
計算時間とメモリの壁を打破!Transformerの次世代モデルReformer
3つの要点
✔️ Local-Sensitive-Hashingにより必要な要素同士のAttentionを計算することができるようになった
✔️ Reversible layerによってレイヤー数に比例して増加するactivationを保存するメモリの削減
✔️ transformerの計算量を$O(L^2)$から$O(L \log L)$まで削減した
Reformer: The Efficient Transformer
written by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya
(Submitted on 13 Jan 2020 (v1), last revised 18 Feb 2020 (this version, v2))
Comments: ICLR 2020
Subjects: Machine Learning (cs.LG); Computation and Language (cs.CL); Machine Learning (stat.ML)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
Transformerの発表以降,Attention Layerを応用してTransformerのEncoder部分を最大で24層積み重ねたBERTや,Decoder部分を最大48層積み重ねたGPT-2など多くの巨大で各種タスクにおいて高性能を発揮するモデルが発表されてきました.しかし,巨大であるため,計算コストもどんどん増え,層を単純に増やして性能の向上をするのとは違う方向でモデルをより効率化する研究も盛んに行われるようになりました.そのような時代背景の中で,transformerを効率化しようとした試みの一つがReformerです.
ReformerはTransformerのself-attentionの計算量が,$O(n^2)$であり,長い文章を入れると,メモリの使用量が急増する問題に対して,attentionの向ける向きを工夫することで対応しようとしたものです.
Transformerの問題点とは
Transformerは計算量が入力シーケンスに伴って2次的に増加していきます.これにより,メモリの使用量も計算時間も非常に長くなります.
計算量増加の主要因はTransformerの主要パーツである,Scaled Dot-Product Self-Attentionです.そもそも,Scaled Dot-Product Self-Attentionとは,クエリとキー・バリューのペアを使ってAttentionを計算するものです.つまり,Scaled Dot-Product Self-Attentionの計算式は,クエリ,キー,バリュー($Q,K,V$)を用いて,
$$Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}}V)$$
で示されます.($d_k$はクエリときーの深さを表します)この時に,クエリとバリュー(Q,V)の積は文書の長さ($n$)の二乗になります.そのため,2046トークンが入力として与えられた時にAttentionの計算に用いる行列サイズは,2024*2024となり,約410万要素を持つ行列をAttentionの計算で処理しなければならなくなります.
そこで,このTransformerの問題である入力シーケンスの二乗に伴って計算量が増加する問題に取り組んだのが本論文であるReformerです.
Reformerでは,Local-Sensitive-HashingとReversible Residual layerという2つのアーキテクチャーを採用し,少ないメモリで長い入力を処理することを可能にしました.
Reformerを用いた結果
Reformerの性能の比較の実験は,imagenet64とenwik8-64kという二つのデータセットを用いて行っています.enwik8-64kはenwik8を64Kトークンに分割したものです.また,実験の設定は,レイヤー数が3,単語の埋め込みや隠れそうの次元($d_{model}$)が1024,中間層の次元数($d_{ff}$)が4096,head数とバッチサイズともに8です.
下記の論文中のFigure5の右側は計算時間に関するグラフで,本論文で提案しているReformerのLSH attentionを用いることで,文章が長く,バッチ数が少ない場合においても,従来のtransformerのように計算時間が長くならないことが主張されています.
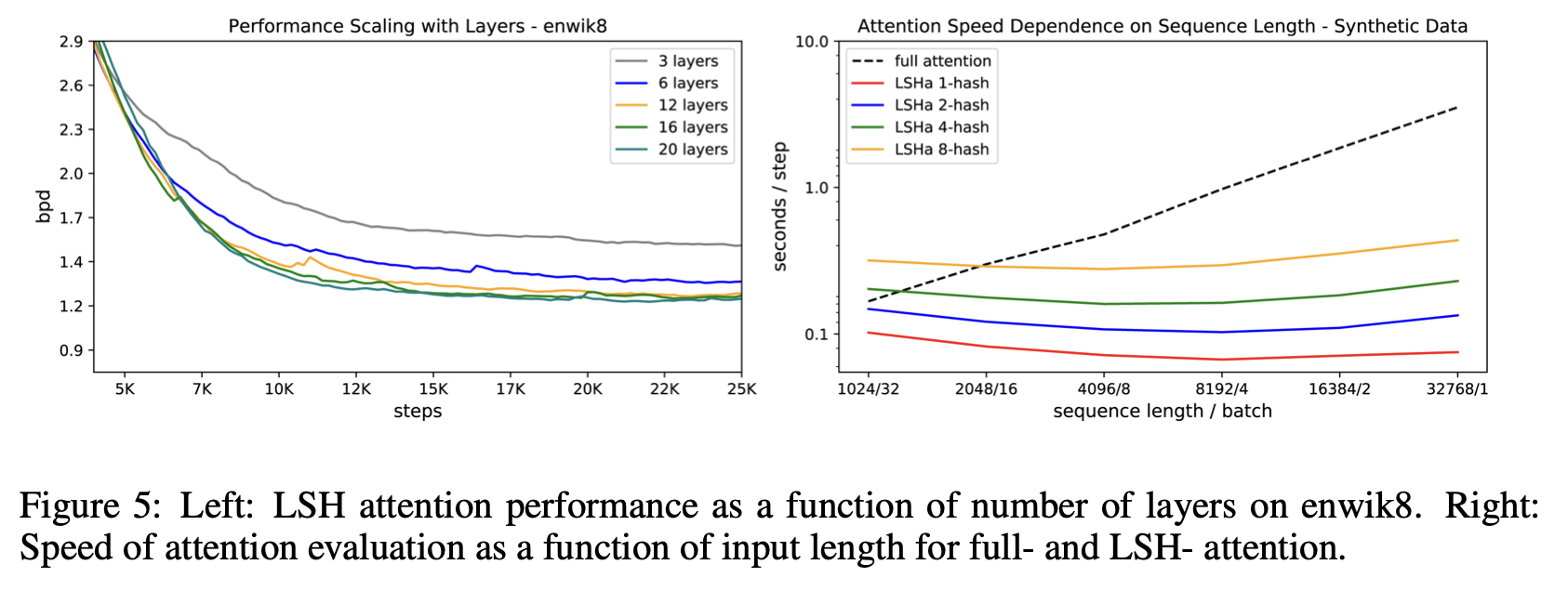
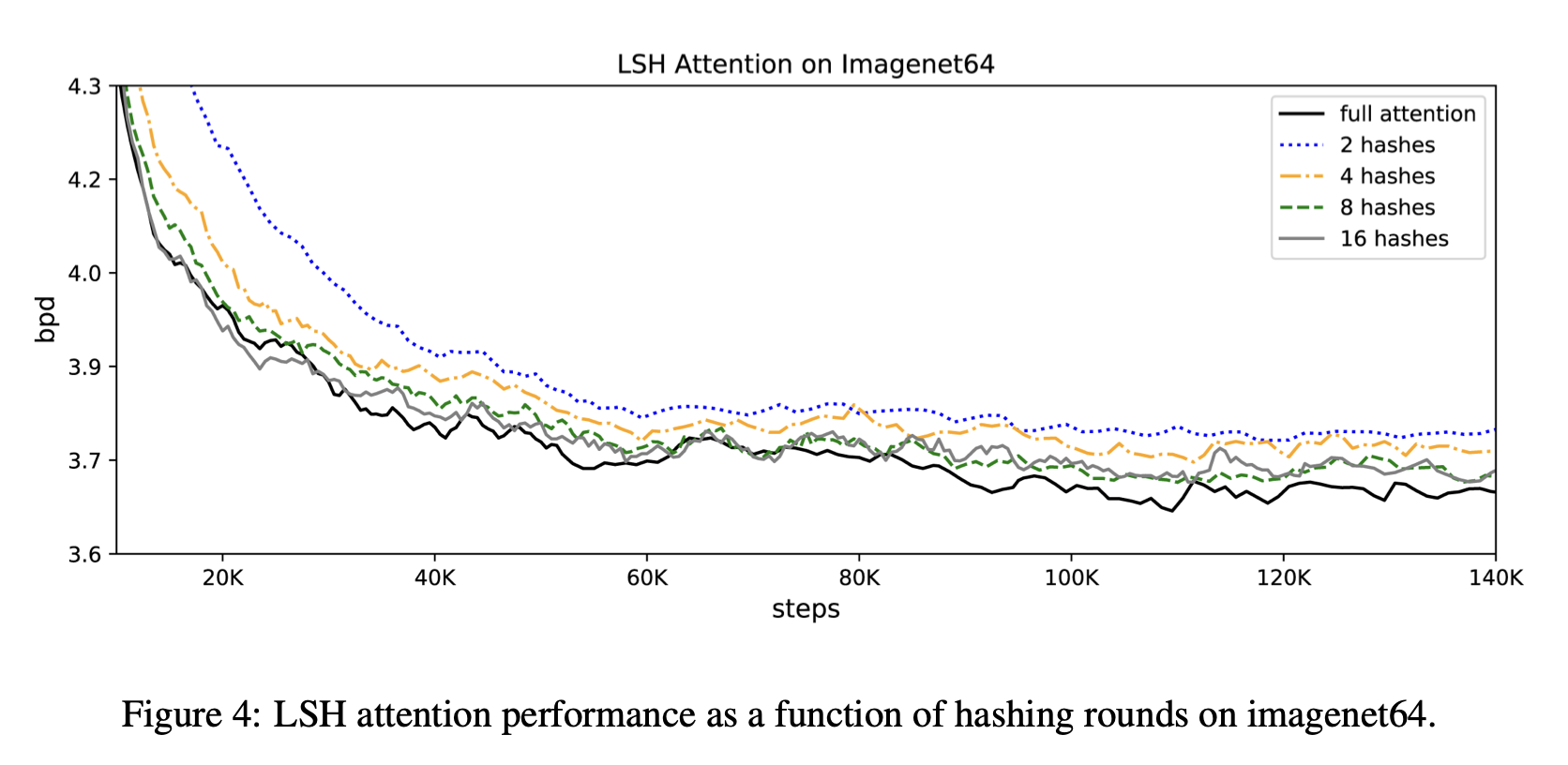
また,計算時間が削減できているにもかかわらず,精度も通常のtransformerとほとんど同じです.具体的には,論文中のFigure4を見ると,精度に関して記載があります.ハッシュバケットを8程度にしてもほとんど通常のtransformer(full attention)と性能が変わらないことがわかります.
それでは,以下では,どのような工夫をReformerで行い,計算時間とメモリの使用量を削減できたのか見ていきます.
Reformerの工夫
Reformerでは,以下の二つのアーキテクチャーの採用により,メモリの使用量を大幅に削減しています.
- Local-Sensitive-Hashing (LSH)
- Reversible Residual layers
Local-Sensitive-Hashing (LSH)とは
本研究のアイディアは,従来のAttentionのように内積を全部計算してクエリに近いキーを取ってくるのではなく,内積を全部計算せずともクエリと近いキーを取ってくる方法はないのか?というものです.これが,Local-Sensitive-Hashing (LSH)と呼ばれる手法です.
数式を少し使って具体的に見ると,そもそも,従来のAttentionは下記のように書くことができます.
$$Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}}V)$$
これでは,関連性が低いような要素に対してもAttentionを向けていることになります.本当は関連性のあるような部分だけを取り出せばそれで十分であるはずなのに全体を計算しているのは非効率というのが本研究の主張です.そこで,全ての要素に対してAttentionを計算せずにクエリに似ている要素(キー)を取得できないかというのが,そもそものアイディアです.そのため,全てのキーがなくてもよく,各キー$q_i$に近い$K$のサブセットのみで$QK^T$の目的を達成することができます.数式で表すと以下のようになります.
$$softmax(\frac{q_i K^T}{\sqrt{d_k}}V)$$
また,これを実現する仕組みとして,LSH Attentionを提案しています.
・LSH Attention
Reformerではクエリに近いキーを抽出するために類似した要素には同じハッシュ値を与えるというLSHを用いて入力を分類しています.LSHには様々なアルゴリズムがありますが,Reformerで採用されているアルゴリズムはRandom projectionです.
Random projectionは区画分けされた2次元平面に散らばった点をランダムな角度で回転させると,近い同士の点(類似している)であれば近くに移動する確率が高く,遠い同士の点(類似していない)場合には,違く区画に分かれることになります.これを応用すると,クエリに近いキーだけを抽出することができます.
具体的には,Figure1の上の図では,二つの点は離れているため3回回転させたうち,1回しか同じ区画には入っていません.反対に,下側の図では,2点の距離は近いために,ランダムな回転3回すべてで同じ区画に入っています.この区画のことをハッシュ・バケットといい,ベクトルをくるくるランダムに回転させ,同じハッシュバケットに入っていれば同じハッシュであるとみなすことにしています.このクエリ$q_i$と同じバケットに入っているキーにだけAttentionを向けるようにするというのがLHS attentionです.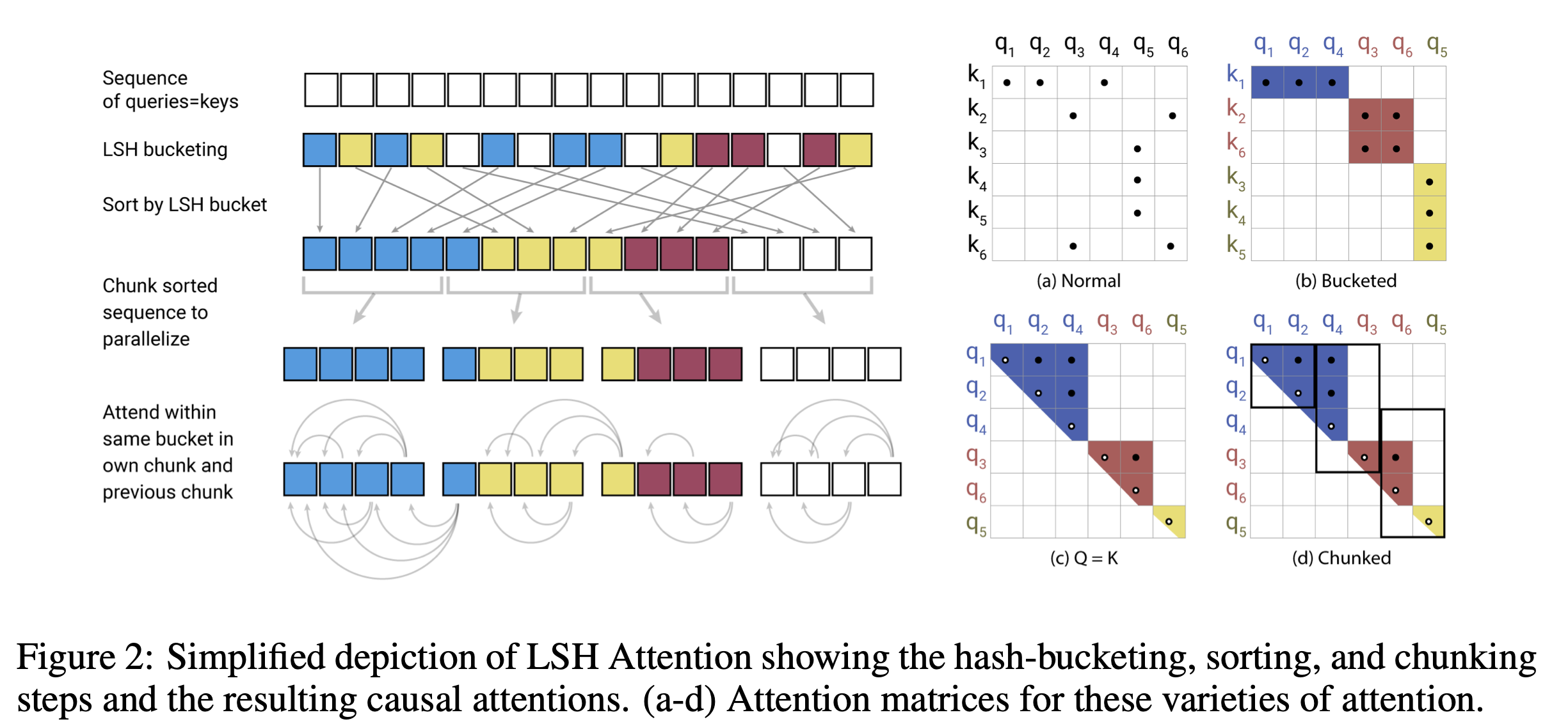
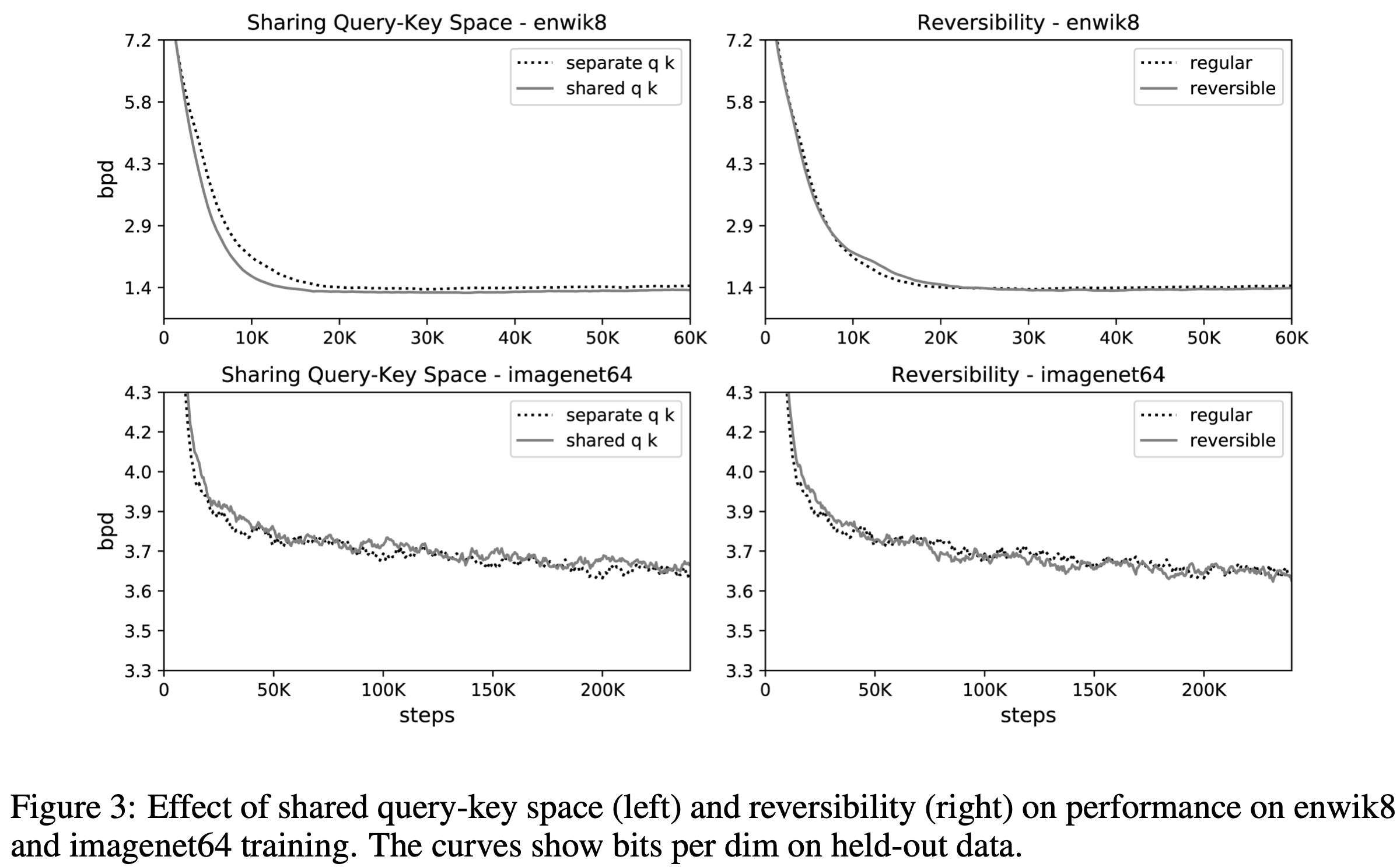
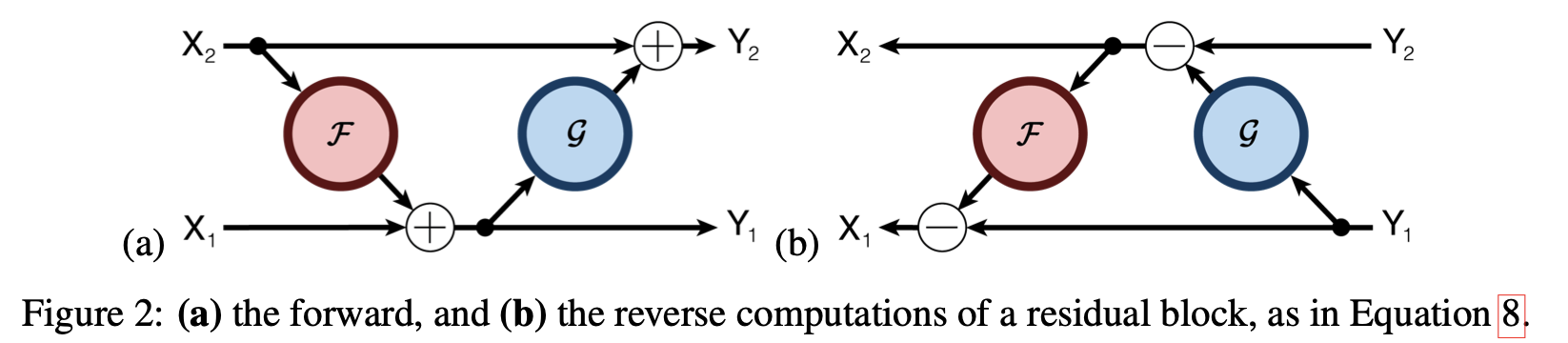
より具体的にFigure2の左側の図に従ってReformerの挙動を見てみると長いシーケンスの入力をクエリーとキーを等価とします.これは,特定のハッシュの中にqueryだけたくさん存在し,Keyが全く存在しないということを防ぐ目的で実行します.このqueryとkeyを同じにしても問題のないことは実験によって証明されていて,Figure3を用いて説明されています.(後述)
入力を受けとった後,LSHによりbucket分けをします.そのLSH Bucketごとにソートを実行します.次に同じ長さのチャンクになるようにデータを分割します.このチャンク毎・直前のチャンクに対してAttentionの計算を行うという処理を行って注目すべきキーを取り出しています.
Figure3の左側では,imagenet64データセットとEnwiki8どちらの場合でも,queryとkeyを同じにすることによるデメリットはないことがわかります.
Reversible Residual layersとは
Reformerでのもう一つ重要なアイディアが,Revirsible Residual layersです.Revirsible Residual layersでは,途中の計算状態を保存する必要がなく,Attentionの計算を大幅に削減することができます.具体的には通常,バックプロパゲーションの実行のために,活性化関数の活性化後の値を保持しておく必要がありますが,BERTやGPTシリーズのように巨大なモデルになればなるほど,隠れ層の次元やレイヤー数が大きくなり,保存に要するメモリも大きくなります.そのため,上流のレイヤーの活性化後の活性化関数の値から下流の活性化関数の値を計算する子でとで,メモリの使用量の削減を試みたものです.
具体的には,上述のようなResidual Connection(残差結合)は$y = x + F(x)$で示されます.これは,ResNetで初めて採用されたアーキテクチャーで,深層学習において,層を増やすことで,入力情報がうまく出力に反映されない(情報の消失)問題を回避するために採用されたものです.ResNetでの採用当時は,特定の層でデータをそのまま出力層に加えることでより効率的な学習を重ねることに成功していました.
さらに,このResNetのアーキテクチャーを改良したのが,Reversible residual networkです.このネットワークはで,入力を二系統に分けることによって,下流の結果から上流の結果へと可逆的に計算できることが挙げられます.
・RevNetの計算1
まず,入力と出力を2系統$(X_1, X_2)$に分解して2つの層(F, G)へ入力します.この結果計算される結果は,以下のようになります.
$$Y_1 = X_1 + F(X_2)$$
$$Y_2 = X_2 + G(X_1)$$
・RevNetの計算2
RevNetにおける最終的な出力は$Y_1$と$Y_2$を連結したものを出力とします.
・RevNetにおけるバックプロパゲーション
RevNetにおけるバックプロパゲーションは可逆的に計算できることから,以下のように示されます.
$$X_1 = Y_1 - F(X_2)$$
$$X_2 = Y_2 - G(X_1)$$
ここまでのRevNetは一見モデルを複雑にしたように見えますが,このアーキテクチャーにより,学習の際に,従来のように出力結果の逆伝播のために計算の途中状態を保存しておく必要がなくなります.なぜなら,バックプロパゲーションに必要な直前の活性化関数の値$X_1, X_2$がそれぞれ,計算で求められるためです.
そのため,通常保存しておく必要のある全ての活性後の活性化関数の値を保存せずに済むため,メモリの節約ができるというものです.以下にThe Reversible Residual Network: Backpropagation Without Storing ActivationsにおけるReversible residual networkの概略図を示します.
The Reversible Residual Network: Backpropagation Without Storing Activations
これのReversible residual network(RevNet)の考えをtransformerに応用したのが,Reformerとなります.transformerの基本構造はAttentionとFeedForwardの繰り返しであるため,トランスフォーマーにおけ$F, G$はAttentionとFeedForwardになり,以下のように示されます.
$$Y_1 = X_1 + Attention(X_2)$$
$$Y_2 = X_2 + FeedForward(X_1)$$
また,バックプログラムパゲーション時は
$$X_1 = Y_1 - Attention(X_2)$$
$$X_2 = Y_2 - FeedForward(X_1)$$
で直前のレイヤーの活性化後の活性化関数の値を求めることができています.
この計算を導入したことでの精度への影響はないことが実験によって証明されています.(Figure3の右側)
まとめ
自然言語処理におけるtransformerの計算量の削減に対する試みであるReformer(Reversible Transformer)について解説しました.Reformerでは,既存の技術(LHS,RevNet)を組み合わせてメモリ使用量の削減を行いました.このことにより,計算資源が少ないなかでもより高精度のモデルを訓練できるようになりました.
他にもLongformerなどtransformerの計算量削減を試みたモデルがありますので興味があれば調べて見てください.






この記事に関するカテゴリー





