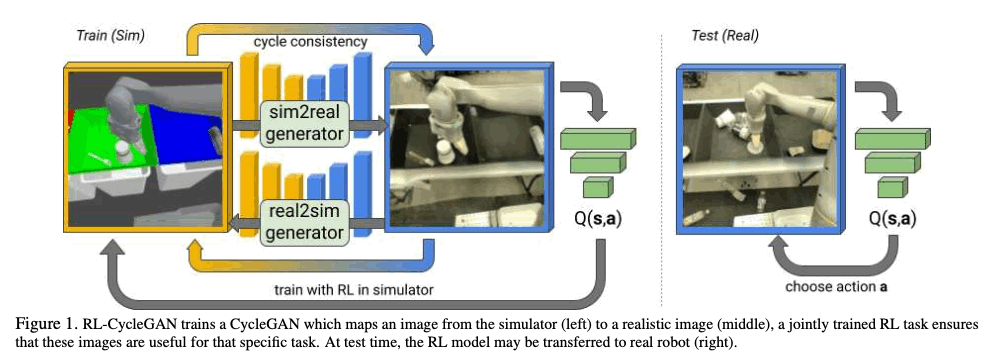
手法
CycleGAN
まずはじめに、提案手法における重要なベースとなるモデルであるCycleGANについて紹介します。CycleGANは、異なる2つのドメイン$X$と$Y$のマッピングに関して、ペアではないデータ$\left\{x_{i}\right\}_{i=1}^{N} \in X$ and $\left\{y_{i}\right\}_{i=1}^{M} \in Y$から学習する手法です。Sim2RealにおけるCycleGANは、ドメイン$X$と$Y$がそれぞれsimulationとrealと表すことができます。CycleGANは2つのgenerator(生成器)、Sim2Real $G: X \rightarrow Y$と Real2Sim $F: Y \rightarrow X$で成り立っています。そして、2つのdiscriminator (鑑別器)のうち、$D_{X}$がsimulation画像 $\{x\}$とrealの画像を元に生成された画像 $\{G(y)\}$を識別し、そして$D_{Y}$がrealの画像 $\{y\}$とsimulationの画像を元に生成された画像$\{F(x)\}$を識別します。そしてadversarial lossがこの2つのマッピングに対して適用され、GANのロス関数は以下のように表すことができます。$$\begin{aligned} \mathcal{L}_{G A N}\left(G, D_{Y}, X, Y\right)=& \mathbb{E}_{y \sim Y}\left[\log D_{Y}(y)\right] \\ &+\mathbb{E}_{x \sim X}\left[\log \left(1-D_{Y}(G(x))\right)\right] \end{aligned} $$
そのうえで、CycleGANでは、$x \rightarrow G(x) \rightarrow F(G(x)) \approx x$と$y \rightarrow F(y) \rightarrow G(F(y)) \approx y$の関係が成り立つような以下のロス関数が追加されます。$$\begin{aligned} \mathcal{L}_{c y c}(G, F)=& \mathbb{E}_{x \sim \mathcal{D}_{s i m}} d(F(G(x)), x) \\ &+\mathbb{E}_{y \sim \mathcal{D}_{r e a l}} d(G(F(y)), y) \end{aligned} $$ ここで、dは距離関数を表しており、本論文では平均二乗誤差を用います。
RL-CycleGAN
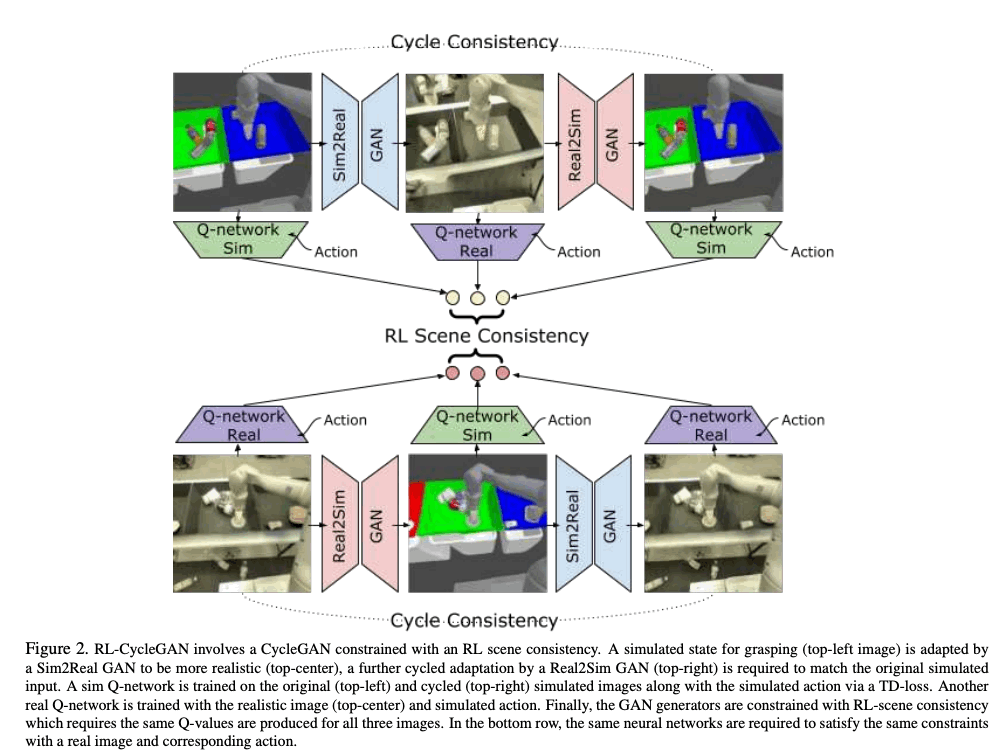
本論文において重要なポイントは、simulationからrealへと画像を変換させる際に、RLのタスクに関する情報を保持するようにしてあげることです。例えば、物体を掴むタスクにおいて、従来のCycleGANなどを使っても現実的な画像を生成することはできますが、仮に物体の変換が難しかった場合に、その物体の詳細などが生成画像から抜けてしまう可能性があります。これは、物体を掴むタスクにおいてとはとても重要な情報なので、このようなRL taskに関連する情報がしっかりと生成されることを促さなければなりません。RL modelの出力はタスクのセマンティクスに依存するべきと考えられるため、GANをRLのmodelを使って制約をかけることで、GANがタスク特有の情報を保持することを狙います。
RLのタスクに関してはdeep Q-learning network $Q(s, a)$が用いられ、$s$が入力画像、$a$がactionを表します。RL-CycleGANでは、simulationとrealの両方に関してQ-functionが学習され、それぞれ$Q_{sim}(s, a)$、$Q_{real}(s, a)$と表されます。RL-CycleGANでは、RL modelとCycleGANが同時に学習され、入力となる6枚の画像 $\{x, G(x), F(G(x))\}$と$\{y, F(y), G(F(y))\}$が$Q_{sim}$と$Q_{real}$に渡され、以下の6つのQ-valueが計算されます。
$$\begin{equation*}\begin{split}{c}(x, a) \sim \mathcal{D}_{\operatorname{sim}},(y, a) \sim \mathcal{D}_{\text {real}}q_{x}&=Q_{\operatorname{sim}}(x, a)q_{x}^{\prime}\\&=Q_{\text {real}}(G(x), a)q_{x}^{\prime \prime}\\&=Q_{\operatorname{sim}}(F(G(x)), a)q_{y}\\&=Q_{\text {real}}(y, a)q_{y}^{\prime}\\&=Q_{\operatorname{sim}}(F(y), a)q_{y}^{\prime \prime}\\&=Q_{\text {real}}(G(F(y)), a)\end{split}\end{equation*}$$
ここで、$\{x, G(x), F(G(x))\}$と$\{y, F(y), G(F(y))\}$と$Q_{sim}$と$Q_{real}$はそれぞれ同じ画像を表すので、それを入力としたQ-valueも同じような値でなければなりません。これを促すために、RL-scene consistency lossと呼ばれる以下のロス関数が利用されます。
$$\begin{aligned} \mathcal{L}_{R L-\text {scene}}(G, F)=& d\left(q_{x}, q_{x}^{\prime}\right)+d\left(q_{x}, q_{x}^{\prime \prime}\right)+d\left(q_{x}^{\prime}, q_{x}^{\prime \prime}\right)+d\left(q_{y}, q_{y}^{\prime}\right)+d\left(q_{y}, q_{y}^{\prime \prime}\right)+d\left(q_{y}^{\prime}, q_{y}^{\prime \prime}\right) \end{aligned} $$
ここで、dは距離関数を表し、平均二乗誤差を表します。SimualtionとRealの画像は大きく異なる可能性もあるので、一つのQ-networkを使うのではなく、simulationとrealそれぞれ別のQ-networkを学習します。このQ-networkは通常のTD-lossである以下のロス関数を利用して学習されます。
$$ \mathcal{L}_{R L}(Q)=\mathbb{E}_{\left(x, a, r, x^{\prime}\right)} d\left(Q(x, a), r+\gamma V\left(x^{\prime}\right)\right) $$
これら全てのロス関数を合わせることで、最終的に以下の関数でRL-CycleGANのロス関数を表すことができます。
$$ \begin{array}{l} \mathcal{L}_{R L}-C y c l e G A N\left(G, F, D_{X}, D_{Y}, Q\right)&=\lambda_{G A N} \mathcal{L}_{G A N}\left(G, D_{Y}\right)\\&+\lambda_{G A N} \mathcal{L}_{G A N}\left(F, D_{X}\right)+\lambda_{c y c l e} \mathcal{L}_{c y c}(G, F)\quad\\&+\lambda_{R L-s c e n c e} \mathcal{L}_{R L-s c e n e}(G, F)+\lambda_{R L} \mathcal{L}_{R L}(Q) \end{array} $$
以下の画像はRL-CycleGANのモデルを表しています。全てのモデルは、distributed Q-learning QT-Opt algorithmを用いて学習されます。そして、RL-CycleGANが学習された後は、$Q_{real}$が現実世界のロボットを動かすためのpolicyのために使われます。
実験
タスクに関して
本論文での実験では2つのタスクについて考えられています。本実験では、Kuka IIWAと呼ばれるロボットを用いて、様々な物体を掴むタスクに関して挑戦をしています。本節では、本論文で行われる2つのタスクについて紹介します。
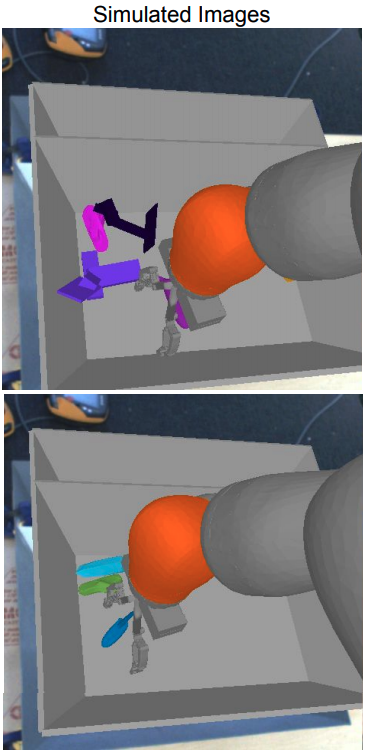
Robot 1 Setup: このタスクでは、一つのbin内にある様々な物体を掴むことに関してモデルを学習した後に、6つ未知の物体を掴むことが出来るかどうかを指標として評価します。モデルを学習するための現実世界のロボットのデータは、すでに学習されたモデルを利用する、もしくはスクリプトを書くことによって集められます。シミュレーションは以下の画像の様に、現実味があまりない環境であるために、simuationで学習されたpolicyを現実世界のロボットに対して利用しても低いパフォーマンスを示します。
Robot 2 Setup: 2つめのタスクでは、以下の画像の様な3つの隣り合ったbinを用いた環境で実験をします。この実験では、ロボットがbin手前にランダムに配置され、どのbinからでも物体を掴むことが出来るかを確かめることによって、位置やカメラの角度に関する汎化性能について調べます。このタスクでは、以下の図のような、single-bin graspingとmulti-bin graspingの2つに関して評価され、single-bin graspingは、ロボットが中央のbinに固定された上で、成功率を評価するものに対して、multi-bin graspingはロボットがbin手前でランダムに配置された上での成功率を評価をします。


Robot 1の結果
下のテーブルはRobot 1に関するタスクに関する評価で、未知の物体を掴むことができたかの成功率で各手法が比較されています。まずはじめに、本論文での提案手法を評価するために、いくつかのベースラインとなるものを紹介します。1つ目は、simulationでのみ学習したpolicyを現実世界のロボットに対してadaptationなしで利用する場合です。これは、下図のテーブルが示すように成功率が21%ととても低いことから、simualtionとrealのギャップが大きいことを示しています。次の、Randomized Simと呼ばれるものは、ロボットのarm、物体、bin、そして背景などの画像をランダムに変えることによって、未知の画像の入力に対する汎化性能を上げるというものです。この手法はSim-Onlyの場合より成功率が高くなっていますが依然と低いままとなっています。その他のベースラインとして、いくつかのGANを使ってsimulationからrealへのマッピングを学習し、simulationから得られる画像をGANを用いて変換したものを利用してpolicyを学習するものです。その結果、RL-CycleGANが他の手法と比べて高い成功率を示していることが分かります。これは、下図の変換された画像から分かるように、RL-CycleGANはタスクに重要な部分を変換できているのに対して、他の手法は、重要である物体が消えてしまった状態で画像が生成されるという結果になっています。このことから、RL-CycleGANがタスクにとって重要な情報を保持しつつ、画像を生成することができるということが分かりました。


Real dataの量とパフォーマンスの関係性
RL-CycleGANでは、realのデータを学習に必要とし、前節での実験では、realのデータをGANの学習のみに利用して、RLの学習ではsimulationのデータをGANを通して変換して利用しました。本実験では、realのデータをRLの学習にも使う、つまりrealのoff-policyデータと、GANを通して変換されたon-policyデータの両方を使って学習する場合、realの学習データが増えたときに物体を掴むタスクの成功率がどのように変化するかを、タスク Robot 1とRobot 2において比較しました。下のテーブルはRobot 1のタスクにおける結果を表しており、realのデータが増えることによって、成功率が大きく改善していることが分かります。

また、下のテーブルはRobot 2のタスクに関する実験の結果を表しており、RL-CycleGANを使うことで、3000 episode分のデータという少なめのデータ数でも成功率が17%から72%と、adaptationなしでsimulationとrealのデータを使うだけの場合と比べて大きく成功率が上がっているのが分かります。またRobot 1のタスクの結果と同様に、データの数を増やすことにより、RL-CycleGANを使った場合の成功率が大きく上がっていることが分かります。また、single-binとmulti-bin graspingの結果を比較した際に、同じreal dataの数あたりの成功率がほとんど同じことから、異なる場所、カメラの角度に対しても良い汎化性能があることを示しています。

Fine-tuningに関して
本実験では、学習されたpolicyを使って、さらにreal data (on-policy data)を集めてfine-tuningをする場合についての実験です。この実験をRobot 1のタスクに関して行われました。この実験ではRCANと呼ばれるon-policy dataのみを使ったsim2realの手法と比較します。RCANはon-policyデータのみで、fine-tuningなしで70%の成功率を示し、その上で成功率94%に達するために28000episode分のデータが必要であるのに対し、RL-CyclceGANは、10000episode分のデータで同様の成功率に達することができたことから、少ないデータでより高い成功率を出すことが出来るという利点があることが分かりました。RL-CycleGanを学習するにはoff-policyデータが必要ですが、本実験ではその量を制限し、5000episode分のデータのみを使って学習させています。

まとめ
本論文ではSim2RealをCycleGANとRLを組み合わせて、RLのタスクに関する情報を保持したまま、simulationからrealへの画像のマッピングを行えるようにしたことで、ロボットが物体を掴むタスクにおいて、高い成功率を出すことを示しました。現実世界でpolicyを学習することは、とてもコストがかかり、かつ安全面にも懸念があるために、sim2realはとても重要な課題となっており、現在もこの分野に関する研究が盛んに行われていますので、今後の動向に期待していきたいです。




この記事に関するカテゴリー






