
【MusicLM】Googleが開発したText-to-Musicの生成モデル
3つの要点
✔️ テキストプロンプトから高品質な音楽を生成
✔️ Googleがこれまで培ってきた英知を結集したプロジェクト
✔️ テキストと音楽のペアデータセット「MusicCaps」を公開
MusicLM: Generating Music From Text
writtenby Andrea Agostinelli, Timo I. Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, Matt Sharifi, Neil Zeghidour, Christian Frank
(Submitted on 26 Jan 2023)
Comments: Supplementary material at this https URL and this https URL
Subjects: Sound (cs.SD); Machine Learning (cs.LG); Audio and Speech Processing (eess.AS)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
この研究では、Googleによって発表されたText-to-Musicの生成AIである「MusicLM」が開発されました。このモデルでは、例えば以下のようなテキストプロンプトがあったとします。
The main soundtrack of an arcade game. It is fast-paced and upbeat, with a catchy electric guitar riff. The music is repetitive and easy to remember, but with unexpected sounds, like cymbal crashes or drum rolls.
MusicLMは、このようなテキストを入力として受け取り、そのテキストに沿った音楽を生成するのです。上記のような、具体的な文章でも生成可能である点は、とても魅力的です。実際にMusicLMによって生成された音楽は、以下のページで聴くことができます。
クオリティは非常に高いです。
このようなハイクオリティの音楽を生成できる秘訣は、Googleによる過去の研究の蓄積にあります。Googleは世界を代表する大企業ですから、当然これまで数多くの研究成果を出しています。
本研究においても、それらの研究成果を余すことなく活用しています。では一体、どのような研究を活用しているのか、次のセクションで見ていきましょう。
手法
Googleの先行研究を振り返りながら、本研究のモデル構造を見ていきましょう。
構成要素
MusicLMのモデルの構成要素は、以下の通りです。

左から「SoundStream」「w2v-BERT」「MuLan」です。これら3つは、もともと独立した表現学習の事前学習済みモデルです。上記の3つを、以下の画像のように組み合わせることで、音楽を生成します。 
上図の右下の「Hip hop song with violin solo」というテキストがプロンプトで、その上の「Generated audio」という波形が、生成される音楽に当たります。
AやらSやら様々な記号がありますが、これ以降で詳しく説明します。まずは、それぞれの構成要素を順番に見ていきましょう。
・SoundStream
SoundStreamとは、音声データの圧縮用の「ニューラルコーデック」です。この技術は、音声や音楽を非常に小さな情報のかたまりに変換する「エンコーダー」と、その小さな情報を元の音声や音楽に戻す「デコーダー」の2つの部分から成り立っています。

SoundStream: An End-to-End Neural Audio Codec
SoundStreamでは、「入力された波形」と「Decoderが出力する波形」が等しくなるように、End-to-Endで学習されます。推論では、エンコーダとRVQによって圧縮されたデータを受信機に送信し、受信機は受け取ったデータをデコーダに通して、音声として出力します。
SoundStreamの最大の特長は、非常に低いデータ量でも高品質な音声を実現できる点です。たとえば、通話中にインターネットの接続が不安定になっても、SoundStreamは自動的にデータ量を調整し、通話の品質を維持できます。
MusicLMでは、主に「生成された音声の出力」の役割を担っています。SoundStreamを利用することで、高品質な音声の出力を、効率的に行えるのです。
・w2v-BERT
w2v-BERTは、音声から意味を抽出するための「音声認識システムのベースモデル」です。Googleが開発したもので、「音声を理解する技術」と「文章を理解する技術」を組み合わせたものです。w2v-BERTでは、先行研究のwav2vec 2.0の技術を拡張して、対照学習やMLMなども取り入れています。
モデル構造は、以下の通りです。

w2v-BERTは、以下の3つのモジュールから構成されます。
- Feature Encoder: 入力音声を圧縮して潜在表現を出力
- Contrastive Module: 対照学習によって「音声の前後の文脈」を学習
- Masked Prediction Module: BERTでも使われたマスク推定
こうすることで、音声をより正確に言語的な意味に変換することができます。MusicLMでは、主に「プロンプトの文章」と「出力する音楽」を繋げる役割を担っています。
・MuLan
MuLanは、関連のあるテキストデータと音楽データを結びつける「対照学習モデル」です。こちらもGoogleの研究で、「音楽」と関連のある「テキスト」を結びつけるマルチモーダルモデルです。対照学習を用いており、音楽データのEmbeddingとテキストデータのEmbeddingとの距離が、近くなるように学習されます。
学習方法は、以下の通りです。
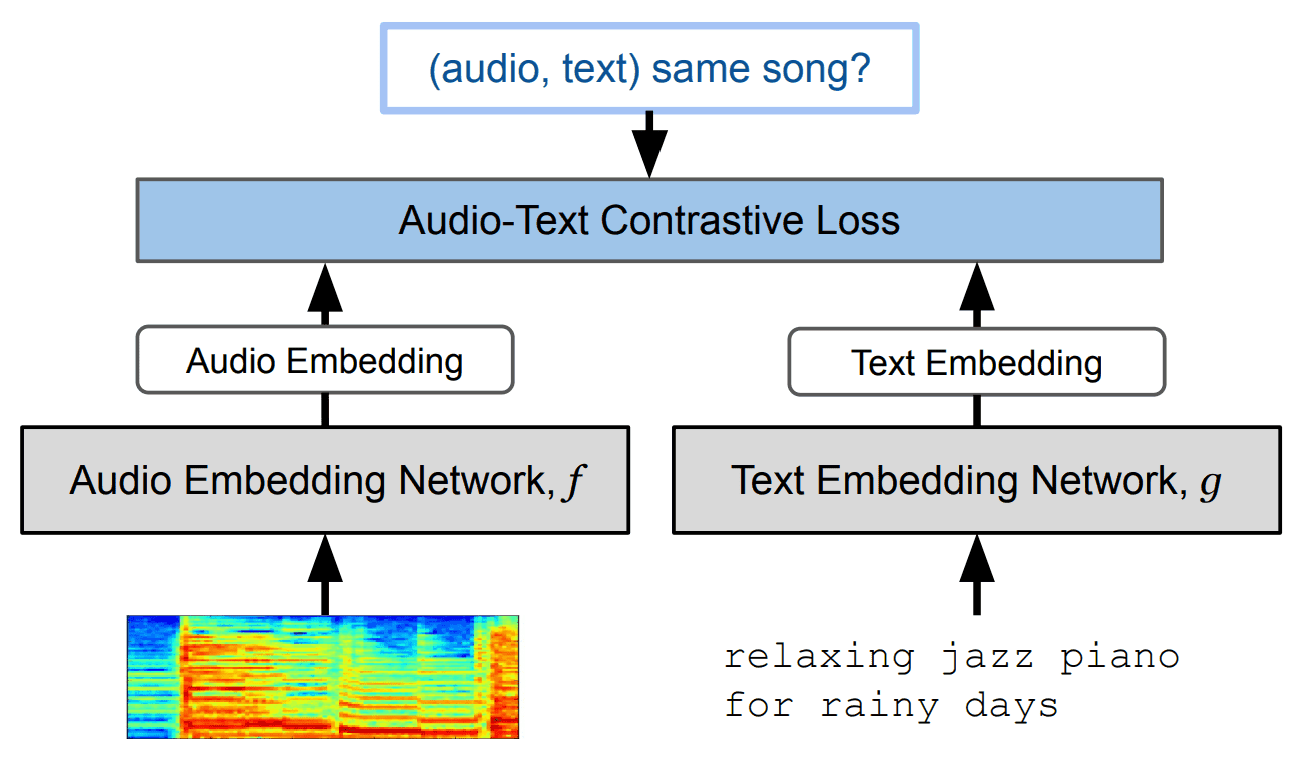
MuLan: A Joint Embedding of Music Audio and Natural Language
このモデルを用いることで、音楽とテキストの関連性・類似性を数値化できるようになるのです。ちなみに、音楽とテキストのエンコーダには、以下の2つを使用しています。
- 音楽エンコーダ: 事前学習済みのResnet-50・AudioSpectrogramTransformer(入力はlog-mel spectrogram)
- テキストエンコーダ: 事前学習済みBERT
MusicLMでは、主に「テキストプロンプトのエンコーダ」の役割を担っています。
学習過程
MusicLMの構成要素は、これまで見てきたとおりです。学習の方法は、以下の通りです。

見ての通り、MusicLMの学習ではテキストプロンプトは不要です。ここで、AやらSやらの記号の意味を、以下に示します。
- MA: MuLanの音楽エンコーダによって得られたトークン
- S: w2v-BERTによって得られた「音楽の意味」を表すトークン
- A: SoundStreamによって得られた「音声」を表すトークン
また、学習の手順は以下の通りです。
- 再生成したい音楽(Target Audio)をMuLan・w2v-BERT・SoundStreamそれぞれに入力
- MuLanの音楽エンコーダによってMAを生成
- MAを条件として、デコーダのみのTransformerでSを生成
- MAとSを条件として、デコーダのみのTransformerでAを生成
さらに、上記の手順で得られたAと、「入力音楽をSoundStreamに入力して得られるA」が近くなるように学習されます。
学習では、500万曲(28万時間分)の音楽データが利用されています。
推論過程
実際にMusicLMで音楽を生成する時は、テキストプロンプトを入力し、それをMuLanのテキストエンコーダに通します。その後は、先ほどの学習と同様の手順です。
実験
本研究のモデル評価では、MusicLMに加えて、以下の2つの音楽生成モデルとの比較実験を行っています。
- Mubert
- Riffusion
この実験で着目する点は、以下の2つ。
- 音楽の品質
- テキスト記述の精度
本実験で用いた評価指標と意味は、以下の表の通りです。
| 評価指標 | 意味 |
|---|---|
| FADTRILL(値が低ければ良い) |
人間の聴覚を考慮した音質評価の指標(音声データで学習されたTrill2に基づく) |
| FADVGG(値が低ければ良い) |
人間の聴覚を考慮した音質評価の指標(YouTubeの音声データで学習されたVGGish3に基づく) |
| KLD(値が低ければ良い) |
入力されたテキストプロンプトと、生成された音楽との整合性を評価 |
| MCC(値が高ければ良い) |
MuLanによって、「音楽」と「そのテキスト」がどれくらい似ているかをコサイン類似度で計算 |
| WINS(値が高ければ良い) |
pairwise testの結果の「勝ち」の数(値が高ければ良い) |
上記の「WINS」は、pairwise testによって得られた評価値です。このテストは、「生成された音楽」と「テキスト記述」との整合性を評価するために、被験者に評価させたものです。被験者に提示されたテストの画面は、以下の通りです。

たとえば「どちらの曲が良いですか?」のような質問をされます。
データセット
著者らはMusicLMを評価するために、本研究の功績の一つである「MusicCaps」というテキストキャプション付き音楽データセットを作成し、一般に公開しています。MusicCapsは、以下のKaggleページに公開されており、無料で自由に利用可能です。
このデータセットには、5.5kの音楽データが含まれています。それぞれの音楽データには、その音楽を説明している文章が付いています。その文章は10人のミュージシャンによって、英語で書かれています。テキストキャプションの例は、以下の通りです。

MusicLM以降に出てきたText-to-Musicの研究では、モデルの評価のために、このMusicCapsがベンチマークとしてよく使われるようになりました。
結果
比較実験の結果は、以下の表の通りになりました。

この結果より、MusicLMはすべての指標において最高点を叩き出しています。よって、MusicLMは音質・テキストプロンプトとの整合性ともに、Mubert・Riffusionよりも高いことが分かりました。
まとめ
本記事では、Googleによって開発されたText-to-Musicの生成モデル「MusicLM」について、ご紹介しました。
本研究の功績は、高品質な音楽生成を可能にしたことだけでなく、MusicCapsというデータセットを作成したことにもあります。このデータセットのおかげで、Text-to-Music分野のさらなる発展が期待できそうです。
さらに、MuLanという対照学習モデルを使用して、音楽とテキストの整合性を保った点に関しても、非常に興味深かったと思います。
ちなみに、恐らく著作権や作品の盗用などの観点から、MusicLMのモデルの公開予定はなさそうです。



この記事に関するカテゴリー





