Facebook発、タイポに強い単語分散表現
論文:Misspelling Oblivious Word Embeddings
チャットボットによる応答生成やブログ投稿のテキスト分析を行う際、ユーザーによる自然言語の入力が処理の対象となります。十分に校正された新聞記事や小説といったデータとは異なり、ユーザーがウェブ上で入力した自然言語には多くのタイポグラフィ(タイポ)が含まれます。
例えば「hello」と入力したつもりが「hallo」と間違えて入力していた、という経験は誰しもが持っているかと思います。
自然言語処理においてこうした入力ミスはテキスト分析の性能などに大きく影響を与え、この分析の失敗がビジネスの失敗にも繋がるかもしれません。とりわけSNSのような雑多な交流の場となる媒体では日々多くのタイポが入力として送信され、こうしたタイポをいかにうまく取り扱うかが課題となっています。
本記事ではこの問題に対応するために、大手SNSであるFacebookの研究チームが発表した解決方法について紹介します。
タイポが自然言語処理に与える影響
一般的なニューラルネットワークを用いた自然言語処理では一つの単語に対して一つのIDを与え、そのIDの並びを用いて意味の解析やテキストの分類を行います。具体的に「hello world」という系列が入力された時、このままでは機械で処理することが難しいため、「hello:15」「world:413」のように各単語を対応するIDへと置き換えることで「15, 413」といった系列として表現し直します。
この時、ユーザーの入力がタイポを含む「hallo worjd」というものであったとします。「hallo」も「worjd」も学習データには含まれない単語のため対応するIDが存在せず、学習器はうまくこの入力を取扱えなくなってしまいます。
現在の自然言語処理では「hello」「world」といった単語に対して、事前に対応するベクトル(単語分散表現)を学習することで効率的なテキスト分析を実現しています。しかし実応用時にタイポが入力されてしまうと、せっかく学習した単語分散表現を利用することができず、その効果を発揮することができません。そこで本研究では、単語分散表現を学習する際にタイポを考慮する方法について提案しています。
検索ワードの修正ログを用いたデータセット作成
タイポに強い単語分散表現を作成する上で、「どの単語をどのようにタイポしたか」というデータは非常に重要です。たとえば「world」という単語を入力する時、一般的なキーボード配列であれば「worjd」や「woeld」のような打ち間違えが考えられます。
「どの文字の並びにおいてどのようにタイポすることが多いか」といった情報を収集し学習することで、実際の入力においてもタイポされた単語から元の単語を予測できるようになると期待できます。
そこで、本研究では「正しい単語」と「タイポした単語」のペアを大量に作ることで、タイポと正しい単語の関係性を考慮しながら単語分散表現を学習できるようなデータセットを構築しています。
データセットはFacebookの検索欄に入力されたログを元に作成されています。ユーザーが検索欄にタイポを入力し、その後正しいスペルで入力し直した際のログを収集することで、どの単語をどのように間違えたかという情報を集めています。
さらに単純に集めたデータを用いて正しい単語とタイポした単語のペアを作るのではなく、タイポをどのように直したかという情報を用いて人工的にタイポを大量に作成しています。これにより学習データが増えるため、効率的なタイポの学習ができるデータセットとなっています。
なお作成されたデータセットは以下で配布されているため、各自でデータを作らずとも同様の実験を行うことができます。
データセット:https://bitbucket.org/bedizel/moe
ミススペルと正しい単語が近くなるように学習
単語分散表現の学習には、word2vecという手法が広く用いられています。本研究はその中でも特にSkipGramと呼ばれる方法を用いています。SkipGramでは、ある単語から周囲の単語を当てられるように学習を行うことで、文脈情報を単語分散表現に詰め込んでゆきます。
具体的に「… how in the world she was to …」という文章が与えられた時、「world」という単語分散表現を用いて周囲の「how」「in」「the」「she」「was」「to」といった各単語を予測できるように学習を行います(図上側)。これによって、同じような文脈を持つ単語は同じような単語分散表現を学習することができます。
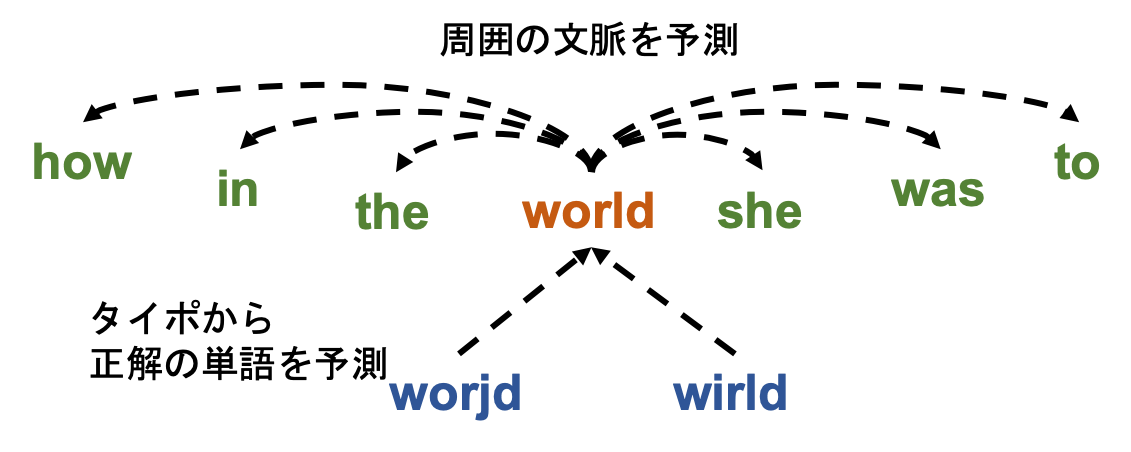
以上は一般的な単語分散表現の学習ですが、本研究はこれに加え「タイポした単語」から「正しい単語」を予測できるようにする学習も同時に行います。上の例では「world」という単語から周囲の単語を予測していましたが、これに加えて「worjd」のようなタイポされた単語を用いて「world」を予測できるように学習を行います。
これによって、「worjd」という単語もまた「world」と同様の文脈で使われる単語であることを学習します(図下側)。結果としてタイポした単語と正しい単語のベクトルが近いものとなるため、たとえタイポされた単語が入力されても、タイポ前の正しい単語の単語分散表現を利用することができます。
単語類似度による頑健性の評価
提案手法によって学習された単語分散表現がどの程度タイポに頑健であるのかを調べるために、単語類似度を予測するタスクを用いて評価を行います。このタスクでは、「ある2単語がどれだけ似た意味を持っているか」というスコアについて、学習された単語分散表現同士の類似度がどの程度人間のつけたスコアと一致しているかを計測します。
下図における縦軸の数値(spearman rank)が高いほど学習された単語分散表現は「人間と同じレベルで単語の類似度を捉えられている」といえます。実験では二つの単語類似度評価データセット(WS353、RW)に人工的なタイポを混ぜ込み、タイポの強さを係数rで調整した四つのデータセットを作成しています。
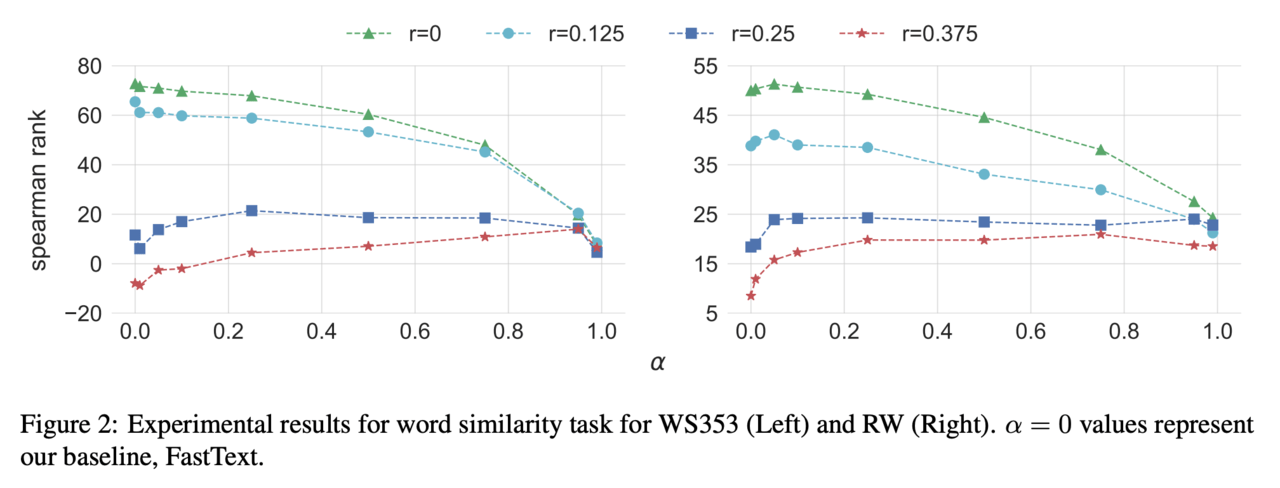
rが大きいほどタイポが多く含まれており、データセットは「ぐちゃぐちゃな」状態になっています。図では緑・水色・青・赤の順にタイポが多いデータセットとなります。
また、横軸のαが大きいほど「タイポと正しい単語の関係」を重視した学習を行なった単語分散表現となっています。α=1.0ではSkipGramによる文脈の学習をせず、α=0.0ではタイポの学習を行いません。すなわち、α=0.0が従来の単語分散表現の学習方法となっており、結果よりr=0.25以上のタイポを含むデータセットにおいては、提案手法を用いた手法(0.0<α)が従来手法(α=0.0)よりも高性能であることがわかります。
まとめると、より多くのタイポを含むデータセットにおいて「タイポから正しい単語を復元する学習」を行なった手法が性能の向上に寄与しています。
なおr=0.25という係数によって生成されたデータセットでは、単語を構成する文字の25%までをタイポとして置き換えることができるという制約のもとでタイポが生成されています。実際にそこまでタイポを多く含む状況はなかなかないかもしれませんが、スラングなどを多く含むSNSのデータを用いた自然言語処理では効果が発揮されるかもしれません。
まとめ
今後AI技術が生活に浸透していく中で、打ち間違えやいい間違えを考慮した自然言語処理の重要性が高まっていきます。既存の自然言語処理の技術は、新聞記事のようなタイポやミススペル、スラングの少ない綺麗なテキストデータを前提としている場合が多くあります。
一方で実応用においては「汚い」データを取り扱う必要があり、最新の技術を取り入れることが難しいことも多々あります。本研究を踏まえた単語分散表現の学習を行なうことで、こうした問題が軽減されるのではないでしょうか。
レシピ
Axrossレシピにword2vecでベクトル化実践レシピが公開されています。




この記事に関するカテゴリー






