【wav2vec 2.0】Facebook AIが新しい音声認識フレームワークを公開!自己教師あり学習により正解ラベルなしで高精度を達成!?
3つの要点
✔️ Facebook AIが新しい音声認識フレームワーク「wav2vec 2.0」を公開
✔️ 自己教師あり学習により,少量の文字起こし音声と正解ラベルなし音声で学習
✔️ ラベルなしデータ・ラベル付きデータのみの場合の両方で最高精度を達成
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
written by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
(Submitted on 20 Jun 2020 (v1), last revised 22 Oct 2020 (this version, v3))
Comments: Accepted at NeurIPS 2020
Subjects: Computation and Language (cs.CL); Machine Learning (cs.LG); Sound (cs.SD); Audio and Speech Processing (eess.AS)


はじめに
Facebook AIが新しい音声認識フレームワーク「wav2vec 2.0」を公開しました。コードも公開されており、誰でも今すぐに利用できる状態になっています。本論文の凄いところは、自己教師あり学習を存分に音声認識に活用している点で、少量の文字起こしされた音声データと、正解ラベルなしの音声データだけで高精度を達成しています。今までの手法では、実用に耐えうる精度を得るには何千時間もの文字起こし音声が必要でしたが、実際問題として、多くの状況で文字起こし音声を得ることは非常に難しいです。実際、7000以上の言語ではそうした正解データを得ることは難しいとされています。
そこで、自己教師あり学習の出番です。自己教師あり学習とは、正解ラベルなしデータから表現を学習し、正解ラベルデータによるモデルをファインチューニングする手法です。本論文では、複数層のCNNで音声をエンコードし、潜在表現をマスクしています。潜在表現はTransformerネットワークに伝えられ、文脈化された表現を構築します。そして、モデルは、正しい特徴と誤った特徴を区別する対照学習を通じて訓練されます。
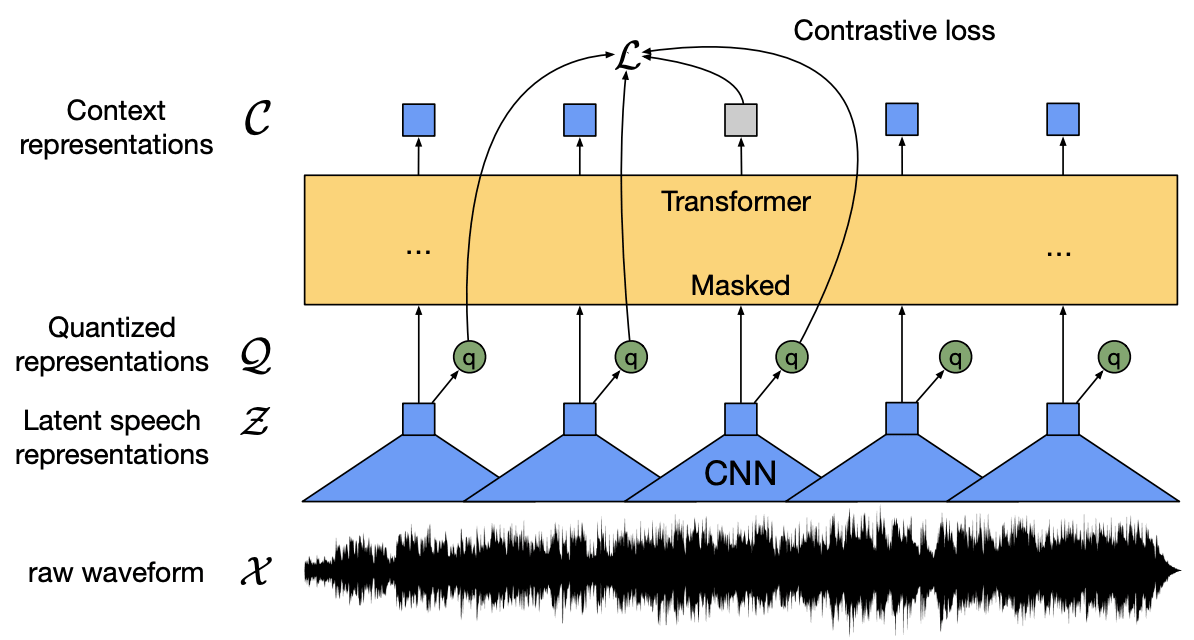
訓練部分では、gumbel softmaxを通じて音声ユニットを分離し、これは対照学習において潜在表現を表しています。この対照学習は、ターゲットをクオンタイズ(量子化)していない場合よりも効果的であると分かりました。ラベルなし音声で事前訓練を行った後、Connectionist Temporal Classification (CTC) lossによってラベルデータでモデルをファインチューニングし、音声認識タスクに利用しています。
続きを読むには
(3743文字画像15枚)AI-SCHOLARに
登録いただく必要があります。



この記事に関するカテゴリー






