画像生成でセグメンテーション?GANを使った教師なしセグメンテーション手法が登場!
3 つの要点
✔️ 教師なしセグメンテーション手法「ReDO」の提案
✔️ 画像生成の仕組みでセグメンテーションタスクを解く新たな試み
✔️ 教師あり学習と比べても、様々な実データセットで良いパフォーマンスを発揮
はじめに
近年、様々な分野で画像認識技術が活用されています。これは深層学習技術の発展によって、画像認識の精度が大幅に向上したためです。画像認識技術には三段階のステップに分けられます。
1つ目は、画像に何が写っているか判断する「物体認識」です。「物体認識」では画像に何が写っているか判断するだけで、その物体の位置までは判断しません。
2つ目は、画像に写っている物体の名前と位置を判断する「物体検出」です。
3つ目は、画像のピクセル単位で物体認識を行う「セマンティックセグメンテーション」です。人間はピクセル単位で物体を認識しており、「セマンティックセグメンテーション」は私たちと同様の画像認識を機械に行わせる試みと言えます。その応用範囲は自動運転や医療など、様々な分野に渡ります。

図1. 画像セグメンテーションの例
これら3つを総称して画像認識技術と言い、「物体認識」「物体検出」「セマンティックセグメンテーション」の順に教師データを作成するのに必要なコストは高くなります。特に、ピクセル単位でラベル付けを行う必要のある「セマンティックセグメンテーション」は他の2つに比べて、教師データの作成に非常に高いコストが掛かります。
そこで本研究では、「セマンティックセグメンテーション」を教師データを用いずに、「GAN」の仕組みを用いて行っています。
学習過程
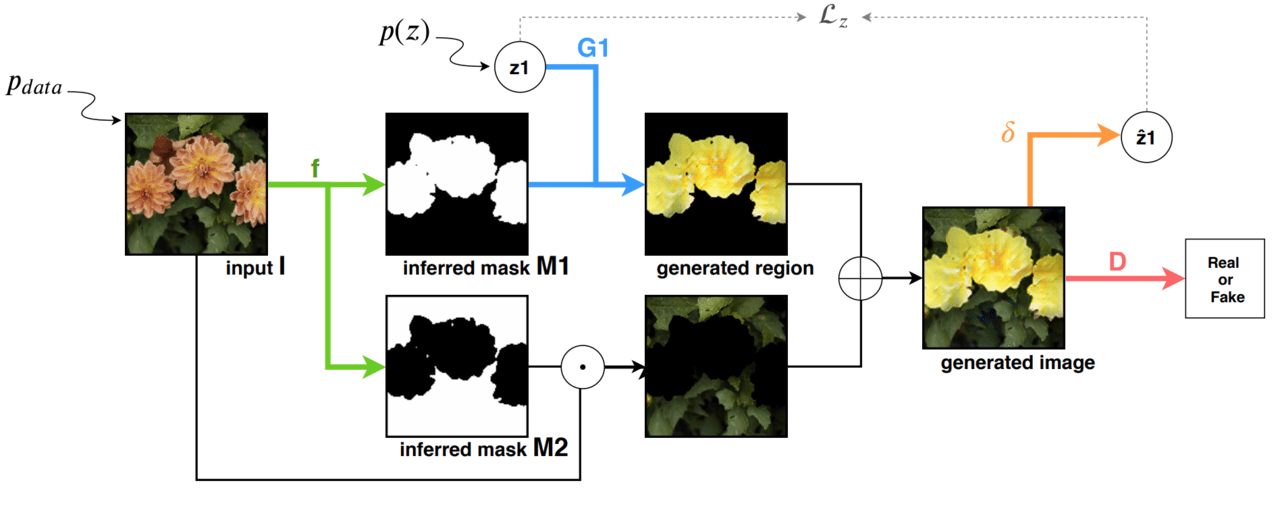
図2.ReDOの学習手順
では、「GAN」の技術を用いた教師なし「セマンティックセグメンテーション」の過程を見ていきましょう。本研究で提案されたセグメンテーション手法を「ReDO」と呼びます。これは物体(Object)を再度描く(ReDrawing)というプロセスが由来です。「ReDO」の大まかな手順は以下の通りです。
続きを読むには
(3065文字画像6枚)AI-SCHOLARに
登録いただく必要があります。



この記事に関するカテゴリー






