多言語の単語ベクトルの上手な再配置手法。もう「girls」を「猫」とは訳さない!
3つの要点
✔️学習された単語分散表現を更新し、言語ごとの性質を揃えることが可能
✔️英語と日本語のような”性質が離れた言語間”で効果的な変換を行える
✔️応用範囲は広く、モデルを変えずに”多言語を扱うタスクの性能”が向上できる可能性
単語分散表現はwikipediaなどの大規模なコーパス(テキストや発話を集めた大規模なデータベース化言語資料)を用いて事前に学習し、各単語がどのような文脈で出現しやすいかという情報をベクトルとして学習します。
例えば、「少女」という単語は「娘」や「妹」といった単語と似た文脈で使用され、「少年」という単語は「息子」や「兄」といった単語と似た文脈で用いられるといった情報です。
どの単語がどの単語と似た文脈で使われるかという構造は、言語が異なってもある程度同じであると考えることができます。つまり英語においても、”girl”という単語は”daughter”や”sister”と似た文脈を持ち、”boy”は”son”や”brother”といった単語と似た文脈を持つと考えられます。こうした単語同士の関係性が言語間で完全に一致している時、「”daughter”→”娘”」「”brother”→”兄”」といった部分的な単語の変換ルールを学習することで、学習データにはない「”girls”→”少女たち”」という変換も実現することができるはずです。
このように、学習済みの単語分散表現などを用いて多言語間の単語の変換ルールを学習するタスクをCross-lingual word embeddings(多言語間での単語埋め込み学習)と呼びます。
このタスクを数式で表すと、以下のようになります。英語から日本語への変換を考えたときに、英語の単語ベクトルをx、対応する日本語の単語のベクトルをzとします。ここで、行列Wを用いて変換されたxが正解のzと近くなるようにWを学習します。
![]()
このタスクが完璧に解けた場合、多言語において似た意味を持つ単語を統一的に取り扱えるようになり、翻訳などの性能向上に大きく寄与すると期待できます。
“girls”が”猫”に変換されてしまう問題
しかし、現実的な単語分散表現の学習では、言語ごとに文法が異なったり、学習のためのデータが偏っていたりという理由から、言語間で似た意味を持つ単語同士が似た文脈で出現しているとは言えません。
実際に従来手法による学習では、文法や語源が非常に似ている英語とスペイン語間では81.4%の精度で単語の変換ができる一方で、文法や語源が大きく離れている英語と日本語間の変換ではわずか1.7%の精度となっています。そのため、いかにして変換ルールを賢く学習するかがこのタスクを解く上で重要になります。
下図1の左側は自然言語処理で広く用いられているFastTextという手法を用いて日本語と英語の単語分散表現をWikipediaから学習し、それぞれ”少女”と”girl”に類似した単語を図示したものです。英語では”girl”の周辺に”woman”などの意味的に似た単語が配置されているのに対し、日本語では”猫”という明らかに異質な単語が配置されてしまっています。
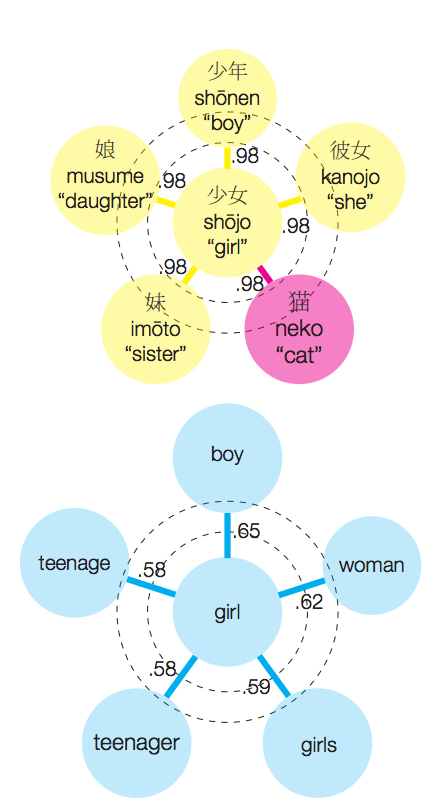
図1.日本語の”猫”が他類義語と同程度の類似度を誇る
単語間の数値は単語同士の類似度(0~1.0)を表しており、英語と比べて日本語では単語間の類似度が非常に高いことがわかります。このため、「”girl”→”少女”」という変換ルールを用いて、「”girls”→”?”」の変換しようとした時に、”girl”と非常によく似たベクトルを持つ”猫”(「”girls”→”猫”」)を変換候補としてあげてしまうという問題があります。
二つの条件を満たすように単語分散表現を再配置する
英語と日本語の単語翻訳におけるミスの原因は、文法などが大きく異なるために言語間での単語分散表現の性質(文章内における単語表現ベクトル同士の分散)が揃っていないことにあり、これが変換ルールの学習失敗の原因となっていると言えます。
そこで本論文では各言語の単語ベクトルの長さが同じになるような制約を設けることで、言語間の単語分散表現の性質を揃える方法を提案しています。既存手法では”girl”、”boy”、”少女”、”少年”のそれぞれの単語ベクトルの長さがバラバラな状態で学習されていましたが、これを全て同じに揃えることで単語変換の学習が簡単になります。
「単語ベクトルの長さを同じにする」ということは、具体的には以下の式を満たすように単語ベクトルを更新することを意味します。英語から日本語への変換の場合、x、z、Wxはそれぞれ「英語の単語ベクトル」「対応する日本語の単語ベクトル」「行列Wによって変換された英語の単語ベクトル」を表しています。これらのベクトルの長さが全て揃うように更新することで、行列Wの学習が容易になります。
![]()
これに加え、以下のように英語に含まれるすべての単語ベクトルの平均(x-bar)の長さと、日本語に含まれる全ての単語ベクトルの平均(z-bar)の長さも揃えることで、言語同士のベクトルの性質を揃えています。
![]()
この制約を満たすような単語分散表現を一度に計算することは難しいため、本論文で学習済みの単語ベクトルを少しずつ動かしていく(Iterative Normalization)手法を新しく導入しています。この方法では、語彙に含まれる単語のベクトルを一つずつ取り出し、制約を満たすようにベクトルを更新します。更新作業を何度か繰り返すことで、制約を満たした理想的な単語分散表現を獲得することができます。
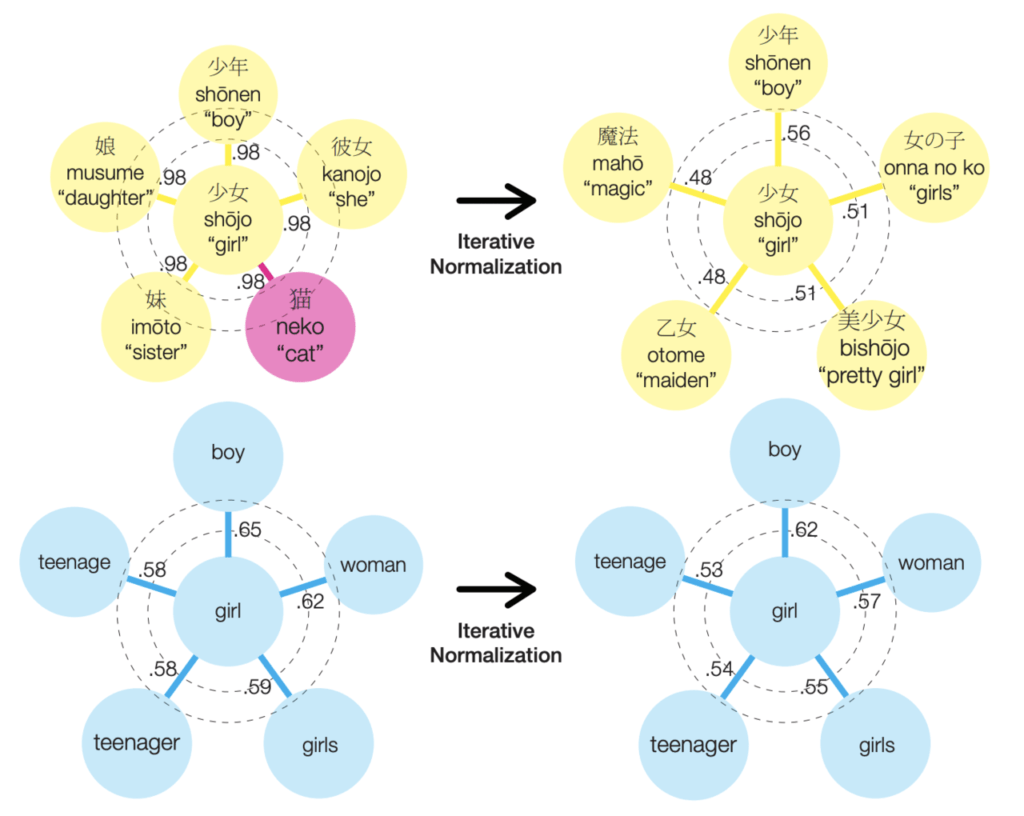
上図の右側はこの更新を適用した後の単語分散表現を図示しており、上が日本語、下が英語による対応を表しています。日本語では、「少女」と「猫」の類似度が高くなってしまっていますが、iterative normalizationを行う事で、日本語の”少女”に対する周囲の単語の類似度が英語と同程度まで下がったことがわかります。すなわち、単語ベクトルが密集していた問題が解決していることがわかります。
一方で、もともと単語の類似度が適度に離れていた英語では、更新によってその性質が崩れていないことが見て取れます。このことから、多言語間でのベクトルの性質が整えられたと言えます。さらに、この更新により”少女”に類似した単語が「より意味的に”少女”に近いもの」に変わったことも、変換ルールを学習しやすいという観点から重要と言えます。
評価
再配置された単語分散表現を用いて、英語から各言語への単語の変換ルールを学習し、精度の評価を行いました(下表)。
各言語のWikipediaを用いて単語分散表現を学習したのちに、5000単語の訓練データによって英語から別の言語の単語への変換を学習します。
変換を学習する際に、分散表現の再配置を行わないもの(None)・単純な再配置を行なったもの(C+L)・提案手法による再配置(IN=Iterative Normalization)の数値を比較することで、提案手法の有効性が確認できます。

再配置を行なっていない状態でも精度が高いドイツ語やスペイン語への変換精度を落とすことなく、提案手法によって日本語や中国語の変換性能を大きく向上させていることがわかります。特に日本語の上がり幅は大きく、文法が大きく異なる言語間で提案手法が有効であること主張されています。
英語からスペイン語などへの変換性能に比べると英語から日本語への変換性能はまだまだ低く、さらなる技術の発展が必要とされています。一方で、既存手法ではほとんど解けていなかった英語から日本語への単語変換タスクが、ある程度解けるようになったという点は、大きな一歩と言えるでしょう。
まとめ
本研究では学習済みの単語分散表現を更新することで、多言語間の単語翻訳の性能向上を実現しています。特に日本語と英語といった言語の性質が大きく異なる言語間において、その改善幅が大きいことが分かりました。
本論文は単語変換タスクに特化した単語分散表現の更新手法が提案されており、更新された単語分散表現が機械翻訳などのタスクの性能を向上させるか、という評価は行なっていません。そのため、別タスクへの応用については現状では「やってみなければわからない」状態と言えます。
しかし、学習済みの単語分散表現を再更新するだけの手法のため、現在利用している機械翻訳などのモデルを大きく変える必要なく利用できる点は非常に魅力的です。
すでに、大規模なコーパスで学習した単語分散表現が手元にあり、”翻訳などに用いるモデルも大きく変更したくないが性能を向上させたい“といった場合に利用できるという点で、自然言語処理の性能発展に貢献すると言えます。機械翻訳や英文校正などのニューラルネットワークの性能に悩んだときに、ぜひ試してみたい手法です。
論文:Are Girls Neko or Shōjo? Cross-Lingual Alignment of Non-Isomorphic Embeddings with Iterative Normalization
written by Mozhi Zhang, Keyulu Xu, Ken-ichi Kawarabayashi, Stefanie Jegelka, Jordan Boyd-Graber
Submitted on 4 Jun 2019
Status : ACL 2019




この記事に関するカテゴリー






