BERTに続け、バイドゥが発表した中国語における問題に対処したERNIEとは?
【元記事】:Baidu released knowledge integration language representation model ERNIE which outperforms Google’s BERT in certain Chinese NLP tasks
【論文】:ERNIE: Enhanced Representation through Knowledge Integration
Baidu(バイドゥ)が、中国語に特化した汎用的な分散表現獲得のための機構「ERNIE」を今年3月に発表しました。Googleが昨年発表したBERTの流れを汲んだ研究で、BERTが中国語を扱う上での問題点を解決したモデルとなっています。
AI-SCHOLARでは以前、BERTについて以下の記事を掲載しました。今回はこのBERTが抱える中国語における弱点を克服したモデル、ERNIEについてご紹介します。ERNIEはBaiduから発表されており、Githubにおいてコードも公開されています。
ERNIEは複数の中国語タスクで評価され、BERTを上回ることが報告されています。ERNIEが着眼した中国語の問題は、日本語を取り扱う上での問題とも重なるため、ERNIEの理解は日本語を取り扱う我々にとっても重要です。日本語に応用することで、BERT以上にタスクを解く精度が向上するかもしれません。
分散表現獲得の重要性
BERTはあらゆる自然言語処理タスクに応用することができる、汎用的な分散表現の獲得を行う機構です。分散表現とは単語や文をベクトルとして表現したもので、似た表現に似たベクトルを与えることがタスクの精度向上に寄与すると考えられています。直感的には、国語の勉強をする前にたくさん本を読んでおくことで点数の向上が見込まれるといった感覚です。詳しくは以下の記事にて解説しているため、ご参照ください。Googleが公開した自然言語処理の最新技術、BERTとは何者なのか
自然言語処理における重大な問題として、タスクを学習するためのデータセットが限られているというものがあります。一方で、タスク学習を目的としていない、すなわち何も手を加えられていない「生」の自然言語データはインターネット上で大量に収集することができます。こうした状況は自然言語処理の特徴ともいえます。BERTなどの分散表現獲得機構を用いて大量の自然言語データを事前に学習することで、少量のデータセットでもタスクに最適なモデルを作成することができると考えられています。そして、この分散表現獲得機構をより優れたものにすることで、タスクを解く精度も向上すると期待されています。ERNIEは中国語においてBERTを上回るような優れた分散表現獲得機構として発表されています。
BERTの中国語における問題点
ERNIEはBERTの中国語における問題点を克服する形で提案されているモデルです。最先端の自然言語処理では英語などのアルファベットを用いて表記する言語を主に取り扱っているため、中国語や日本語といったアジアの言語特有の問題に対処できていない傾向があります。Baiduは「BERTにおける入力単位が中国語の単語と一致していない」という問題に注目しました。
こちらの記事でご紹介した通り、BERTでは穴埋めクイズを用いて分散表現の獲得を行います。穴埋めクイズではランダムに単語をMASKというトークンに置き換え、本来の単語を前後の文脈から予想します。この単語という単位は、英語では以下のようにスペース区切りの単語となっていました。
I [MASK] you .
ここでは例として、likeという単語がMASKトークンに置き換えられている(=隠されている)とします。BERTでは前後のIとyouから、マスクされたloveを予想します。これだけの情報でlikeを予想することは難しいですが、少なくとも動詞として使われる単語の確率が高くなるような予想となります。この穴埋め問題を学習することで、BERTは「likeは他の動詞と同じような文法において用いられる」ことを学習します。すなわち、likeはほかの動詞と同じような文法規則において出現するという情報が学習されます。
一方で中国語においては、単語がスペースによって明示されていないため、文字ごとに[MASK]に置き換えるといった穴埋めクイズが生成されます。例えばI like you .の例であれば、以下のような穴埋めクイズを解くことになります。
我 [MASK] 欢 你
ここでBERTはマスクされた「喜」を当てる穴埋めクイズを解くことになります。しかし、この状況では「欢」が見えてしまっているため、「喜欢(like)」という単語の一部として「喜」を当てることが可能となってしまいます。これでは英語の時のような文法規則の学習が期待できません。
ERNIEでの解決方法
単語レベルを意識した学習
この問題を解決するために、ERNIEでは実際に用いられる単語レベルの区間を考慮したマスキングによる穴埋め問題を解くようにBERTを改良しています。従来のBERTでは文字ごとにマスキングを行っていたのに対し、ERNIEでは単語として連続する文字列はすべてマスクするように変更されています。具体的には、以下のような入力の差が生まれます。
BERT : 我 [MASK] 欢 你
ERNIE : 我 [MASK] [MASK] 你
このようにすることで、英語でlikeの穴埋め問題を解いていたのと同じような学習効果が期待されます。さらにBERTとは異なり、文字を単語というまとまりで学習することになるため、「赤色」「青色」といった接尾辞や接頭辞を共有する単語に対しても、効率的な学習を行えるようになります。
対話データを用いた学習
ERNIEでは、BERTを用いた事前学習では取り扱えないような種類のデータについても取り込めるようにモデルの改良を行っています。具体的には対話を記録したテキストデータを用いて事前学習をできるように、Dialogue Language Model(DLM)という手法を採用しています。これは二者間で交互にやり取りされる対話テキストにおいて、対話における話者の役割を学習することができるモデルです。対話における自然言語では、より単語や文の意味理解が重要となるため、これを学習することで分散表現をより豊かにしようという目的から、DLMは導入されています。BERTはWikipediaやニュースなどの単一話者によるデータしか学習対象にできなかったため、学習可能データを拡大したERNIEはさらに多くの情報を分散表現に詰め込むことができると期待できます。
評価
機械による穴埋め形式の読解タスクにおいて、ERNIEはBERTでは導き出せないような解答を生成できると報告されています。BERTが文脈に出現した人名や、問題に関係のない人名を穴埋めの予測候補に出している一方で、ERNIEが正しい答えを予測していることを示されています。穴埋め部分に入る単語についてよく理解していないと解けないという問題設定にしているため、このことからERNIEがBERTよりも中国語をよく理解していると考えることができます。
また中国語を用いた主要なタスクにおいても、ERNIEはBERTの性能を上回っていると報告されています。表においてXNLIは言語推論タスク、LCQMCは二つの質問が同じことを言っているのかを分類するタスク、MSRA-NERは固有表現抽出、ChnSentiCorpは感情分析、NLPCC-DBQAは質問に答えるための文を選択するタスクです。
(表はgithubより引用。一部中国語から日本語に翻訳。)
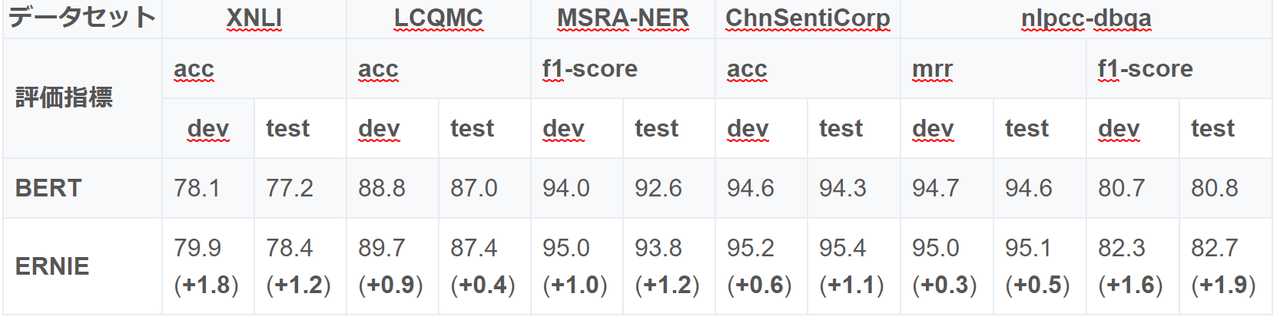
なお、ERNIEによって導入された穴埋めクイズの改良とDLMの一方ずつを適用した評価は行われていないため、実際にどちらが大きくモデルの精度向上に寄与したのかは、発表の中では不明となっていることに注意してください。
まとめ
ERNIEは中国語特有の問題に絞ってBERTを改良した研究です。中国語と日本語は単語分割が明確ではない点や、文字そのものが意味を持つ表意文字を含むという点で非常に似ています。ERNIEを日本語に応用することで、BERT以上にタスクを解く精度が向上するかもしれません。ERNIEに続き、日本語特有の言語問題を解決するようなモデルについても、考えてみると面白いかもしれません。



この記事に関するカテゴリー



