
モデル軽量化のテクニック!軽量かつ高性能な音声感情認識モデルLightSER-NET!
3つの要点
✔️ 音声感情認識モデルLightSER-NETがICASSP2022に採択
✔️ 3種類の並列CNNを用いたシンプルな構造で軽量化に成功
✔️ 軽量化と同時に,SOTA同様の性能を達成
Light-SERNet: A lightweight fully convolutional neural network for speech emotion recognition
written by Arya Aftab, Alireza Morsali, Shahrokh Ghaemmaghami, Benoit Champagne
(Submitted on 7 Oct 2021)
Comments: ICASSP 2022
Subjects: Audio and Speech Processing (eess.AS); Signal Processing (eess.SP)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
音声信号から直接,喜びや悲しみ,驚きなどの人間の感情を検知する技術は,ヒューマンコンピューターインタラクションにおいて重要な役割を果たしています.既存の研究では,多くの深層学習モデルと同様に,多量の計算コストを必要とするために,実際にシステムに組み込み,アプリケーションとして使用することが難しくなっています.
そこで,本研究では,異なるフィルターサイズを持つ3種類の並列CNNを用いることで,CNN構造のみで高い性能とモデルの軽量化を同時に達成しています.
3つの並列CNNは,周波数,時系列,周波数・時系列の3種類の特徴抽出をそれぞれ別に担当しており,音声認識にとって効果的な高次元の特徴抽出を実現しています.最終的に,得られた特徴マップを用いて分類することで,モデル軽量化とSOTAと並ぶ性能を同時に達成しました.
アーキテクチャ

全体としては,入力パイプライン, 特徴抽出ブロック (Body), 分類ブロック(Head)の3つのメイン部分から成ります.さらに,Body部分は並列2D畳み込み(Body Part I)と局所特徴学習ブロック(Local Feature Learning Blocks: LFLBs)から構成されています.
入力パイプライン
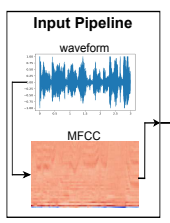
-1から1の間で音声信号を標準化した後,MFCCを計算します.ここでは,一般的な処理と同様に,ハミング窓関数や高速フーリエ変換,メルフィルタバンク,逆コサイン変換等の処理を行い,MFCCを導出しています.
Body Part I
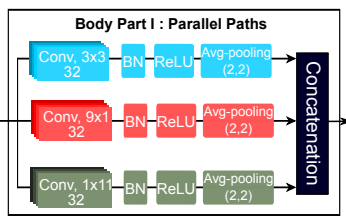
このステップでは,並列CNNをMFCCに当てはめることで,時系列・周波数方向の特徴量をバランスよく抽出します.また,畳み込みネットワークの受容野を広くすることで分類性能の向上に繋がることが知られていますが,本研究では受容野を広くするために下記の工夫を行っています.
- ネットワーク層を増やす
- プーリングやより大きいストライドなどのサブサンプリングブロックを用いる
- dilated convolutionを用いる
- depth-wise convolutionを用いる
さらに,複数次元の信号に対しては,それぞれの次元は別々に受容野を計算することができます.なので,本研究では,9×1, 1×11, 3×3のカーネルを用いて周波数,時系列,周波数-時系列方向にそれぞれ特徴量を抽出します.
この同じ受容野サイズを持つただ一つのパスを持つというテクニックを用いることによって,パラメータ数を減らし,計算コストも削減することができます.下図は,並列CNNによる受容野の広さを示しています.
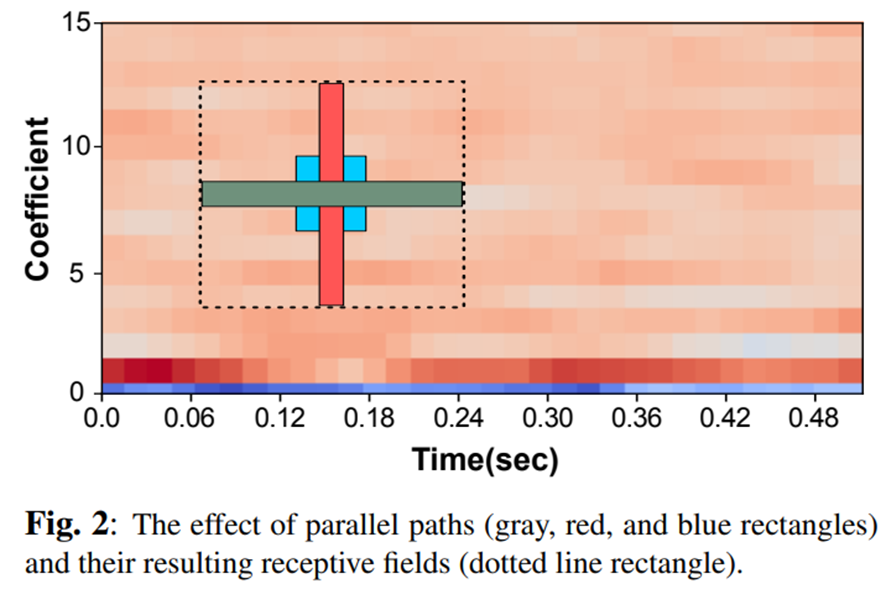
Body Part II
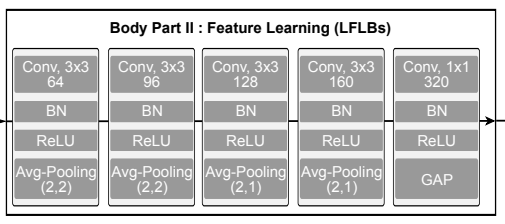
Body Part IIはいくつかの局所的特徴学習ブロックから成り,Body Part Iで抽出した特徴量に対して適応します.これは,畳み込み層,バッチノーマライゼーション層,ReLU,マックスプーリング層から構成されています.
また,最後のブロックではグローバルアベレージプーリング(GAP)が用いられ,アーキテクチャを変えずに異なる長さのデータセットでの訓練を可能にしています.
Head
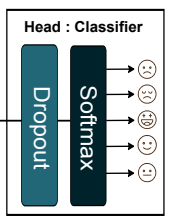
Body partでは,非線形入力を線形空間へと写像しているため,全結合層では分類するだけで済みます.そこで,通常のドロップアウト層とソフトマックス関数により計算コストを抑えています.
実験
データセット
音声感情認識でよく用いられるデータには,IEMOCAPとEMO-DBがあり,それらを用いて実験しています.IEMOCAPは音声と映像のマルチモーダルデータセットであり,それぞれに対して,happiness, sadness, angry, naturalの4つのラベルが振られています.
また,EMO-DBは10人の専門の声優によるドイツ語のデータセットであり,angry, natural, sadness, fear, disgust, happiness, boredomの7つのラベルが振られています.
実験結果
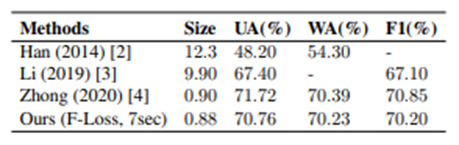
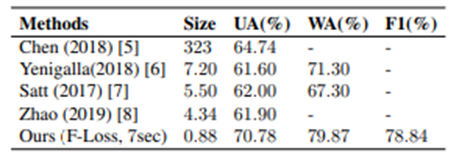
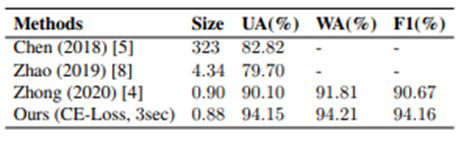
データセットに含まれるクラス間のデータの偏りに対応するために,unweighted accuracy (UA), weighted accuracy (WA), F1-score (F1)の3つの指標で評価を行っています.
他の音声感情認識モデルとの性能比較は下図になります.モデルサイズの軽量化に成功しているだけでなく,性能もSOTAに匹敵するレベルで実現できていることが分かります.
結論
本研究では,異なるフィルターサイズを持つ3種類の並列CNNを用いることで,効果的かつ軽量に特徴量を抽出することに成功しました.
実際にアプリケーションに組み込む際などには,モデルの軽量さやレスポンスの速さが重要であり,今回の内容は,実用に近い部分で音声認識に取り組む方の参考になるのではないでしょうか.





この記事に関するカテゴリー






