
I-ViT:ViTを整数型で計算!?I-BERTの技術を進化させたShiftmax、ShiftGELUも登場!
3つの要点
✔️ Vision Transformerの計算をすべて整数型で実現したI-ViTを提案
✔️ Softmax、GELUをビットシフトを用いた計算で実現し、さらなる高速化を実現
✔️ 量子化なしの場合と比べて3.72~4.11倍のスピードアップを達成
I-ViT: Integer-only Quantization for Efficient Vision Transformer Inference
written by Zhikai Li, Qingyi Gu
(Submitted on 4 Jul 2022 (v1), last revised 7 Aug 2023 (this version, v4))
Comments: ICCV 2023
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
Vision Transformer(ViT)は様々なコンピュータビジョンタスクにおいて最高精度を達成しているモデルです。
しかし、ストレージや計算オーバーヘッドがかなり多いため、エッジデバイスにおける発展と効率的な推論が困難になっているという課題があります。
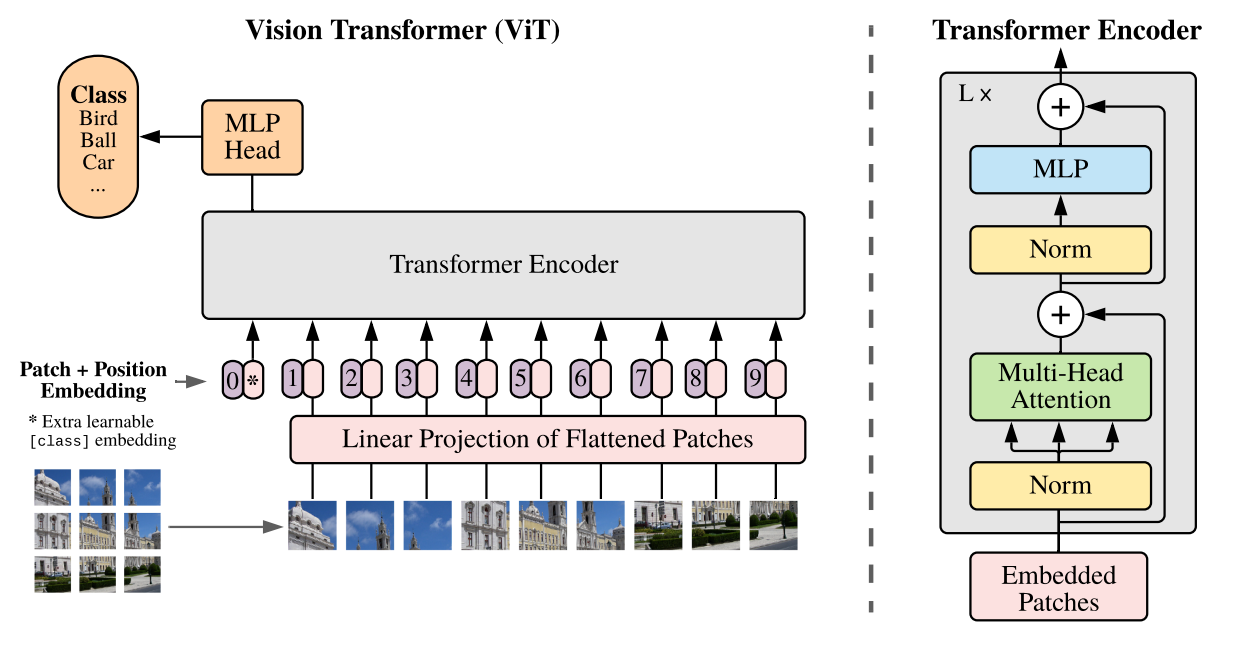
Vision Transformer[1]
そこで重みや活性化パラメータの表現精度を下げることで、効率を向上させるモデル量子化に関する研究がViTにおいても進められています。
FasterTransformerでは非線形演算以外の整数型への量子化に成功し、推論速度の向上を達成しています。しかしながら、非線形演算部はまだ効率化の余地を残しており、整数演算と浮動小数点演算の間のやりとりにおけるコストが生じているという課題があります。
そのためこの論文では、ViTにおける計算をすべて整数型で処理することが可能なI-ViTを提案しています。
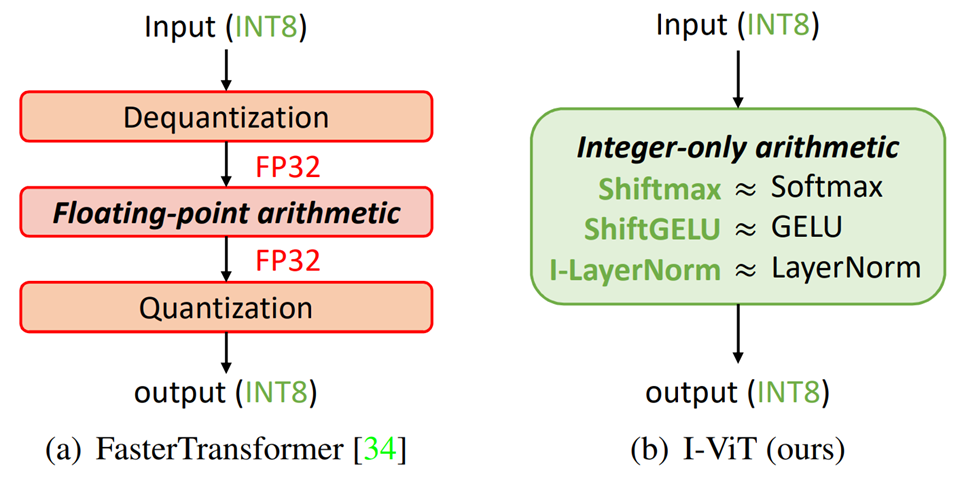
提案手法:I-ViT
全体像
提案手法I-ViTは完全に整数型のみで処理することができるViTです。
浮動小数点型から整数型に量子化する方法は以下の式で表されるsymmetric uniform quantizationを用いています。
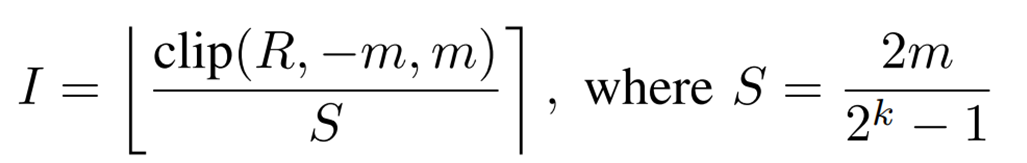
Rは浮動小数点値、Iは量子化された整数値を表しています。Sは量子化におけるscaling factorです。mはクリッピングの値、kは量子化ビット精度、[]はround関数です。
以下の図は提案手法I-ViTの全体像を示しています。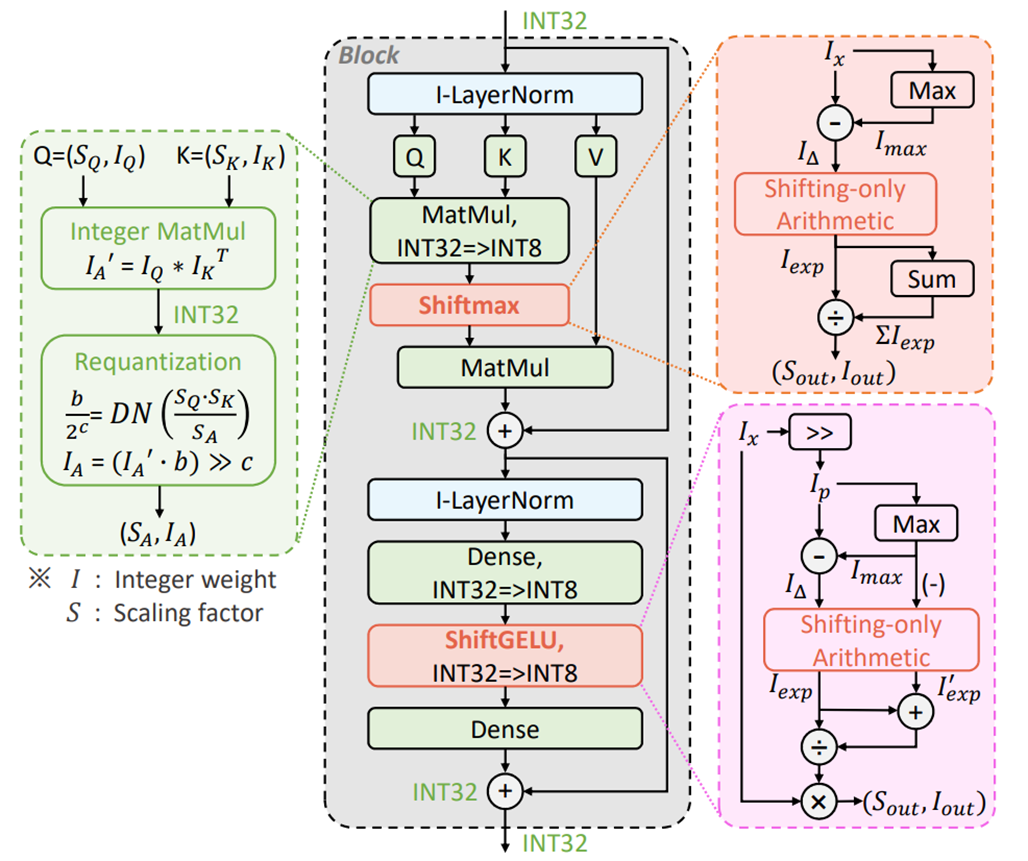
内積(MatMul)や全結合層(Dense)といった線形演算はDyadic Arithmeticを適用することで、整数型での演算を実現しています。
一方、Softmax、GELU、LayerNormといった非線形演算に対しては直接適用することができません。
そのため、それぞれ提案するShiftmax、ShiftGELU、I-LayerNormによって整数型での演算を実現しています。
I-LayerNormは以前紹介したI-BERTで採用されている方法と同じですが、ShiftmaxとShiftGELUはI-BERTでの方法をより進化させたものとなっています。
I-BERTについては以前AI-SCHOLARでも紹介しているので、本記事と併せてチェックしてみてください:I-BERT:整数型のみで推論可能なBERT
Dyadic Arithmetic for Linear
dyadic arithmeticはscaling factorにおける浮動小数操作を整数ビットシフトを用いて実現する方法で、これを用いることで線形演算が整数型のみで実現可能になります。
元々はCNNのために作られましたが、ViTにおける線形演算にも用いることができます。(embedding layerにおける畳み込み層、transformer layerにおける内積、全結合層)
ここでは内積を例にとって、計算方法を見ていきます。
![]() 、
、![]() としたとき内積
としたとき内積![]() は次のように表すことができます。
は次のように表すことができます。![]()
このとき、![]() はint32型となっているため、int8型に変換します。
はint32型となっているため、int8型に変換します。
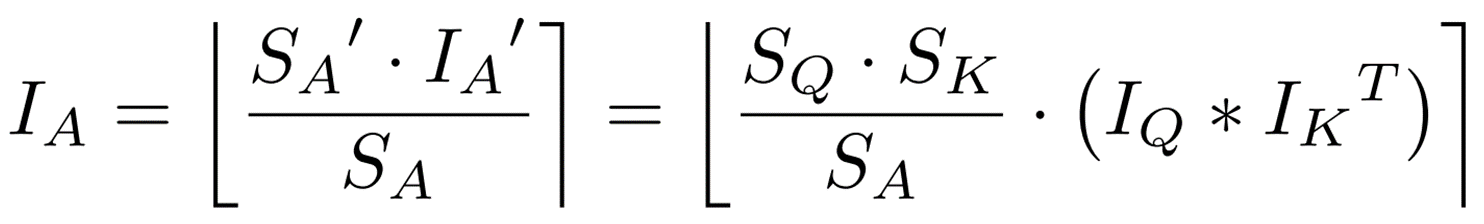
ここで![]() は予め計算された出力活性のscaling factorです。
は予め計算された出力活性のscaling factorです。
また、![]() はfloat型となるので、次の式でdyadic number(DN)に変換します。
はfloat型となるので、次の式でdyadic number(DN)に変換します。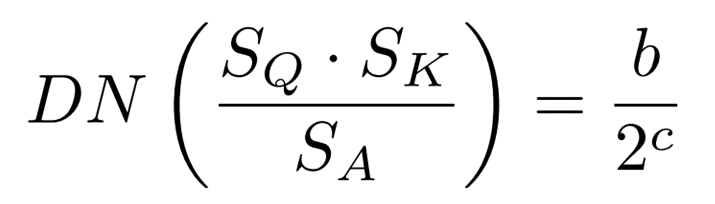 ここまでの操作をまとめると、int型のみの内積はビットシフトを用いて次のように計算することができます。
ここまでの操作をまとめると、int型のみの内積はビットシフトを用いて次のように計算することができます。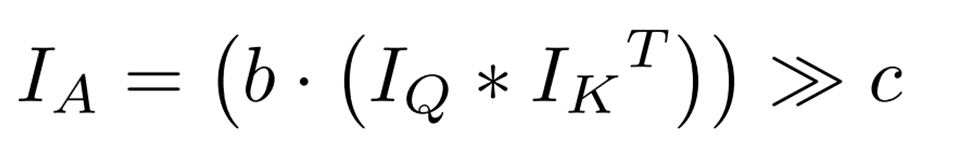
Integer-only Softmax: Shiftmax
ViTにおいてSoftmaxはattention scoreを確率に変換するために使われます。
Softmaxは非線形であるため、上で説明したdyadic arithmeticは直接適用できません。そのため、この論文ではShiftmaxを提案しています。
まず、Softmaxをscaling factorと量子化された整数値で表現すると次のようになります。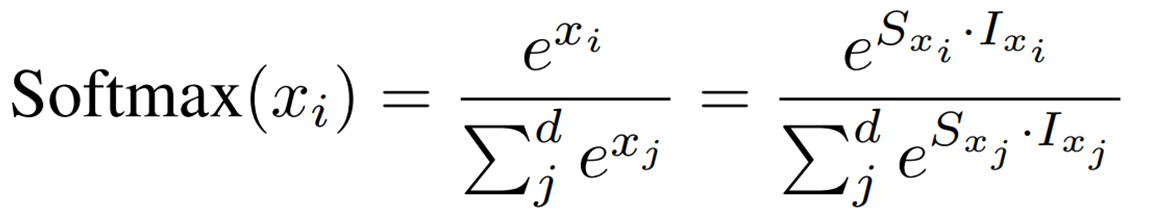
データ分布を滑らかにし、オーバーフローを防ぐため、次のように範囲の制限を行います。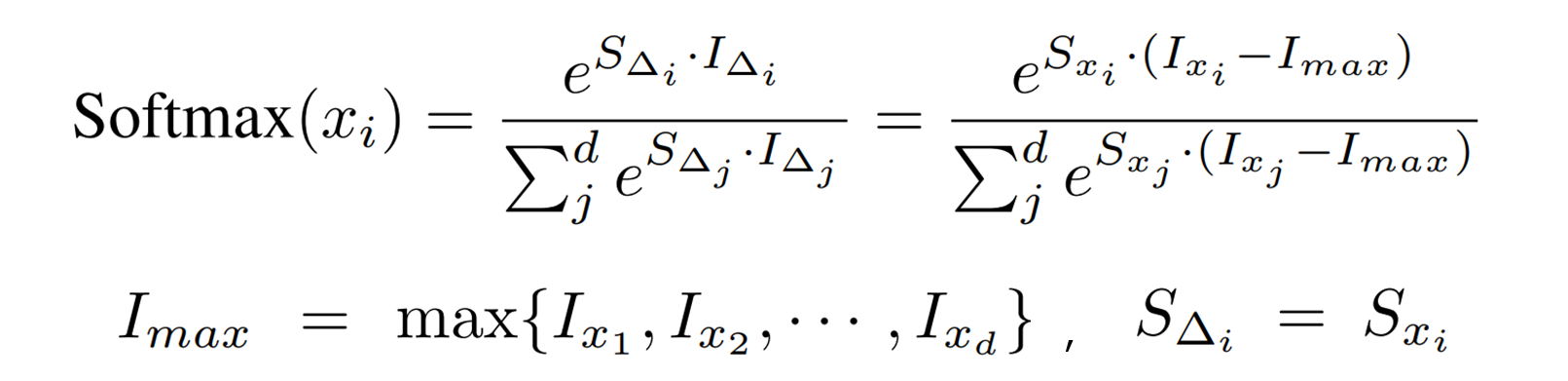
次にビットシフトで計算を行うために、指数関数の底をeから2に次のように変換します。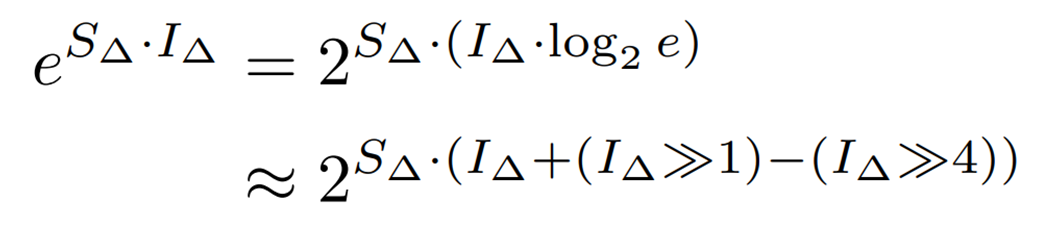 ここでは以下の近似を用いています。
ここでは以下の近似を用いています。
![]()
さらに ![]() は整数型ではないので、次のように
は整数型ではないので、次のように
整数部分(![]() )と小数部分(
)と小数部分(![]() )に分離します。
)に分離します。
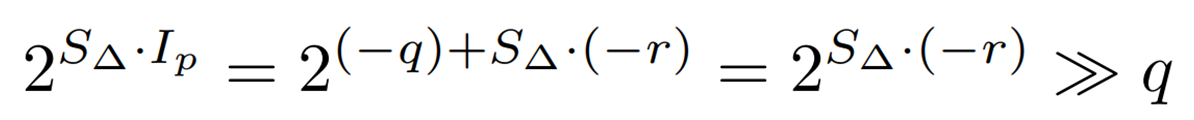
ここで計算量を削減するために、(-1, 0]の範囲の ![]() を次のように一次関数で近似します。
を次のように一次関数で近似します。
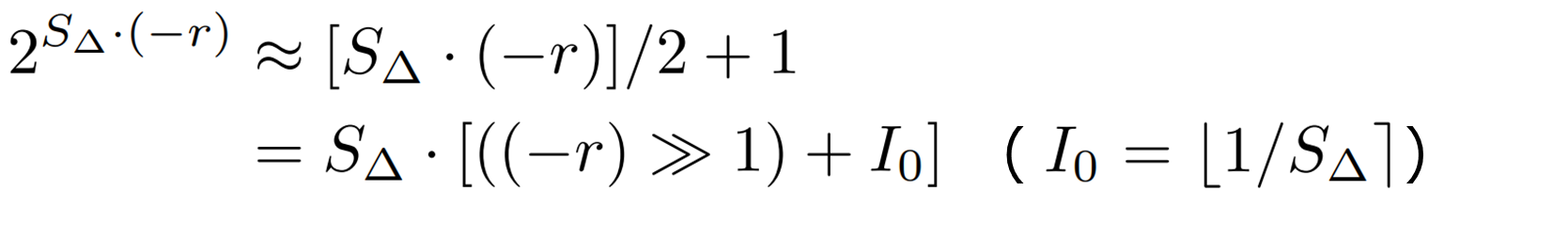
ここまでで、Softmaxにおける指数関数の計算がscaling factorと量子化された整数型の形で表せた ( ![]() ) ことになります(ShiftExp)。
) ことになります(ShiftExp)。
ShiftExpを用いて、Softmaxの整数型のみの演算である、Shiftmaxの最終的な式が次のように得られます。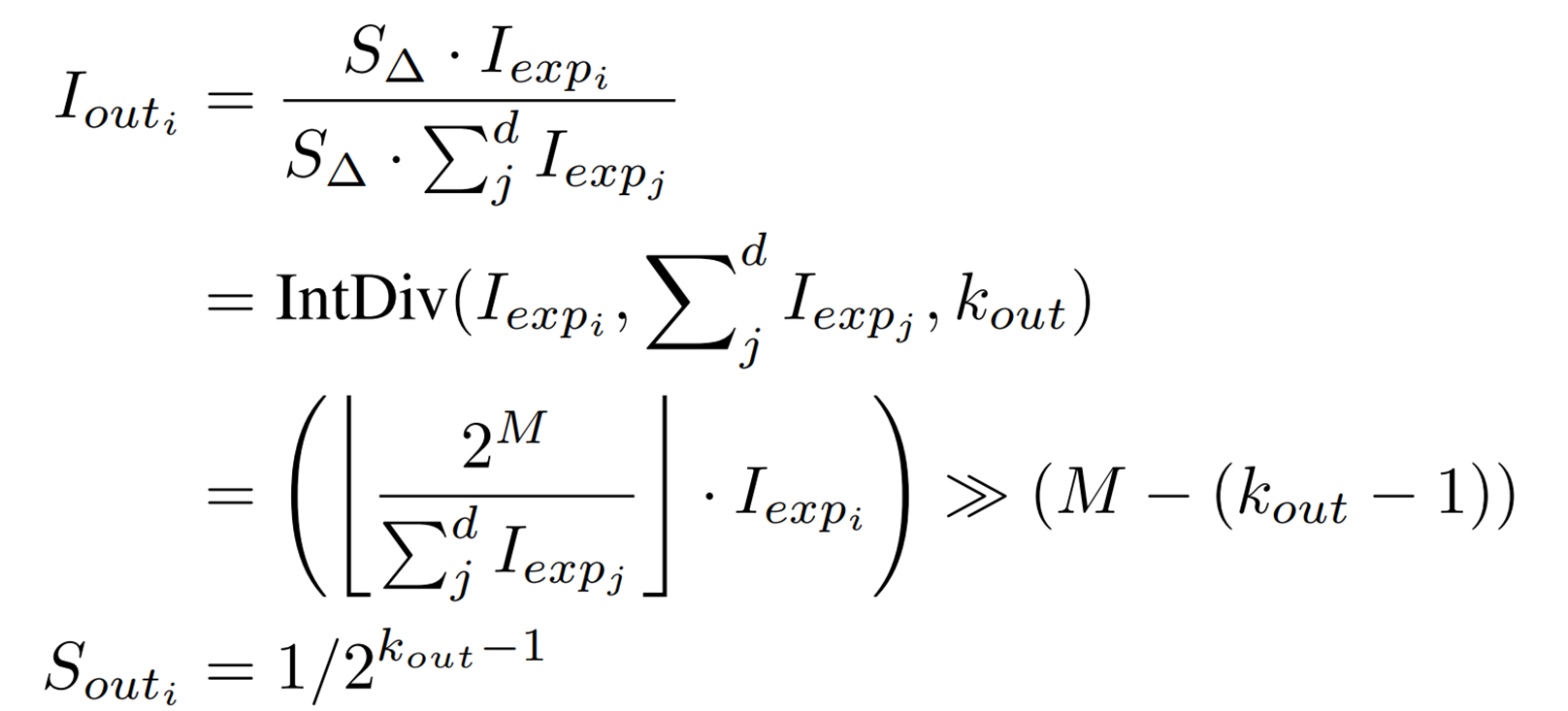
![]() はint型の割り算を行う関数であり、
はint型の割り算を行う関数であり、![]() は割られる整数、
は割られる整数、![]() は割る整数、
は割る整数、![]() は出力bit幅を表します。
は出力bit幅を表します。
最後にShiftmaxのアルゴリズムをまとめたものを以下に示します。

Integer-only GELU: ShiftGELU
GELUはViTにおける非線形活性化関数であり、シグモイド関数(![]() )を用いて次のように近似できることが知られています。
)を用いて次のように近似できることが知られています。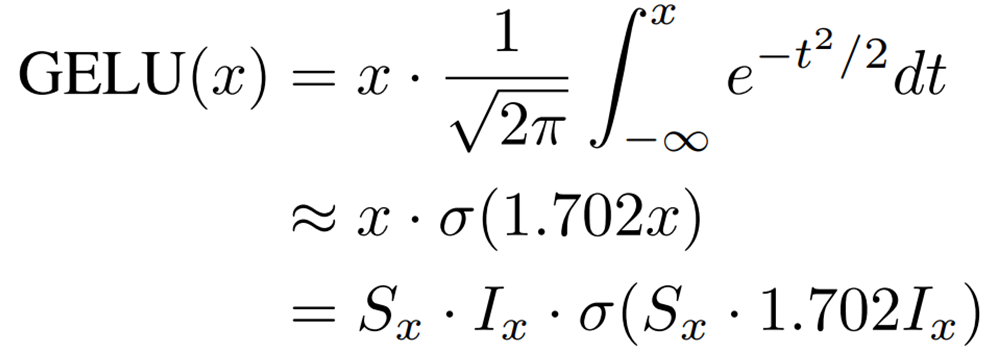
![]() なので、
なので、![]() はビットシフトを用いて次のように計算できます。
はビットシフトを用いて次のように計算できます。
![]()
また、シグモイド関数は次のように表現できます。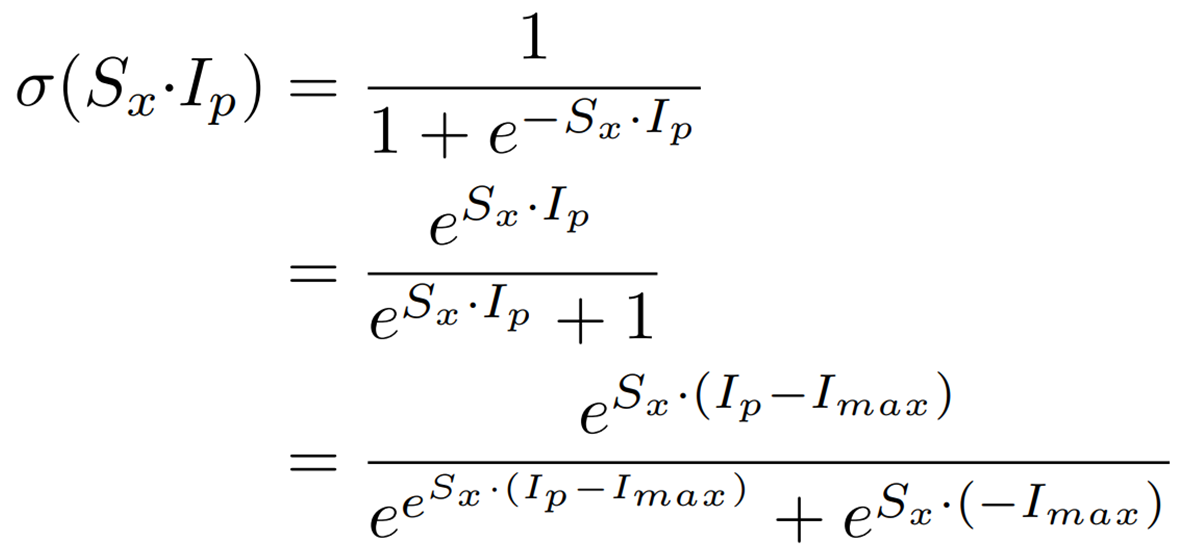
この式から、Shiftmaxで説明したShiftExpとIntDivを用いることで、シグモイド関数を整数型のみで計算できることがわかります。
最後にShiftGELUのアルゴリズムをまとめたものを以下に示します。
I-LayerNorm
LayerNormでは次のように隠れ層の特徴量を標準化します。
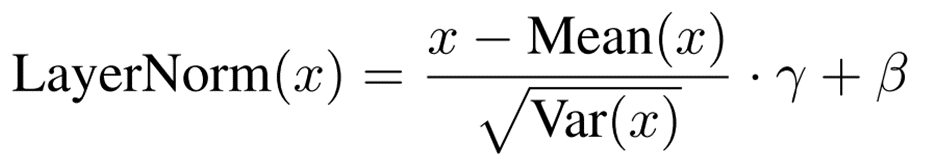
BatchNormでは学習によって得られた固定値を推論でも利用する一方で、LayerNormでは推論においても平均と標準偏差を計算する必要があります。
整数演算において、データの平均と分散は簡単に計算することができますが、標準偏差を求める平方根演算は行えません。
そのため、light-weight integer iterative approachをビットシフトを用いるように改良した方法を提案しています。
以下の漸化式を![]() となるまで最大10iteration繰り返します。
となるまで最大10iteration繰り返します。
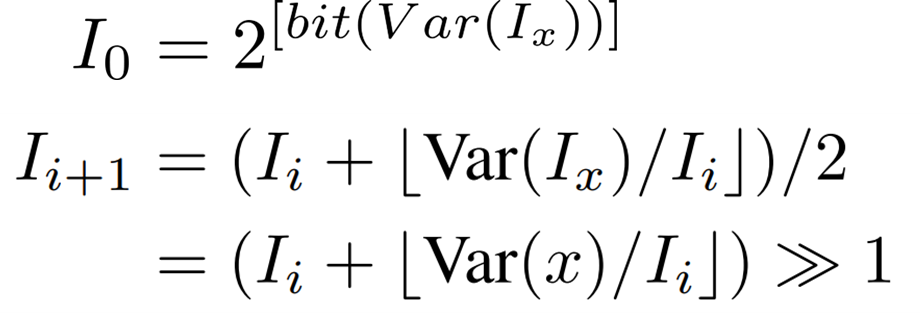
実験
実験方法
I-ViTの優位性を検証するために、大規模分類タスクのImageNet (ILSVRC-2012) において、精度と待ち時間の比較を行っています。
比較対象にはFPベースライン(量子化なし)の他に、Faster TransformerとI-BERTを用いています。また、モデルはViT、DeiT、Swimを用いています。細かい設定は補足[2]に示します。
実験結果
以下の表は実験結果をまとめたものです。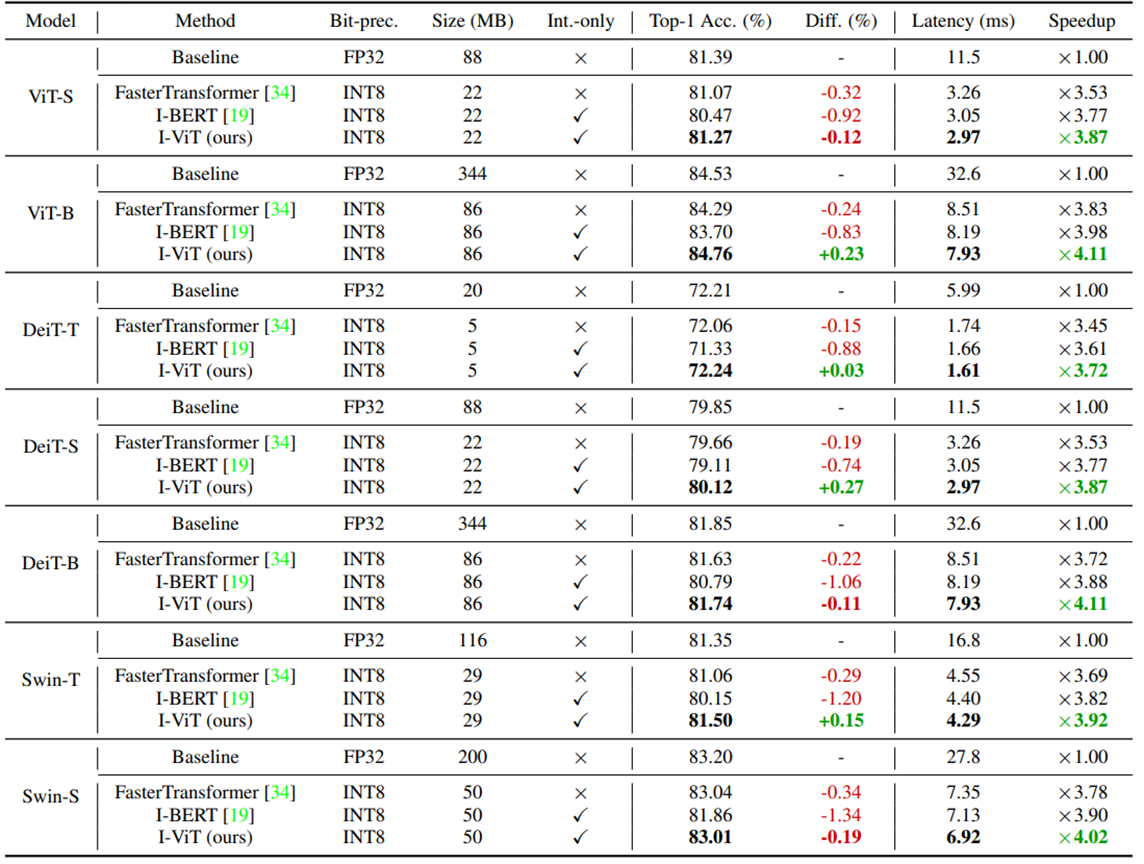
まず、精度(Top-1 Acc.)についてみていきます。
I-ViTはFP baselineとほぼ同等あるいは、多少上回る精度を示しました。DeiT-Sでは0.27%精度が向上しています。
また、FasterTransformerとI-BERTを上回る結果となっています。
特にI-BERTはSwim-SにおいてFP baselineと比較して1.34%精度を落としています。これは、I-BERTが言語モデルのために開発されたものであり、その近似の仕方が画像認識タスクに合わなかったためと考えられます。
次に待ち時間(Latency)についてみていきます。
I-ViTでは3.72~4.11倍のスピードアップを達成し、いずれもFasterTransformerやI-BERTを上回っています。
FasterTransformerでは非線形演算が浮動小数型のまま処理されているため、I-ViTに比べて劣る結果になったと考えられます。
I-BERTでは非線形演算も整数型で行われていますが、I-ViTはビットシフトを用いてハードウェア論理を最大限活用しているため、I-BERTよりも早い推論が可能になったと考えられます。
Ablation Study
実験方法
Ablation Studyとして、I-ViTで提案したShiftmax、ShiftGELU、I-LayerNormをそれぞれ既存手法に置き換えたときの精度と待ち時間の比較を行っています。
ShiftmaxはI-BERTで採用されている2乗多項式近似(Poly.)、FQ-ViTで採用されているLISと比較します。
ShiftGELUはI-BERTで採用されている2乗多項式近似(Poly.)、I-LayerNormはFully-8bitで採用されているL1 LayerNormと比較します。
実験結果
以下の表はAblation Studyにおける実験結果をまとめた表になります。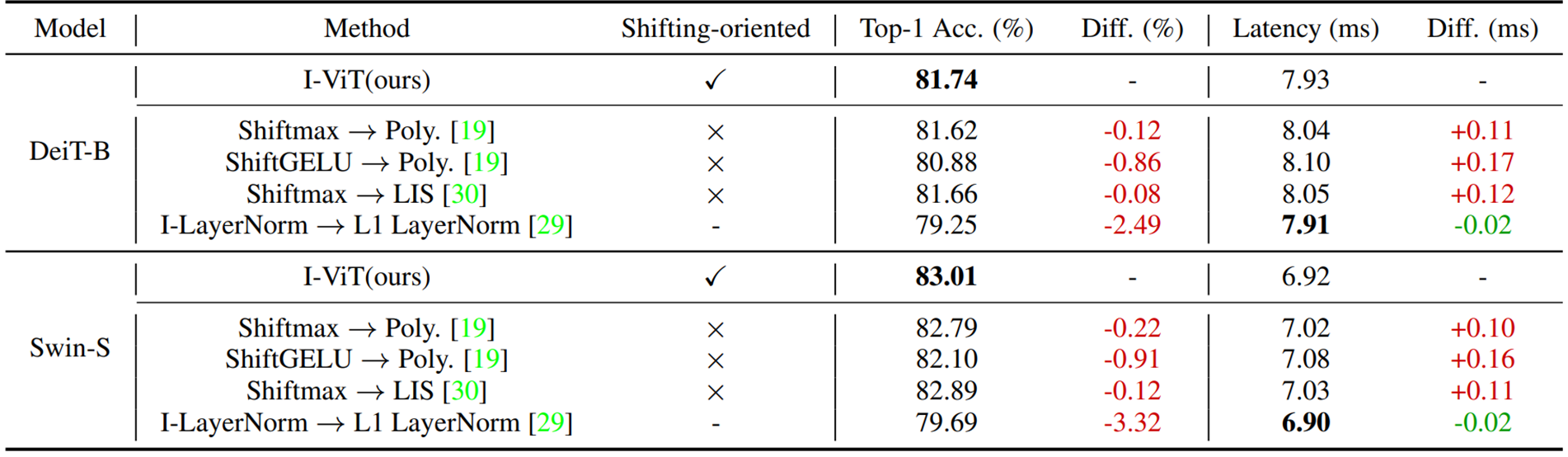
DeiT-B、Swin-Sのいずれにおいても、ShiftmaxとShiftGELUをそれぞれ既存手法に置き換えると精度が低下し、待ち時間も悪化することが分かります。特にShiftGELU→Poly.において精度悪化が0.86%、0.96%と大きくなっています。この結果は特定区間のみを近似するpolynominal GELUがViTにはうまく適用できていないことを示唆するものとなっています。
また、速度の低下は2乗多項式(Poly.)とLISと比べて、Shift-*がハードウェア論理を効率的に活用できている点に起因するものだと考えられます。
I-LayerNorm→L1 LayerNormでは、精度が2.49%、3.32%と大きく悪化した一方で、0.02ms待ち時間が短くなっています。
L1 LayerNormはI-LayerNormに比べて計算を単純化しているため、高速化は実現できているものの、精度が保てていないことがこの結果から確認できます。
まとめ
今回はすべての計算を整数型で実現したVision Transformerであるi-ViTについて紹介しました。
I-BERTと同様、ほとんど精度が低下せず、3.72~4.11倍のスピードアップを達成できた点が大きな魅力だと思います。
また、I-BERTでは2乗多項式近似を用いて、SoftmaxやGELUの整数型での計算を実現していましたが、I-ViTで採用されているShiftmaxやShiftGELUを自然言語処理モデルBERTに対して適用したらどうなるのか気になりました。
今後、高精度なモデルがもっと手軽に動かせるようになっていくのではないでしょうか。
補足
[1] Vision Transformerの原著論文:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
[2] Optimizer:AdamW
学習率:(2e-7, 5e-7, 1e-6, 2e-6)でチューニング
batchsize:8
GPU:RTX 2080 Ti
*学習済みの重みを量子化したものを初期値としてFineTuningしている。



この記事に関するカテゴリー






