強化学習は、実機ロボットで複雑なタスクが解けるのか?
3つの要点
✔️ Feedback ControllerとRLを組み合わせることにより、実機で複雑なマニピュレーションタスクを解ける手法の提案
✔️ ノイズなど不確かさに対してもロバストであることを示す
✔️ RLのみと比較して、高いサンプル効率性かつパフォーマンスを達成
Residual Reinforcement Learning for Robot Control
written by Tobias Johannink, Shikhar Bahl, Ashvin Nair, Jianlan Luo, Avinash Kumar, Matthias Loskyll, Juan Aparicio Ojea, Eugen Solowjow, Sergey Levine
(Submitted on 7 Dec 2018 (v1), last revised 18 Dec 2018 (this version, v2))
Comments: Accepted at ICRA 2019.
Subjects: Robotics (cs.RO); Machine Learning (cs.LG)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
ロボットは、製造業において繰り返し行うタスクを行わせていますが、多様なタスクそして不確かさに対して弱いという欠点があります。ロボットをコントロールする方法として、よく使われるものにPID制御などがあり、予め決められた軌跡に沿うようにコントロールすることが出来ます。多くの製造に関するタスクにおいて、不確かさなどに対する適応や環境に対するフィードバックが必要になりますが、これに対応するためのfeedback controllerをデザインするのはとてもコストが掛かります。これは、軌跡に沿うだけではなく、物体との接触やその際に起きる摩擦などを考慮してfeedback controllerをデザインしなければならず、例えそれらしい物理モデルが与えられても、接触などの物理パラメーターを決定するのはとても困難であるからです。また、このようなコントローラーを使った場合、予めデザインされた範囲内で動くので、汎用性が低くなるという欠点もあります。
それに対してReinforcement learning (RL)は、環境とのインタラクションから学習していくため、接触を伴うタスクなどを解くことができるとともに、汎用性にもある程度期待が持てます。しかし、RLはロボットを学習させるために、非常に多くのサンプルが必要になるという問題を抱えており、特に実機を使っての学習だと非常に困難です。また、RLは学習をするために探索が重要になりますが、実機での実験では安全性の問題が伴います。よって、本論文では従来のfeedback controllerでは解くことが難しいような制御問題を取り扱いますが、RLのみで解くのではなく、部分的にfeedback controllerを使って解きますが、その他の部分(residual)、例えば物体との接触が伴うような部分はRLを使って解くようにします。本論文の主なcontributionは、従来のfeedback controllerとRLを組み合わせる手法の提案で、本記事ではこの手法と実機での実験においてどのようなパフォーマンスを示したかを紹介していきます。
手法
では、どのように従来のfeedback controllerとRLを組み合わせるのでしょうか。下図はその大まかな手法の図を表しています。下図のように、RLによって学習されるpolicyのactionと予め定義されたcontrollerによるactionを足し合わせた結果がrobotのactionとして利用され、最終的に報酬の最大化を行うよう学習していきます。右図はそれを利用して解いたassemblyタスクの様子を示しています。手法のベースはこのようになっていますが、本章ではもう少し詳しく説明していきます。

Residual Reinforcement Learning
殆どのロボットを用いたタスクにおいて、報酬関数は以下のように考えることが出来ます。
$$r_{t} = f(s_{m}) + g(s_{o})$$
ここで、$s_{m}$はロボットの状態、$s_{o}$は物体の状態を表しています。$f(s_{m})$はロボットの状態の幾何学的な関係性を表したもので、例えばロボットのグリッパーを操作したい物体に近づけるための報酬などを表しています。そして$g_{s_{o}}$は物体の状態に付いての報酬で、例えば物体を垂直に保ったままにする報酬などが考えられます。
このように分けたときに、従来のfeedback controllerは、$f_{m}$を最適化するのには向いているのに対して、物体との接触を伴う$g(s_{o})$の最適化はRLが適していると考えられます。この2つの利点を活かすために、agentのactionを以下のようにします。
$$u=\pi_{H}(s_{m}) + \pi_{\theta}(s_{m}, s_{o})$$
ここで、$\pi_{H}(s_{m})$は人間によってデザインされたコントローラーを表し、$\pi_{\theta}(s_{m}, s_{o})$はRLにより学習されたpolicyで$\theta$はパラメーターを表しています。デザインされたfeedback controller $\pi_{H}$は$f(s_{m})$を素早く最適化することが出来るために、より高いサンプル効率性を達成することが出来ます。また、Feedback controllerによって発生するエラーをResidual RLによって補うことが出来、最終的にタスクを解くことが出来るようになります。
以下は手法のアルゴリズムを表しており、RL methodとしてTwin delayed deep deterministic policy gradients (TD3)を用いて学習を行いました。

実験
本実験では以下のようなことについて確かめていきます。
- Hand-designed controllerを利用することで、RLのサンプル効率性とパフォーマンスが向上するかどうか? また、不完全なhand-degisned controllerに対してもrecoveryができるかどうか?
- 提案手法が、様々な環境に対しても解くことができるかどうか?(汎用性)
- ノイズが含まれるようなシステムにおいても、タスクを解くことができるかどうか?
これらを確かめるためにシミュレーション環境と実機環境の2つにおいてAssemblyタスクに関する実験を行いました。どちらも同じタスクを解くことを目的としており、2つのブロックの間にロボットのグリッパーが掴んでいるブロックを挿入するタスクになります。ではシミュレーション環境と実機環境において異なる設定部分について以下で紹介します。
シミュレーション環境: シミュレーション環境においては、Cartesian-space position controllerを用いてロボットのコントロールを行いました。ブロックの挿入を可能にするために、2つのブロックは十分な程の隙間が空くようにしています。報酬関数は以下のように表されます。
$$r_{t} = -||x_{g} - x_{t}||_{2} - \lambda (||\theta_{l}||_{1} + ||\theta_{r}||_{1})$$
ここにおいて、$x_{t}$は現在のブロックの位置、$x_{g}$はゴールの位置、$\theta_{l}$と$\theta_{r}$は左と右のブロックの角度(y-axis)、$\lambda$はハイパーパラメーターを表しています。

実機環境: 実機実験では、ロボットのコントローラとして、compliant joint-space impedance controllerを用いました。タスクはシミュレーション環境と同様のタスクですが、物体などのground truthの位置座標などをagentが受け取る代わりに、カメラによるトラッキングシステムを利用して得られる推定された座標を受け取ります。報酬関数は以下のものを利用しました。
$$r_{t}=-\|x_{g}-x_{t}\|_{2}-\lambda(\|\theta_{l}\|_{1}+\|\theta_{r}\|_{1})$$
$$-\mu\|X_{g}-X_{t}\|_{2}-\beta(\|\phi_{l}\|_{1}+\|\phi_{r}\|_{1})$$
ここで$x_{t}$ はエンドエフェクターの座標、$x_{g}$はゴールの座標、$X_{t}$は立っているブロック両方の現在の座標、$X_{g}$は物体の希望する位置、$\theta_{l}$、$\theta_{r}$は右と左の物体のy-axis方向の角度、$\phi_{l}$と$\phi_{r}$はz-axis方向に対する右と左の物体の角度を表しています。$\lambda$、$\mu$、$\beta$はそれぞれハイパーパラメータを表しています。

本実験では比較対象として、RLのみを用いてタスクを解いた場合(Only RL)と提案手法であるResidual RLを比較をしました。
Residual RLのサンプル効率性
下は、シミュレーション環境と実機環境における、Only RLとResidual RLの実験結果を表しています。下図の通り、どちらにおいてもResidual RLの方がパフォーマンスが高く、かつ少ないサンプル数で高い成功率を示していることから、サンプル効率性が高いことが伺えます。これはResidual RLとは異なり、Only RLの場合はposition controlに関する問題を環境とのインタラクションを通して一から学習しなければならず、それによりサンプル効率性が悪くなるということが言えます。特に実機を用いた実験の場合、サンプル効率性の問題はとても重要になってくるため、Residual RLが特に実機の問題を解くのに適していることが伺えます。
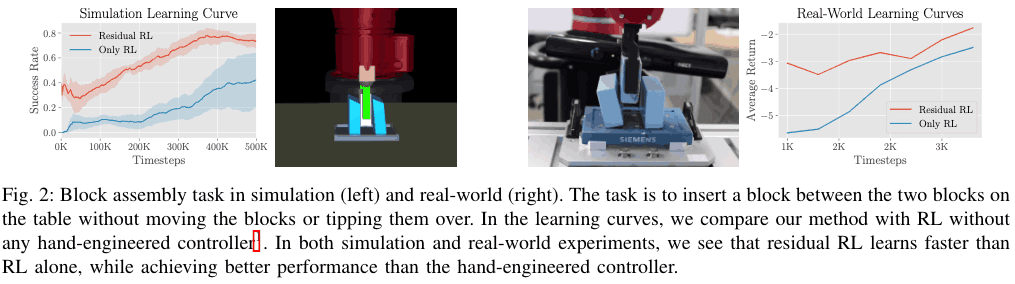
様々な環境における効果
仮に、2つのブロックの間が十分に空いており、2つのブロックの初期位置にエラーがない場合はHand-engineered controllerを用いても高い成功率で解くことが出来ます。それに対して、エラーがある場合はhand-engineered controllerでは解くことが難しく成功率が下図(a)のテーブルの通り、2/20で、それに対してresidual RLを用いた場合は15/20と高い成功率を示しています。これは解く際に、グリッパーが手にしているブロックを挿入するために、置いてあるブロックを倒さず正しい場所に動かす必要があり、これをhand-engineered controllerに手動で設定するのはとても困難であるのに対して、Residual RLは上手くそのような状況に対応することが出来ました。その結果が、下図の(b)のグラフであり、8000のサンプルをたった3時間のみで、実機での学習が出来たことから、高いサンプル効率性が伺えます。
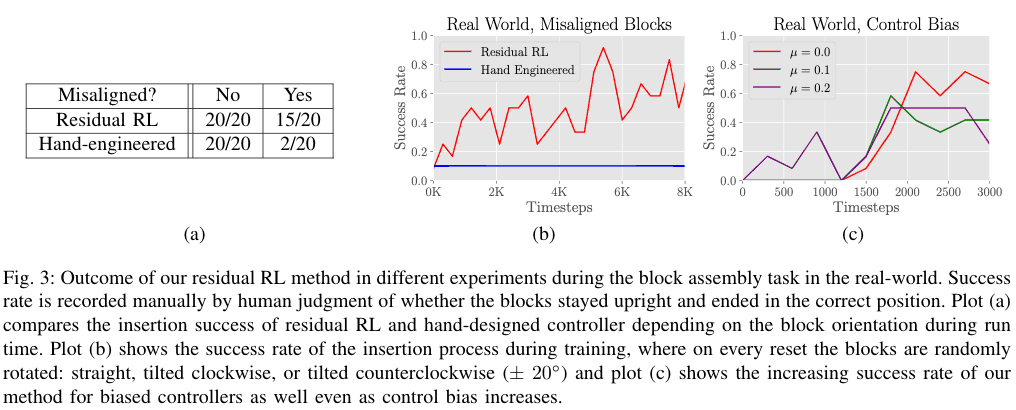
コントロールノイズからのRecovering
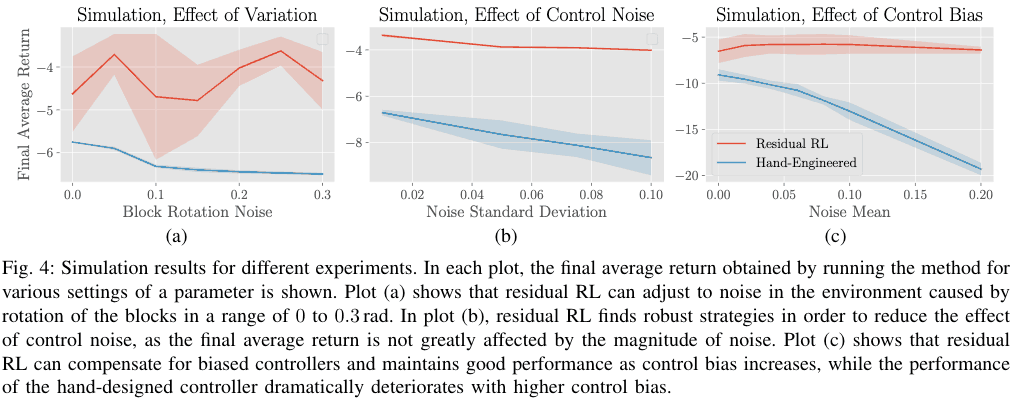
ここでは、バイアスがあるコントローラを用いた際や、control noiseがある場合における、Residual RLとHand-engineered controllerのみとの比較を行いました。下図の(b)はcontrol noiseが含まれている場合で、hand engineered controllerの報酬が大きく下がっているのに対して、Residual RLの場合はあまり減少していないことからよりnoiseにロバストであることが言えます。また同様に、バイアスがあるコントローラーを用い場合もHand-engineered controllerのパフォーマンスがノイズが大きくなるごとに急激に下がっているのに対して、Residual RLの場合はパフォーマンスの低下が見られないことから、sensor driftなど実機などで起こりうる問題などに対しても対処できる可能性を示すことが出来ました。
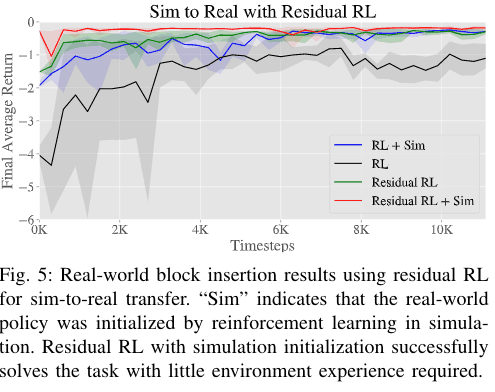
Residual RLにおけるSim-to-Real
Sim-to-Realの実験において、Residual RL policyをシミュレーションで初期化した上で、実世界の環境に転移した場合、Residual RLを実機でのみで学習したときやRLのみの場合と比較して素早くタスクを解くことができるようになることが分かりました。よって、難しい接触が伴うタスクを解く際において非常に有効な手段であると考えられます。
まとめ
強化学習を用いてロボットのタスクを解くことを目的とした論文の多くは、サンプル効率性の問題から実機での学習が困難であるということからシミュレーションのみの結果が載せてある場合が多いです。本論文では、サンプル効率性を向上させ、実機での学習でも可能にするために、従来のfeedback controllerと強化学習を組み合わせました。このように最近では、その他にもmotion planningとRLを組み合わせたりと従来ならではの手法と、RLを組み合わせることによりサンプル効率性を向上させることを目指すような論文が増えてきています。今後はよりシミュレーションではなく、実機においてRLをどのように使うことが一番効果的かを模索するのが重要なのではないかと感じています。



この記事に関するカテゴリー






