超軽量なCNN音声認識モデル!Google開発「ContextNet」を解説!
3つの要点
✔️ Googleが軽量なCNN音声認識モデルを提案
✔️ squeeze-and-excitationモジュールによってグローバルコンテキストを考慮
✔️ Progressive Downsamplingによってコンピューティングコストを削減
ContextNet: Improving Convolutional Neural Networks for Automatic Speech Recognition with Global Context
written by Wei Han, Zhengdong Zhang, Yu Zhang, Jiahui Yu, Chung-Cheng Chiu, James Qin, Anmol Gulati, Ruoming Pang, Yonghui Wu
(Submitted on 7 May 2020 (v1), last revised 16 May 2020 (this version, v3))
Comments: Submitted to Interspeech 2020
Subjects: Audio and Speech Processing (eess.AS); Computation and Language (cs.CL); Machine Learning (cs.LG); Sound (cs.SD)
code:

本記事で使用している画像は論文中のもの、またはそれを参考に作成したものを使用しております。
はじめに
RNNやTransformerではなく,CNNベースでE2E(End-to-End)音声認識モデルを構築することへの期待が高まっています.RNNやTransformerベースの手法は,音声認識において精度が高くなりやすいものの,パラメータの数が膨大になりやすく,非常にコンピューティングコストが高くなってしまいます.
一方,CNNベースであれば,RNNやTransformerに比べてパラメータ効率が高く,小規模な企業でも高い品質の音声認識モデルを実用しやすいかもしれません.
しかし,CNNモデルは近い特徴量を畳み込んで考慮することは得意ですが,遠く離れたグローバルコンテキストを考慮することが苦手で,今までのSOTAのCNNモデルであるQuartzNetでもRNN/Transformerモデルには精度が及びませんでした.
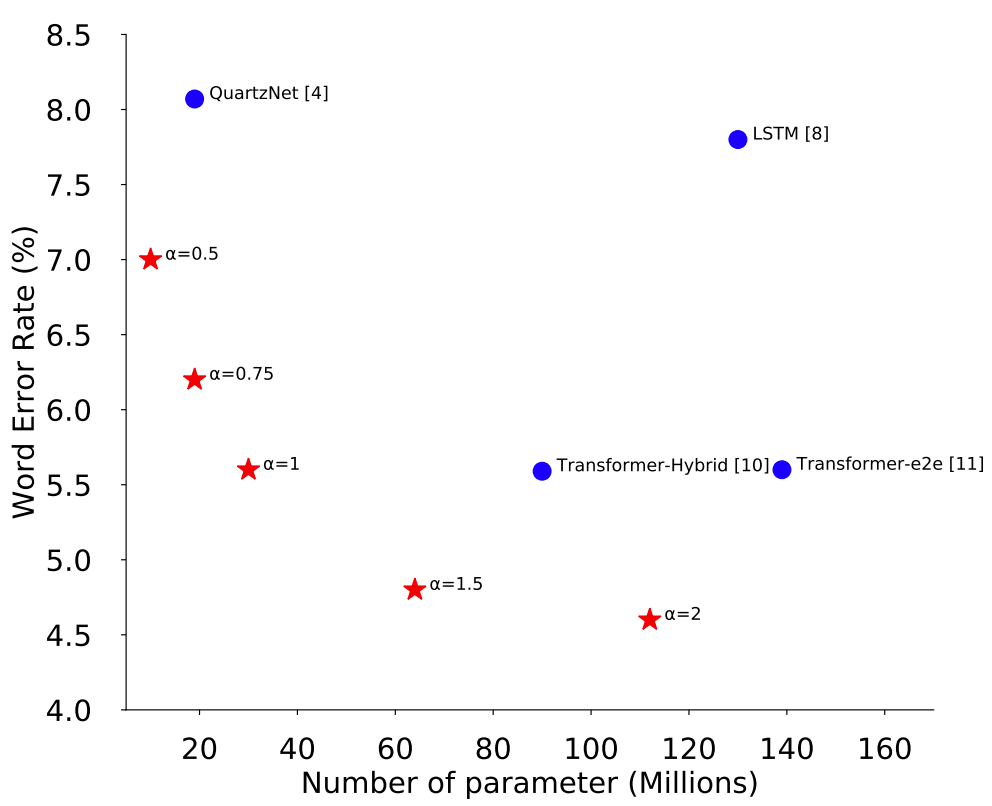
そんな中,今回ご紹介するContextNetは,squeeze-and excitationによるグローバルコンテキストの考慮とprogressive downsamplingによるパラメータの削減を同時に実現し,CNNベースモデルにも関わらず,TransformerやLSTMベースのモデルを超える精度を達成しました.下図は,モデルサイズと精度(WER)のトレードオフを示しています.ContextNetがAuartzNetやRNN/Transformerベースのモデルよりも最も良いトレードオフ性能となっているとわかります.
それでは,そんなContextNetのモデルの詳細をみていきましょう.
モデル
End-to-end Network: CNN-RNN-Transducer
ContextNetのネットワークは,RNN-Transducerフレームワーク (https://arxiv.org/abs/1811.06621) に基づいており,入力音声に対するAudio Encoder, 入力ラベルに対するLabel Encoder, 両者を組み合わせるJoint Networkの3つから構成されます.本手法では,このうちAudio EncoderをCNNベースに変えたところが,新しい提案ポイントです.
Encoder Design
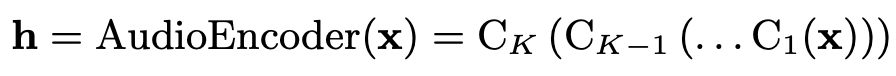
それぞれのCk(·)は畳み込みブロックのことで,バッチノーマライゼーションと活性化関数が後にある数層の畳み込み層から成ります.またsqueeze-and-excitationとskip connectionも有しています.
C(·)の詳細な説明に入る前に,まずはC(·)の重要なモジュールから見ていきましょう.
Squeeze-and-excitation
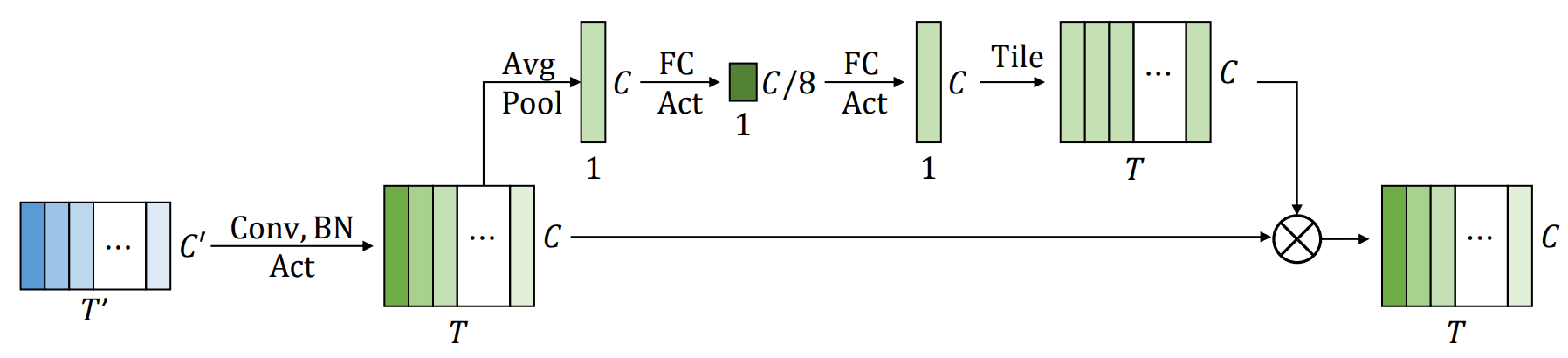
上図で示されているように,Squeeze-and-excitation関数であるSE(·)は入力xに対してglobal average poolingを行い,それをglobal channelwise weight θ(x)に変換し,この重みに基づいてそれぞれのフレームの要素ごとの積(element-wise multiplication)を取ります.このような考え方を1Dの場合に適応し,以下の式を得ます.
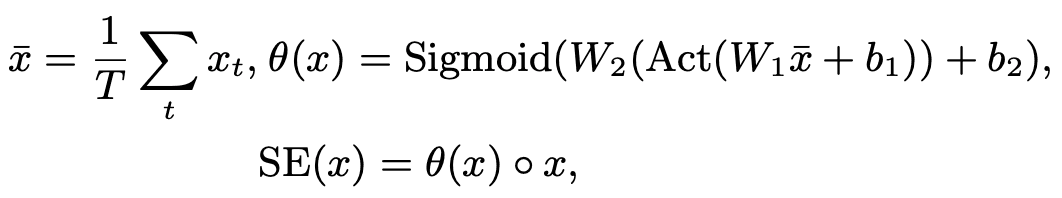
ここでの処理をtensorflowで行うと以下のようなコードになります.とてもシンプルなので,ぜひご自身のモデルにsqueeze-and-excitationモジュールを導入してみて下さい.
x_orig = x
x = tf.reduce_sum(x, axis=1) / tf.expand_dims(tf.cast(x_len, tf.float32), 1) # Average Pooling
for i in rage(len(num_units)):
x = tf.nn.swish(fc_layers[i][x]))
x = tf.expand_dims(tf.nn.sigmoid(x), 1)
return x * x_orig
Depthwise separable convolution
性能を犠牲にしないで,より高いパラメータ効率を実現するために,単なる畳み込みではなく,depthwise separable convolutionを用いています.conv(·)は,depthwise separable convolutionを表しています.
ちなみに,depthwise separable convolutionとは,軽量モデルで知られるMobileNetでも用いられたテクニックで,Depthwise(空間方向)の後に,Pointwise(チャネル方向)に畳み込むことによって,より少ないパラメータによって同じ内容の処理を実現することができます.
Tensorflowによるdepthwise convolutionのコードは以下のようになります.
conv = tf.keras.layers.Separable1D(filters, kernel_size, strides, padding)
Swish Activation Function
Act(·)は活性化関数を表します.活性化関数には,ReLUとSwishの2つを試し,Swishの方が性能が向上することが実験から分かりました.Swish関数の数式とグラフは以下のようになります.Swish関数の導関数は,ReLU関数が0と1の間で離散的な値となってしまうのに対し,ReLU関数よりも滑らかに変化するため,学習結果も滑らかになりやすいです. 


Tensorflowでは以下のように実装できます.
X = tf.nn.swish(x)
Convolution block
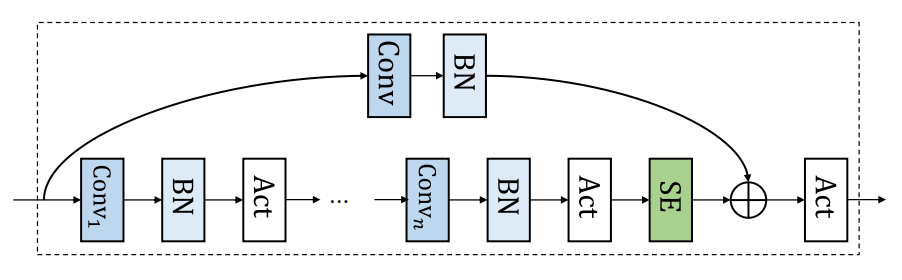
以上で紹介した個別のモジュールを組み合わせると,上図のようになります.また,以下は最初に紹介した数式中のC(·)を表現した数式になります.


ここでf^mはスタックされたm層のf(·)であり,P(·)はresidualに対するpointwise projectionを表現しています.この部分の処理をコードにすると以下のようになります.
for conv_layer in conv_layers:
x = conv_layer(x)
x = se_layer(x)
x = x + residual(x_orig)
x = tf.nn.swish(x)
Progressive downsampling
コンピューティングコストをさらに低下させるため,progressive downsamplingを採用しています.具体的には,畳み込み層のストライドを徐々に増やしながら実験し,パラメータ数と性能のトレードオフを観察しています.結果としては,ContextNetでは8xでdownsamplingしたときがもっともよいトレードオフ結果となりました.
Configuration details of ContextNet
ContextNetは23個の畳み込みブロック(C0, …, C22)から成り,C0, C22以外の全てが5層の畳み込み層を有しています.下図が,アーキテクチャの詳細のサマリーになります.
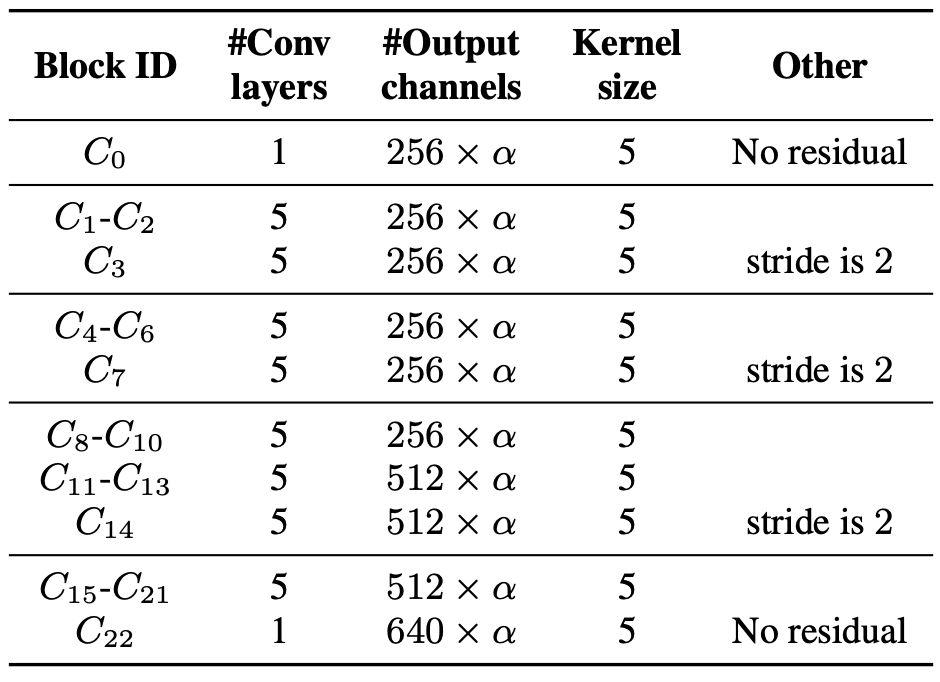
ここで,グローバルパラメータのαはモデルのスケーリングを制御しており,α>1に増やすと畳み込みチャネル数を増やすことになります.
実験結果
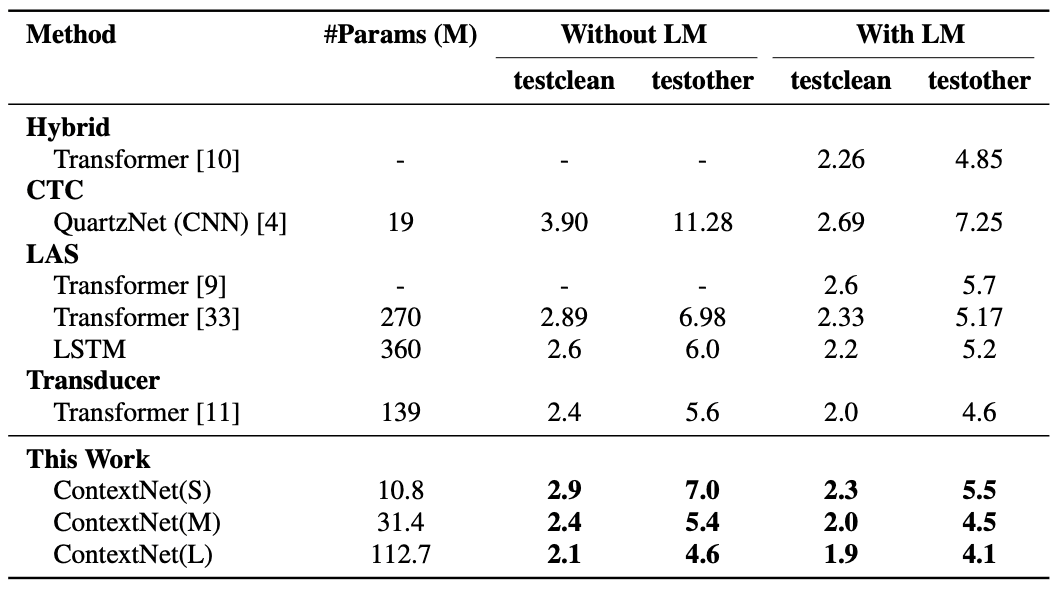
上図は,LibrispeechデータセットでテストしたときのWERの値になります.上図からも.言語モデル(LM)があるときとないときの両方の場合においても,ContextNetが他のモデルよりも優れていることが分かります.
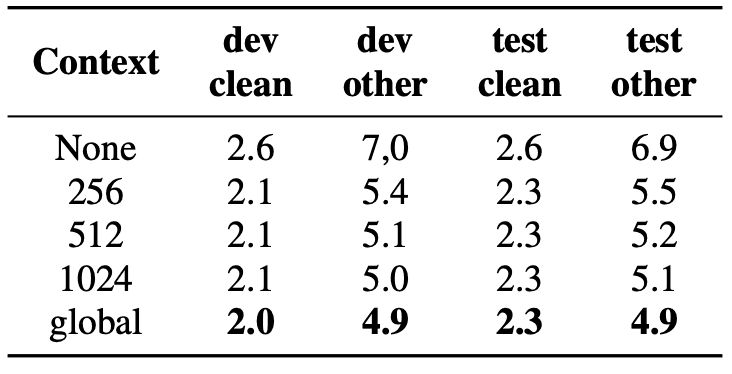
また,下図ではsqueeze-and-excitationモジュールがグローバルコンテキストを考慮することによって,性能を大幅に向上させていることがわかります.
最後に
本記事では,CNNベースのEnd-to-End音声認識モデル「ContextNet」をご紹介させて頂きました.昨今よく用いられるTransformerですが,コンピューティングコストが非常に高く,個人や小規模企業ではなかなか手が出づらいところもあるかと思います.一方,CNNベースであれば,本論文が示すように,比較的少ないコストで実用化できるため,squeeze-and-excitationやprogressive downsamplingなどのテクニックを活用してみてはいかがでしょうか.



この記事に関するカテゴリー






