データセットに潜む方言・人種バイアスと向き合う
3つの要点
✔️アフリカ系アメリカ人英語 Africal American English(AAE)に対して内容と関係なく、有害であるとアノテーションされる傾向が強いことが分かった。
✔️学習したモデルは最大で2倍もAAEに対して攻撃的な内容であると判断する傾向にあり、バイアスを学習してしまう。
✔️方言によって生じるバイアスを避けるためのアノテーション手法の提案を行い、バイアスを削減した。
前書き
現在のSNSで攻撃的な投稿への対応は重要視されており、コンテンツの自動削除の導入も進んでいます。しかし、自動削除には少数意見をさらに抑制してしまうというリスクも伴い、導入に際して注意深く検討する必要があります。

図1 Jigsawが公開している有害なコメントを検出するAPIの結果
AAEの話者は従来の差別的な意味合いとは異なり、フランクに”What’s up, n*gga!”のような表現を用います。しかし、話者がどういった人物かというメタデータを持たないアノテーターにとっては差別的な発言であるとラベル付けしやすくなってしまいます。この結果アフリカ系アメリカ人の発言が内容とは無関係に攻撃的であると予測しやすいモデルができ、意図しない人種差別に繋がる可能性が生じます。
論文内で示されているAAEなどの判定はデータセットのメタ情報ではなく、Twitterのデータセットから学習させたモデルによって推論されたものを利用しています。また、本論文ではヘイトスピーチ検出における著名な2つのデータセットであるDWMW17とFDCL18を主に分析しています。
有害コメント検出データセットにおけるバイアス
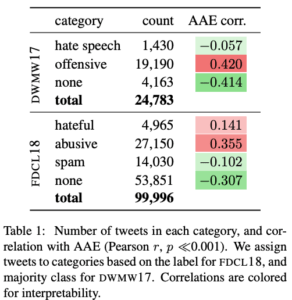
表1 データセット内のラベルとAAE話者の相関係数
表1では各データセットが有害かどうかなどの各カテゴリと、AAEの投稿との相関係数を示しています。
DWMW17では攻撃的である(offensive)と判断されることとAAE話者であることの相関が0.420で、またFDCL18では悪口である(abusive)と判断されることとAAE話者であることの相関が0.355です。AAEの話者であることと投稿が攻撃的な内容やヘイトスピーチに類する内容であることとの相関が非常に高く、データセット自体にAAE話者に対するバイアスが含まれている可能性を示唆しています。
データセットのバイアスはモデルにも伝わる
DWMW17とFDCL18によって学習されたモデルで他のTwitterから得られたデータセットに対して予測を行なった結果を示したのが図2です。
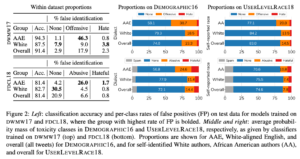
図2
図2の左側はDWMW17とFDCL18の2つのデータセットで学習を行なった結果で、全クラスに渡るAccuracyと各クラスのFalse Positiveの値が示されています。False Positiveは「そのクラスであると予測したが実際はそうではなかった=間違って判定した」ということを示しています。
AAE話者が攻撃的な投稿をしていることやヘイトの投稿をしていることに対するFlase Positiveの値が非常に高く出ており、内容に関係なく方言によってバイアスを持つモデルが学習されてしまったことがわかります。
また図2の中央と右側は方言ごとの各クラスの予測確率の平均値を示しています。上側がDWMW17、下側がFDCL18で学習したモデルの結果です。
モデルの平均的な出力が方言によって大きく変化していることが見て取れます。
以上からデータセットのバイアスはモデルにもそのまま伝わっていくことがわかります。やはり意図しないバイアスを避けるためにはデータセット作成時点から工夫が必要そうです。そこで本論文では以下のアノテーション手法の提案を行っています。
方言と人種のメタデータを与えた上でのアノテーション
アノテーターにとって社会的・文化的背景が伝わっていないことが上記のようなバイアスに繋がっていると考えられます。そこで論文中では事前に各話者がどういった人物であるかのメタデータを与えた上でアノテーションを行うという実験を行っています。
また、この実験では以下の3つの条件で実験を行なっており、
- control:メタデータを何も伝えない
- dialect:方言を伝える
- race:人種を伝える
それぞれ以下の2クラスを判断しています。
- アノテーターにとって攻撃的な内容である
- 全員に対して攻撃的な内容である
結果は図3の通りで方言や人種の情報を伝えることで、AAEのTweetが「誰にでも攻撃的な内容である」とラベル付けされる傾向が大きく減少しました(上)。また人種の情報を伝えることで、AAEのTweetが「アノテーターにとって攻撃的な内容である」とラベル付けされる傾向が大きく減少しました(下)。
結果AAE話者に対するラベル付けは内容とは無関係なものが多かったということが考えられ、また社会的・文化的背景が理解できるような簡単なメタデータを与えるだけで、モデルの意図しないバイアスを避けることが可能であるということが示唆されています。
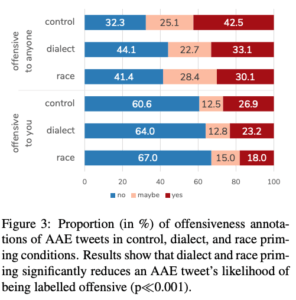
図3 アノテーターにメタデータを与えた場合の結果
- yes: 1
- maybe: 0.5
- no: 0
各ラベルを上記の数値に変換し、平均を計算したところ以下のような結果になりました。
全員に対して攻撃的な内容である
- 何も伝えない場合: 0.55
- 方言を伝えた場合: 0.44
- 人種を伝えた場合: 0.44
アノテーターに対して攻撃的な内容である
- 何も伝えない場合: 0.33
- 人種を伝えた場合: 0.25
このことからも事前に方言や人種の情報を伝えることで、データセットのバイアスが生じるリスクを大きく減少させることが可能であると考えられます。
まとめ
本論文から主に、
- いくつかのヘイトスピーチ検出データセットはAAEに対して内容に関係なく攻撃的であるとラベル付けされている。
- そのためモデルはデータセットに潜むAAEに対してのバイアスをそのまま学習してしまう。
- 方言や人種の情報をアノテーターに伝えることで、そういったバイアスが生じるリスクを避けられる。
といったことがわかりました。
所感
機械学習技術を活用していく上で意図しない差別的なバイアスが生じることは決して少なくありません。
論文中ではそのような問題に対してアノテーターに社会的な文脈を伝えることで回避するよう対策しました。
これからの機械学習導入にはこういったバイアスの存在をいかに事前に検知して改善を行えるか、といった部分により大きな注目が集まるフェーズに来ているように感じます。
The Risk of Racial Bias in Hate Speech Detection
written by Maarten Sap, Dallas Card, Saadia Gabriel, Yejin Choi, Noah A. Smith
(Submitted on July 2019)Accepted to ACL2019





この記事に関するカテゴリー






