
DayDreamer: Dreamerがついに実ロボットに!
3つの要点
✔️ Dreamerが実世界の4つのロボットに対して学習することが出来ることを示した
✔️ 4足歩行ロボットを1時間程度で背中を地面に向けた状態から回転して立ち上がり、前進する事を可能にした
✔️ 画像を入力としてロボットが物体を掴み、そして別の場所に置くことを、sparse rewardを用いて学習することができた
DayDreamer: World Models for Physical Robot Learning
written by Philipp Wu, Alejandro Escontrela, Danijar Hafner, Ken Goldberg, Pieter Abbeel
(Submitted on 28 Jun 2022)
Comments: Published on arxiv.
Subjects: Robotics (cs.RO); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
ロボットを学習させて実世界の複雑なタスクを解く事が近年、ロボティクスの研究で注目されています。特にDeep reinforcement learning (RL) はトライ・アンド・エラーを繰り返すことにより、ロボットの行動を向上させ最終的に複雑なタスクを解くことが可能になってきています。しかし、Deep RLを用いてロボットを学習させるには長時間の環境とのインタラクションが不可欠で、多くのサンプルを集める必要があるという欠点があります。
それに対して、近年注目されている、World modelという過去の環境とのインタラクションデータから環境自体を学習し、仮にその環境において、ある状況下である行動を起こしたときに、どのような結果をもたらすかという想像を行うことが出来る手法が注目されています。これを用いることにより、例えばplanningを行うことができたり、また少ない環境とのインタラクションデータを用いることで、ロボットの行動を学習、つまりpolicyを学習することが可能になります。この手法は、今まで特にゲームなどで有効性を確認されてきましたが、実世界での有用性については今まで示されていませんでした。
本論文では、これを確認するために、Dreamerと呼ばれるWorld modelを学習する手法を用いて以下の4つのロボットに対して適用し、実世界で効果的にonline learningにより学習出来ることを示しました。この記事では、Dreamerの手法の説明とともに、それぞれのロボット実験においてどのような結果を示したかを紹介していきます。

手法
本論文ではDreamerとよばれる、online learningによるworld modelの学習、そしてそれと同時に行動を学習する手法を実世界のロボットに対して適用しました。この章ではDreamerの紹介をしていきます。以下の図はDreamerの手法の全体像を表しています。
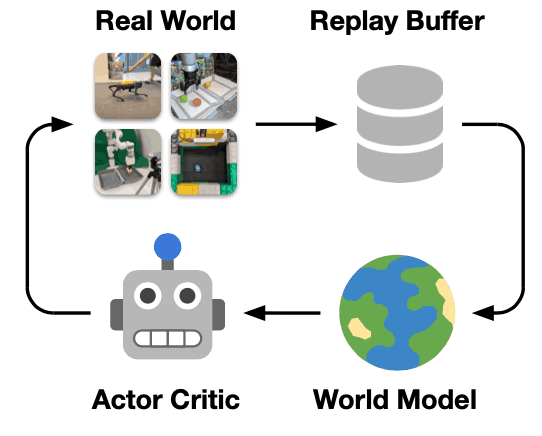
Dreamerは、過去の環境とのインタラクションの経験データからworld modelを学習し、そしてactor critic algorithmを用いて、学習されたworld modelから予測されたtrajectoryを元に行動を学習します。よって行動自体は実世界の環境とのインタラクションではなく、学習されたworld modelによって想像されたデータを用いて学習されます。また、本研究では、data collectionとモデルの更新、つまりworld model、actor、そしてcriticの更新を分離し、一つのスレッドではactorがデータを集め続け、それと同時に別のスレッドでモデルの更新を行うことで、より効率的な学習を行いました。
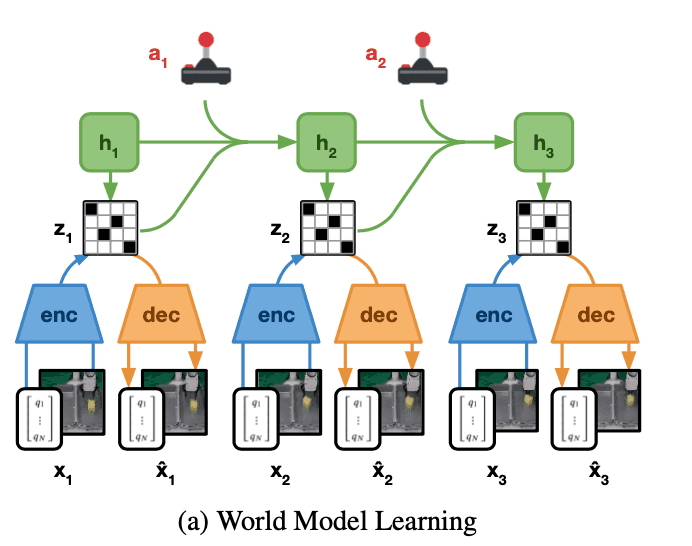
World Model Learning
まずはじめに、どのようにworld modelを学習するかについて説明します。以下の図はworld modelの全体像に関して表しています。World modelは下図が示しているように環境のダイナミクスを推定をすることを目的としています。ただし、画像などのデータを用いて、未来の画像を直接推定する場合、推定された未来の画像と実際の画像との誤差が大きくなりやすく、それにより長期的な未来のダイナミクスを推定する際に誤差が蓄積されてしまうので、その代わりに未来のrepresentation $z_{t+1}$を推定します。World modelはRecurrent State-Space Modelという以下の4つのネットワークで構成されたモデルがベースとなっています。
Encoder Network: $enc_{\theta} (s_{t} | s_{t-1}, a_{t-1}, x_{t})$
Decoder Network: $dec_{\theta} (s_{t}) \approx x_{t}$
Dynamics Network: $dyn_{\theta} (s_{t} | s_{t-1}, a_{t-1})$
Reward Network: $rew_{\theta}(s_{t+1}) \approx r_{t}$
ロボットには基本的に複数のセンサーが搭載されており、例えばロボットのjointの角度やforce sensor、またRGBやdepth camera imageなどを情報として取得することができます。よって、Dreamerのworld modelのencoderはそれらのセンサー情報を合わせて、stochastic representation $z_{t}$ を出力します。そして、dynamics modelは次のstochastic representation $z_{t+1}$をrecurrent state $h_{t}$を用いて出力します。Decoderは入力のセンサー情報を出力し直しますが、この出力結果は行動の学習には直接利用されません。本研究ではロボットが実世界の環境で行動することで、報酬を獲得することができます。Reward networkは、この集められた報酬を予測するように学習されます。
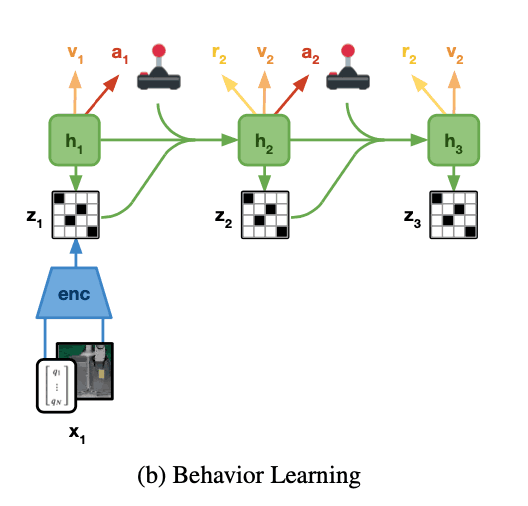
Actor-Critic Learning
World modelがタスクに依存しない環境のダイナミクスに関する表現を学習すると同時に、actor critic algorithmを用いて、あるタスクに特化した行動を学習します。学習は下図が示しているように、world modelの潜在空間で推定されたrolloutを利用して行動を学習します。このActor critic algorithmは以下の2つのニューラルネットワークから成り立っています。
Actor Network: $\pi (a_{t}| s_{t})$
Critic Network: $v(s_{t})$
ここで、actor networkはそれぞれの潜在空間の状態 $s_{t}$に対して、推定されたタスクの報酬を最大化するような行動 $a_{t}$の分布を学習します。一方、critic networkはタスクの未来に得られる報酬の合計 (value)を推定するよう、temporal difference learningを用いて学習されます。このcritic networkによるvalue functionの学習は、planning horizon (H=16)より先の報酬も考慮してくれるので重要になります。Criticは、推定されたstateの報酬を元に学習され、学習のためのターゲットとなる軌跡のリターンを下記のように求めます ($\lambda$-returns)。
$V_{t}^{\lambda} \doteq r_{t} + \gamma((1-\lambda) v(s_{t+1}) + \lambda V_{t+1}^{\lambda}, \quad V_{H}^{lambda} \doteq v(s_{H}))$
Actorはvalueを最大化することを目的とし学習されますが、それとともに学習時に環境を探索することを促すために、entropyが高い状態を維持することを促します。これを考慮して、actorは下のloss関数を用いて学習されます。
$\mathcal{L}(\pi) \doteq-\mathrm{E}[\sum_{t=1}^{H} \ln \pi(a_{t} | s_{t}) sg(V_{t}^{\lambda}-v(s_{t})) + \eta \mathrm{H}[\pi(a_{t} | s_{t})]]$
ここで、$sg$は勾配の計算を止めることを示しています。つまりcritic自体は更新されません。
実験
本論文では、Dreamerを4つのロボットに対して学習させ評価しました。これらのロボットのタスクは、locomotion, manipulation, navigationなど重要なタスクであることに加え、行動空間が連続、もしくは非連続、報酬がdenseであるかsparseか、そしてproprioceptiveな情報 (ロボット自身の情報、例えばjointの状態など)か画像、その他のsensorを合わせた入力など、様々なパターンについて評価しました。
この実験の目的は、world modelを用いた手法により、現実世界においてロボットの行動をより効率的に得られる事が出来るかどうかを確かめることです。具体的には以下のようなことについて実験を通して確かめています。
- Dreamerは現実のロボットにおいて直接適用することができるかどうか
- Dreamerは様々なロボット、センサーのモーダリティ、そして行動空間の種類において行動を獲得することが可能かどうか
- 他の強化学習の手法と比べて、Dreamerを用いた手法はどの程度効率的か
Baseline
A1 quadraped robotを用いた実験では、行動空間が連続値を取り、かつ低次元の情報を入力として与えるため、Soft Actor-Critic (SAC)をベースラインとしてDreamerと比較しました。XArmとUR5 robotを用いた実験では、画像とpriorioceptive informationを入力とし、行動空間は離散値を取るので、DQNをベースラインとして学習しました。特にRainbowとよばれる手法を用いて学習をしました。また、UR5に関してはPPOとも比較をしました。最後に、Sphero navigationタスクにおいては、画像が入力として与えられ、行動空間は連続値になり、DrQv2という手法をベースラインとして比較しました。
A1 Quadruped Walking
本実験では、下図のようなUnitree A1 Robotとよばれるロボットを用いて、仰向けの状態から、回転して立ち上がり、一定のスピードで前に進むようなタスクについて取り組みました。過去の論文では、domain randomizationを利用しシミュレーション内で方策を学習した後に実世界のロボットに対して転移することや、recovery controllerと呼ばれるロボットが危険な状態を避ける仕組みを用いた学習、そして行動の軌跡の生成器のパラメーターを学習するといった方法が主に使われていましたが、本研究ではこれらのいずれも使わずに学習を行いました。学習にはdense reward functionを用いられています。どのような報酬関数が定義されているか気になる方は、ぜひ論文の式 (5)を参照してください。
1時間の学習の結果、以下の図のように、ロボットが地面に背を向けた状態から、回転し、立ち上がり、そして前に歩くという一連の動作をDreamerを用いて学習することができました。はじめの5分で、ロボットが回転し足を地面につけることが可能になり、20分後に立ち上がることを学習し、最終的に歩くことが可能になりました。さらに追加で10分間学習することにより、外から押されることにより力が加わってもそれに耐えることが出来ることや、転んでもすぐに立ち直ることが出いるようになりました。それに対して、SACは、後ろ向きの状態から回転して足を地面につけることはできましたが、立ち上がり歩くことはできませんでした。

UR5 Multi-Object Visual Pick and Place
下図のような物体を掴んで、別のビンに置くというタスクは倉庫などでよく見られるタスクとして重要です。このタスクはsparse reward functionを用いて学習することを目的としているので、とても難しく、画像から物体の場所を推定、そして複数の動く物体のダイナミクスを推定できるようにならなければなりません。センサーから得られる情報としては、ロボットの関節の角度、グリッパーの位置、そしてend-effectorのデカルト座標、そしてRGB画像となります。報酬としては、グリッパーが途中まで閉まることが検知された際に、+1の報酬を、物体を同じにビンに離してしまえば、-1の報酬、そして反対のビンに置いた際は+10の報酬を会えました。行動空間はend-effectorをX, Y, Z-axisに対して一定の距離を動かす行動とgripperを閉めるもしくは開くという行動から成り立ち、離散値を取ります。
Dreamerは、平均2.5個の物体を1分間で掴むことが出来るようになるのに8時間の学習を必要としました。特に最初の段階では報酬がsparseであることから、あまり学習が進みませんでしたが、2時間たったあたりから、パフォーマンスが向上し始めました。それに対して、ベースラインであるPPOとReinbowは学習することに失敗し、物体を掴むことはできましたが、すぐに離してしまうという行動が見受けられました。これらの手法は、より多くの経験が必要であると考えられ、実世界での学習は困難であると考えられます。

XArm Visual Pick and Place
UR5は工業用のロボットであるのに対して、XArmは比較的安価な7DoFのロボットです。UR5の実験と同様に、物体を画像からどこの場所にあるかを推定し、それを別のビンに移すというタスクに関して学習をさせます。この実験では柔らかい物体を使い、物体がビンの端にある場合でもつかめるように、グリッパーと物体が紐でつながっており、物体を動かすことが出来るようになっています。報酬関数はUR5の実験と同様のsparse rewardを用いて学習し、行動記うう感も同様の物となっております。入力情報としては、UR5の実験で利用した情報に加えてdepth画像も利用しました。
Dreamerはpolicyを10時間で1分で平均3.1個の物体を掴んで別のビンに移動することが可能になりました。またDreamerを用いた場合、光の条件を変えた場合でも、はじめはタスクを解くことに失敗しますが、数時間の学習によりすぐに適応することができました。それに対してRainbowを利用した場合、UR5での実験と同様に多くの経験が必要になることから学習に失敗しました。

Sphero Navigation
最後に、車輪付きロボットであるSphero Ollie Robotを決められたゴールへと操作するナビゲーションタスクにおいて実験を行いました。これはRGB画像のみを入力として利用して学習しました。行動空間は、連続値であり車輪が動く方向を行動として推定します。報酬として、現在地からゴールまでのnegative L2 distanceが与えられます。
Dreamerは2時間でゴールへと移動することができ、そのままゴールの近くにとどまることが出来るようになりました。ベースラインであるDrQv2はDreamerと同様のパフォーマンスを示しました。

まとめ
本研究では、実際のロボットで今まで確かめられていなかったDreamerがどの程度効率的に方策を学習出来るかを試し、model-free RLのベースラインと比較してより効率的に学習出来ることを示しました。実際にDreamerのようなworld modelを学習するような手法が、実世界のロボットに対して適応することがわかったので、今後この分野の研究がさらに行われていくのではないかと考えています。例えば、Dreamerが効率的に学習できるとはいえ、未だ8-10時間程度学習に必要なことから、それをより短くするような学習方法、特により効率的にstructured latent representationを学習出来るようにすることなど様々な方向性が考えられます。






この記事に関するカテゴリー






