敵対的サンプルを翻訳タスクの学習データに応用。水増しデータによるセキュリティ向上の試み
Robust Neural Machine Translation with Doubly Adversarial Inputs
written by Yong Cheng, Lu Jiang, Wolfgang Macherey
(Submitted on 6 Jun 2019)
Accepted by ACL 2019
Subjects: Computation and Language (cs.CL)
近年、深層学習の台頭により、機械翻訳技術が実際に活用できるレベルになってきました。この技術により言語の壁が取り払われようとしています。しかし現状、その活用は一部に限られています。その一つの要因として、文章の意味は同じもしくはほぼ同じにも関わらず、その構成要素となる単語が異なった二つの文章を翻訳した際に、全体として異なる意味の翻訳結果となってしまうという問題があります。例えば以下の例を見てください。
 図1. 「他」を「她」にして翻訳した例
図1. 「他」を「她」にして翻訳した例
この例では、中国語を英語に翻訳するタスクで、入力文章中の「他」(彼という意味)を「她」(彼女という意味)に置き換えて翻訳を行っています。「he」の部分が「she」になり、そのほかの単語は変化しないことが正しい翻訳ですが、結果は「he」が「one of her」となり、さらに「person」が「people」に変化してしまいました。
このように現状の機械翻訳技術では、単語レベルの差によって異なる意味の文章に翻訳してされてしまう危険性があります。日常会話に機械翻訳技術を使う場合には、それほど大きな問題にはならないかもしれません。しかし、各国の首脳会談など重要な場面で使うということを想定した場合、異なる意味に翻訳されては使い物になりません。
また、この機械翻訳の脆弱性は悪意のある攻撃者に利用されるかもしれません。例えば、あるサイトの文章を翻訳しようとした際に、攻撃者が機械翻訳技術が誤翻訳するように単語の入れ替えをしたとします。すると、サイトの作成者からみると、意味は変わらないため気づかず、翻訳された文章を見た閲覧者がその文章を異なる意味で理解してしまう、ということが起きるかもしれません。
上記に述べた理由から、単語の入れ替えを行った場合でも同じ意味に翻訳する技術が求められています。
Googleはこの問題を解決するために、機械翻訳モデルを学習する際に、訓練データの単語を入れ替えつつ同じ意味の文章を生成し、それを訓練データに含めることでより誤翻訳が少ない精度の高いモデルを構築しています。
この研究は画像認識分野で注目を集めているadversarial example(敵対的サンプル)と呼ばれる、分類器を騙す技術を翻訳タスクに応用したものです。これまでは機械を騙す技術だったものがデータ拡張にも使えることがこの研究によって示されました。
モデルの構築
以下では、簡単にこの翻訳モデルの構築の仕方を見ていきます。
翻訳モデルのベースラインとして、Trasformerと呼ばれるencorder-decorderモデルを使用します。encorder-decorderモデルとは入力文章をencorderで数値化して情報を集約し、その集約した情報をdecorderに入力して翻訳を行うモデルです。
従来、RNNやCNNを用いたものが翻訳モデルとして使用されてきましたが、Transformerはそれらを使わず、注意機構と呼ばれる仕組みを使ってモデルを構築しています。シンプルで計算量が少ないのにも関わらず、高精度の翻訳を実現したモデルで、近年の翻訳モデルではデファクトスタンダード(事実上の標準モデル)となりつつあるモデルです。
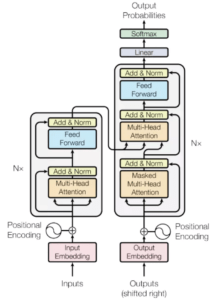
図4. Transformerの概要
この研究は訓練データを元にして、誤翻訳を起こす可能性のある文章を作り、その文章も訓練データに含めることで精度の向上を図っています。では誤翻訳を起こす可能性のある文章をどのように生成するのでしょうか?
翻訳タスクでは、ある言語の文xを入力した際に、異なる言語でかつ同じ意味の文yを出力するモデルを構築することがゴールです。このxに対してAdvGenと呼ばれる仕組みを使ってx´を生成します。AdvGenは、入力 x とそれに対応する出力 y がどれだけ離れているかを元に、その損失が大きくなるように文x内の単語の入れ替えを行います。このとき同じ意味の単語で入れ替えを行います。すなわち、AdvGenは誤翻訳を起こしやすく、かつ文章の意味を変えないような単語による文章を生成します。
そして、AdvGenを使って生成したデータ(x´,y)を訓練データに含めて学習します。さらにこの研究では入力xだけではなく、x´を入力した際のdecorderへの入力 : zに対してもAdvGenを利用して単語の入れ替えを行ってz´を生成しています。つまり(x´,z´,y)を使って訓練データを水増しする事で、誤翻訳が少ないモデルを構築することに成功しています。
実験結果
中国語-英語および英語-ドイツ語間のデータを使って実験を行っています。一つ目の実験は訓練データのみ用いて学習したモデルと水増しした訓練データを用いて学習したモデルの精度を比較する実験です。二つ目の実験はテストデータの入力文章の単語を置き変えて、このモデルがどれほどノイズ耐性を持っているか示すための実験です。結果は以下の通りです。
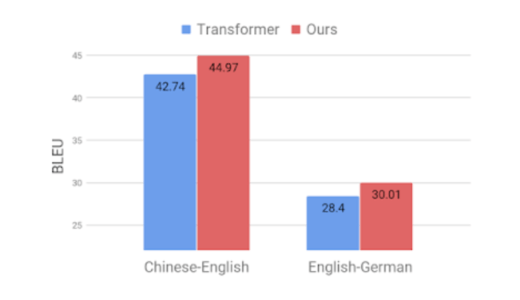
図2. 中国語-英語および英語-ドイツ語間翻訳タスクの結果
図2では、単語を入れ替えて生成したデータを訓練データに含めることで精度が大幅に向上したことが分かります。
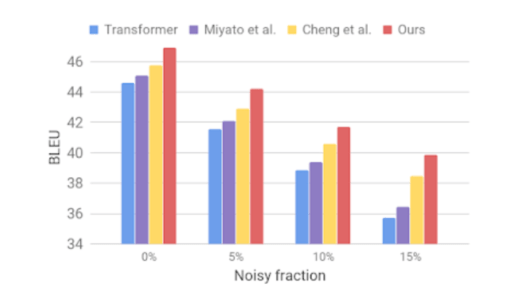
図3. 入力文章にノイズを加えた場合の精度
図3では、ノイズ対策を行っていないモデルの場合(青色)は、ノイズの割合が増えると急激に精度が落ちていることが分かります。一方、本研究でのモデルでは、従来手法でノイズ対策をしたモデル(紫色、黄色)よりもノイズに強いモデルが構築出来ていることが分かります。さらにこちらをご覧ください。

図4. 単語の入れ替えを行った場合の翻訳結果の差
上から三つ目と四つ目の文章がノイズ対策をしていないモデルで、下二つがノイズ対策を行ったモデルの翻訳結果を示しています。これを見ると、ノイズ対策したモデルは、入力文の変化させた部分に該当する単語のみが翻訳文中で変化していることが分かります。
まとめ
本記事では、訓練データに対して損失を大きくするように単語を入れ替え、その入れ替えた文章を訓練データに含めることで、従来モデルより精度が高く、かつ誤翻訳を起こしにくいモデルを構築する研究を紹介しました。
私は機械学習をビジネス活用を模索するチームで働いていますが、どのお客様も精度だけを考慮し、モデルのセキュリティまで気が向いてないように思います。今回の論文のように、使用するデータセットの量や性質をうまく改変するだけで、セキュリティは向上することがわかりました。機械学習の技術発展は、その悪用による危険性も同時に孕んでいると言えます。加えて、情報社会の現代だからこそ、精度を上げるだけではなく、AIのセキュリティまで考慮することが真にAIを活用するために必要だと思います。



この記事に関するカテゴリー



