
Sparse Transformers:入力シーケンスの長さによる計算量増加問題への革新的なアプローチ
3つの要点
✔️ Attentionのレイヤー毎の特徴を再現することで,計算量の削減を達成
✔️ Sliding Window Attenion、Dilated Sliding Window Attention、Global Attentionという3つのAttentionを使ってTransformernの計算量を削減した
✔️ 計算量を削減しただけではなくて,当時のSOTAを達成している.
Generating Long Sequences with Sparse Transformers
written by Rewon Child, Scott Gray, Alec Radford, Ilya Sutskever
(Submitted on 23 Apr 2019)
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
Sparse TransformersはTransformerのself-attentionの計算量が,$O(n^2)$であり,長い文章を入れると,メモリの使用量が急増する問題に対して,attentionの向ける向きを工夫することで対応しようとしたものです.
Transformerの問題点とは
Transformerは計算量が入力シーケンスに伴って2次的に増加していきます.これにより,メモリの使用量も計算時間も非常に長くなります.
なぜなら,Transformerの主要パーツである,Scaled Dot-Product Self-Attentionのせいです.そもそも,Scaled Dot-Product Self-Attentionとは,クエリとキー・バリューののペアを使ってAttentionを計算するものです.つまり,Scaled Dot-Product Self-Attentionの計算式は,クエリ,キー,バリュー($Q,K,V$)を用いて,
$$Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}}V)$$
で示されます.この時に,クエリとバリュー(Q,V)の積は文書の長さ($n$)の二乗になります.そのため,2046トークンが入力として与えられた時にAttentionの計算に用いる行列サイズは,2024*2024となり,約410万要素を持つ行列をAttentionの計算で処理しなければならなくなります.これがバッチサイズ分必要となり,計算も膨大になり,メモリ容量を圧迫します.
そこで,このTransformerの問題である入力シーケンスの2乗に伴って計算量が増加する問題に取り組んだのが本論文であるSparse Transformersです.
Sparse Transformersを用いた結果
Sparse Transformersを用いた結果どれほどメモリの使用量が抑えられたのかをまず確認します.具体的には下記のTable1のように画像,言語,音声全ての領域において当時のSotaを達成しています.また,実際にテストに使用された環境についても説明します.
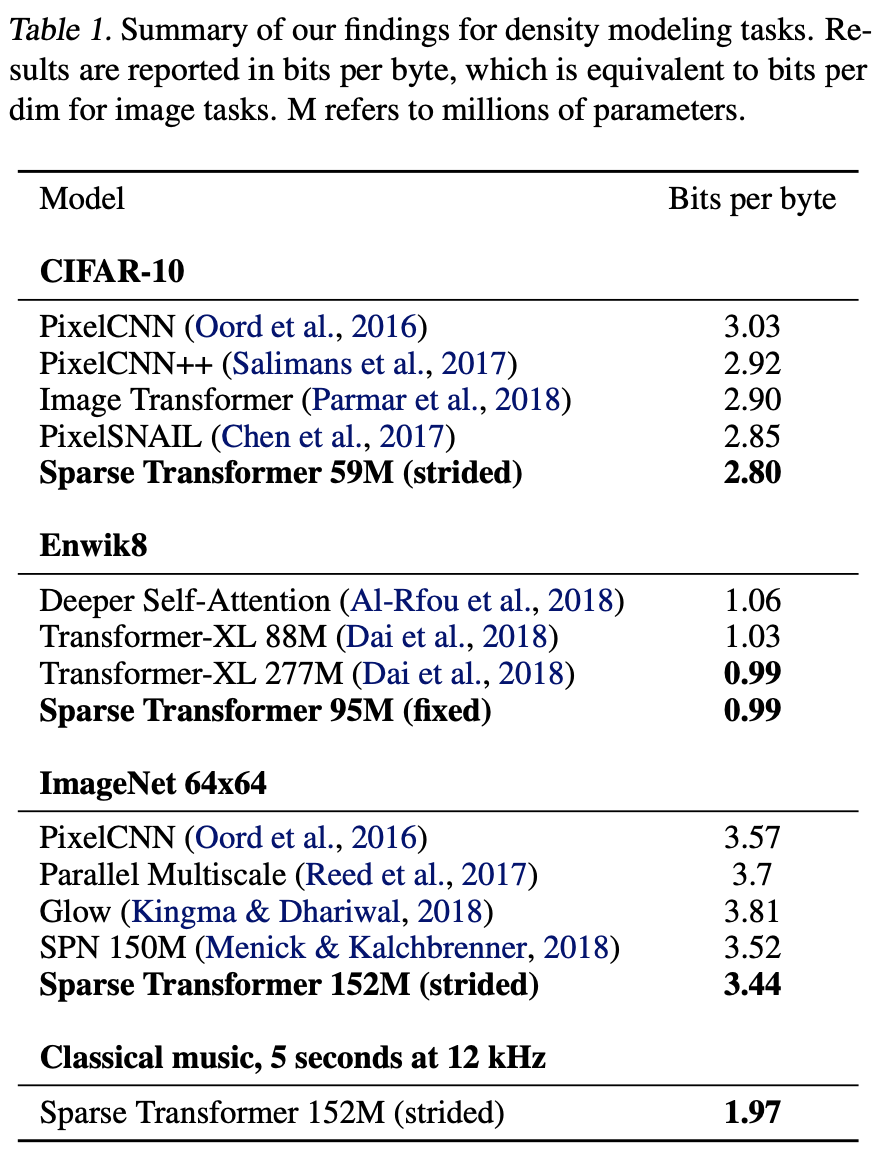
CIFAR-10
そもそも,CIFAR-10自体が,32×32ピクセルのカラー画像であるため,一枚の画像の入力シーケンス長は32×32×3=3072バイトとなります.これをstrided Sparse Transformersで学習します.パラメーターなどはそれぞれ,headが2つ,128層,$d$=256をhalf-size feedforward networkで学習させます.学習率が0.00035,バリデーション誤差が減少しなくなるまでドロップアウト率0.25でエポック数が120epochsです.
学習に用いたデータは48000サンプルを用いて,バリデーションには2000サンプルを用いてモデルの性能評価を行いました.この結果従来のChenらの2.85を上回り,2.80と発表当時のSotaを達成しています.
Enwik8
Enwik8データセットでSparse Transformersを評価することで,より長いシーケンスの入力に対して評価を行っています.Enwik8データセットの文章の長さは12,228で長いシーケンスの入力となっています.
また,学習は30層のfixed Sparse Transformersを用いて,最初の9000万トークンを用いて学習し,最後の1000万トークンはバリデーション用とテスト用としています.学習パラメーターはヘッド数8,$d$=512,ドロップアウト率が0.40の128ストライド,c=32でエポック数は80epochsです.
その結果,発表当時のSotaであり,同様のサイズであるTransformer-XL(Dai et al.、2018)のら1.03を上回り,0.99を達成しました.
ImageNet64×64
ImageNetとCIFAR-10は同じ画像系の出たセットですが,違いは入力シーケンスの長さの違いです.ImageNet64×64では,CIFAR-10よりも4倍長い系列を扱う必要があります.そのため,長期記憶をstrided Sparse Transformersがちゃんと保持できるかどうかのためのテストとなっています.
ImageNet64×64を用いた実験では,16のAttention Headsと$d$=512で合計1.52億パラメーターを持つ48層のstrided Sparse Transformersを用いて学習を行いました.また,パラメーターはストライドを128,ドロップアウト率を0.01,エポック数は70epochsとして検証したようです.
その結果,従来の3.52(Menick & Kalch- brenner, 2018)と比較して、3.44bit per dimまで削減しました.また,視覚的評価により,ほとんどの画像において長期構造を捉えた生成が行えていることがわかります.
Classical music
Sparse Transformerが非常に長いコンテキスト(Enwik8の5倍以上)に対してどの程度対応できるのかの検証を目的に(Dieleman et al., 2018)が公開したクラシック音楽のデータセットでモデルを訓練したそうです.ただ,著者らも,データセットの詳細が手に入れられていないために既存研究との比較ができないとのことを指摘しています.
ただ,(Dieleman et al., 2018)が公開したクラシック音楽のデータセットを用いたことで,極めて少ないパラメーターであるにもかかわらず,多くのタイムステップでのself-attentionを実行できたと主張しています.実際に,以下で聴くことができます.
https://openai.com/blog/ sparse-transformer
Sparse Transformersではどのような工夫をしたのか?
Sparse Transformersを用いることで大幅に計算量を抑えることができました.Sparse Transformersは一体どのようなアイディアで出てきたのかから,実際にどのような仕組みで計算量を削減したのか直感的な理解を目指して紹介していきます.
既存のAttentionの理解
Sparse Transformersを考える上で,既存のAttentionがどこに向いているのかを理解することは重要です.筆者らも既存のAttentionがどこを向いているのかをレイヤーごとに可視化しています.具体的には,下記のFigure 2のように128層あるネットワークでCIFAR-10を訓練した結果を示しています.

その結果,
(a)が示すネットワークの初期層においては,白くハイライトで示されている直前の情報にattentionが向いていることがわかります.
(b)が示す19・20層においては,行方向と列方向にAttentionが向けられていることがわかる.これは,帯域的な特徴を効果的に学習していると考えられます.
(c)が示しているのは画像全体にAttentionが散らばっていることです.
(d)64層から128層にかけてはスパース性を示しており,どこにAttentionが向けられているかわからない状況になっています.
Sparse Transformersでは,これらの既存のAttentionの特徴を踏まえてより効率的なAttentionの設計を試みるものです.
Sparse TransformersのAttentionの工夫
Sparse TransformersのAttentionでは,先ほどの(b)と(c)のAttentionの特徴を利用します.
論文の図に従って,6×6の画像の例で考えます.
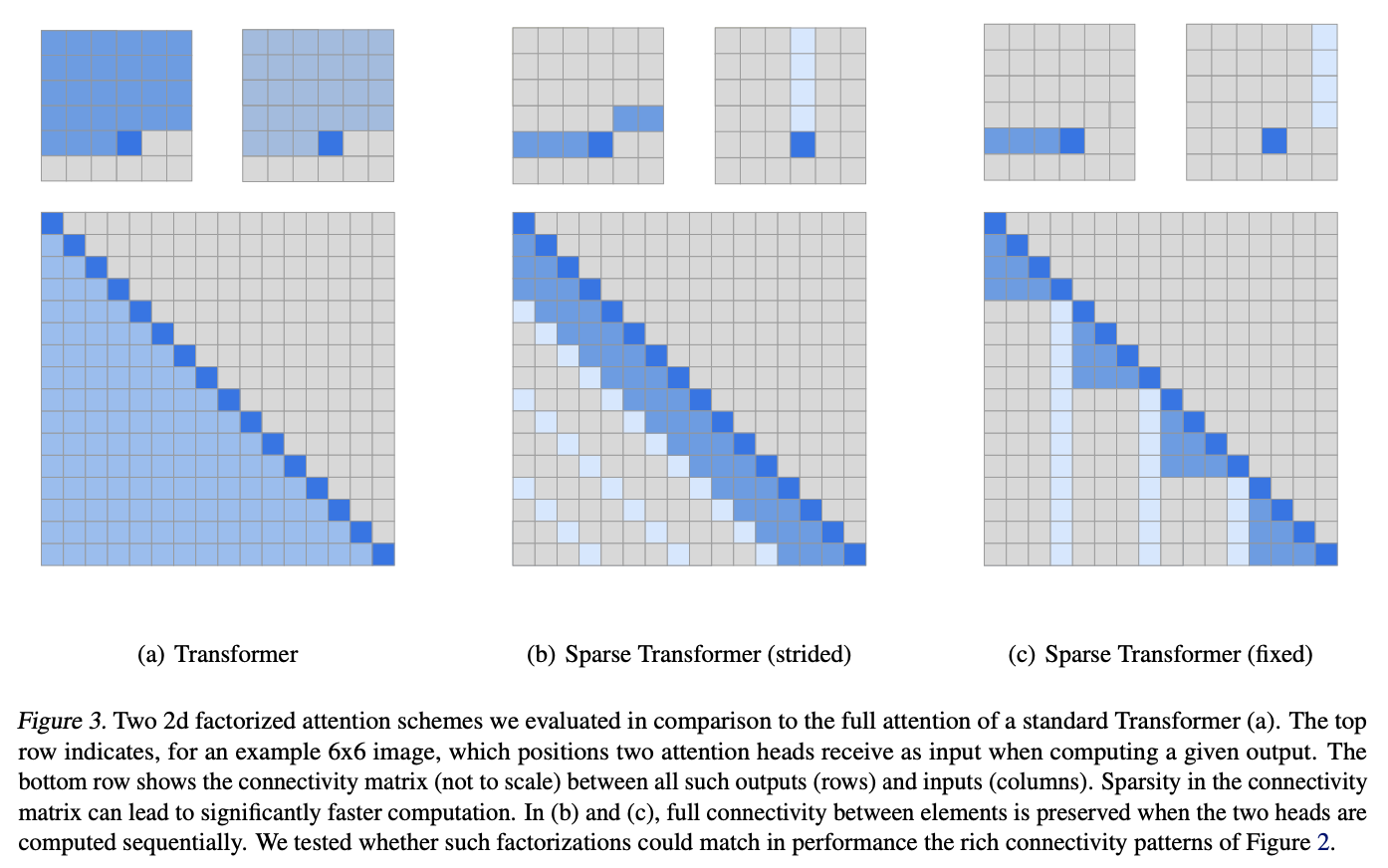
・(a)Transformer(Full Attention)
Figure3(a)のAttentionは通常のtransformerで用いられているattentionで自分自身より前の位置全てにアテンションを向けています.このため計算量は$O(n^2)$となります.
・(b)Sparse Transformers(Strided Attention)
Figure3(b)のAttentionはヘッドを2つに分割しています.青色の方は自分自身の位置よりも前の全ての要素に対してAttentionを向けるのではなく直近の3つにだけAttentionを向けています.一方,水色の方は3つおきにAttentionを向けています.
要するに,青色は横方向に,水色は縦方向にAttentionを向けています.これは先ほどの画像の(b)の状態のAttentionのパターンを再現しています.
また,このようなAttentionは画像や音声など周期的な傾向のあるデータに関して有効なことが実験で示されています.
・(c)Sparse Transformers(Fixed Attention)
Figure3(c)のAttentionは(b)のStrided Attentionが相対的な位置を用いてAttentionを向けていたのに対して,(c)のFixed Attentionでは絶対的な位置の要素も付け加えてAttentionを向ける位置を決定しています.そのため,青色で示されているものは自分自身より前のいくつかの要素にAttentionを向けていますが,水色で示されている要素は一定間隔で縦方向全てにAttentionを向けています.
このようなAttentionは文章などのテキスト情報に有効であることが実験によって示されています.
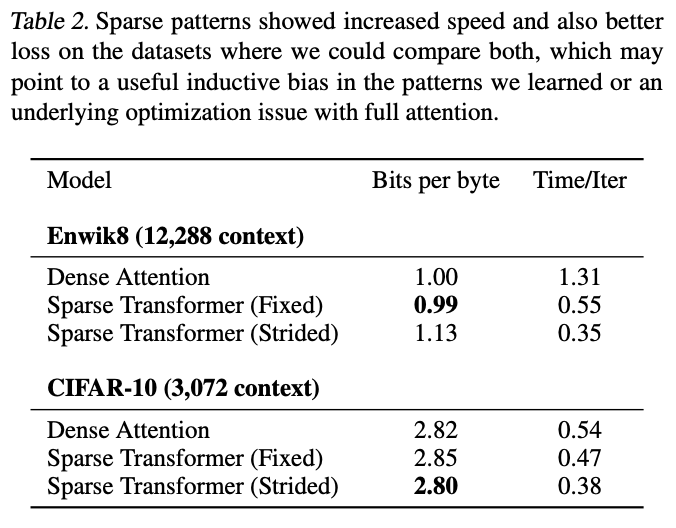
Sparse TransformersのStrided AttentionとFixed Attention
Strided AttentionとFixed Attentionを画像とテキストデータに用いた実験の結果,
- Strided Attentionは画像のデータセットにおいて有効であり
- Fixed Attentionはテキストデータセットにおいて有効である
ことが判明しています.
まとめ
Sparse Transformersでは,既存のAttentionのレイヤーごとの挙動について調査し,重要と思われる行方向と列方向,全体をまんべんなく見るといった挙動をStrided AttentionとFixed Attentionという2つの新たに導入したアーキテクチャーで再現することができ,旧来のtransformerの計算量の問題を解決し,発表当時のSotaを幾つも達成しました.
他にもSparse Transformers以降transformerの計算量の最適化は試みられてきています.よろしければ他のLongnetなども参照ください.






この記事に関するカテゴリー





