
著者が直面した実社会の問題であるDeep Imbalanced Regression(DIR)という新しいタスクを提案
3つの要点
✔️ Deep Imbalanced Regression(略称:DIR)という新しいタスクを提案
✔️ LDSとFDSという新しい手法を提案
✔️ 5つの新しいDIRデータセットを構築
Delving into Deep Imbalanced Regression
written by Yuzhe Yang, Kaiwen Zha, Ying-Cong Chen, Hao Wang, Dina Katabi
(Submitted on 18 Feb 2021 (v1), last revised 13 May 2021 (this version, v2))
Comments: Accepted by ICML 2021.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、またはそれを参考に作成したものを使用しております。
はじめに
実世界のデータを見てみると、特定のターゲットの観測数が著しく少なく、不均衡な分布を示すことがよくあります。そういったアンバランスなデータでの学習も数多く研究されてきました。またそういった場合の研究のほとんどが、明確な境界があるカテゴリを想定していることが多いです。すなわち、アンバランスなデータ/ロングテール分布を扱う既存の手法の大半は、ターゲットが異なるクラスの離散値である分類問題のみを対象としていることが多いです。しかし実際のタスクではターゲットが連続的なものも多く存在しています。
著者らは、そういったターゲットが連続値でアンバランスなデータ/ロングテール分布における学習手法を提案し、コンピュータビジョン・自然言語処理・医療問題などの不均衡回帰タスクをカバーする5つの新しいベンチマークDIRデータセットを構築しました。 主な貢献を紹介します。
- Deep Imbalanced Regression(略称:DIR)という新しいタスクを提案している。DIRタスクは、連続的なターゲットを持つ不均衡なデータから、ターゲット範囲全体に一般化できる学習を行うと定義しています。
- 連続的な対象を持つ不均衡なデータからの学習問題を解決するために、ラベル分布平滑化(Label distribution smoothing:LDS)と特徴分布平滑化(Feature distribution smoothing:FDS)という新しい不均衡回帰の手法を提案
- 不均衡なデータに関する今後の研究を促進するためのコンピュータビジョン、自然言語処理、医療をカバーする5つの新しいDIRデータセットを構築
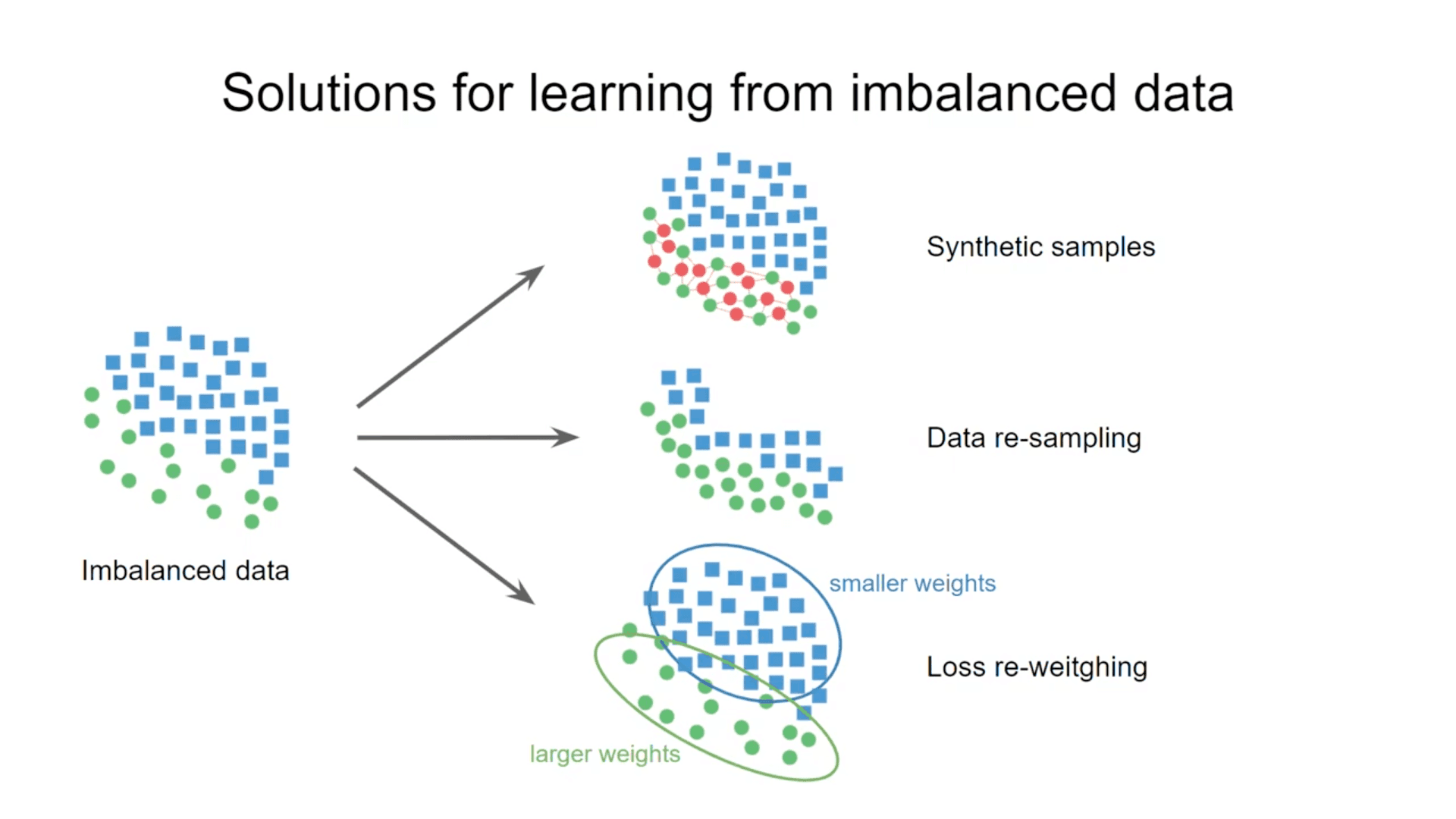
データの不均衡は、現実の世界ではいたるところに存在し、各カテゴリーにおいて理想的な一様分布ではなく、むしろロングテールを持つ歪んだ分布をしており、あるターゲット値では観測数が著しく少なくなっていたりします。 これはモデルに大きな課題をもたらしており、この不均等問題が現実世界での機械学習の活用を邪魔しているともいます。
これまでの学習テクニックは、データベース手法とモデルベース手法に大別されます。 データに基づく解決策は、少数派のカテゴリーをオーバーサンプリングすることや多数派をアンダーサンプリングするなどがあります。モデルベース手法には、損失関数の再重み付けや伝達学習・メタ学習など、関連する特定の学習技術を利用するものがあります。しかし、アンバランスなデータからの学習のための既存手法は、主に上記ですでに述べたように離散的なターゲット値を取り扱います。
例えば、顔からの年齢推定はいかがでしょうか。年齢は連続した値であり、ターゲット範囲内で非常に偏った値になることが予想されます。それこそ、赤ちゃんや年配のほうが学習データは少なくなると予想できます。
Deep Imbalanced Regression: DIR
Deep Imbalanced Regression(DIR)は、連続したターゲット値を持つ不均衡なデータから学習し、特定の領域における潜在的なデータの欠落に対処し、最終的なモデルがターゲット値の全範囲に一般化できるようにすることを目的としています。
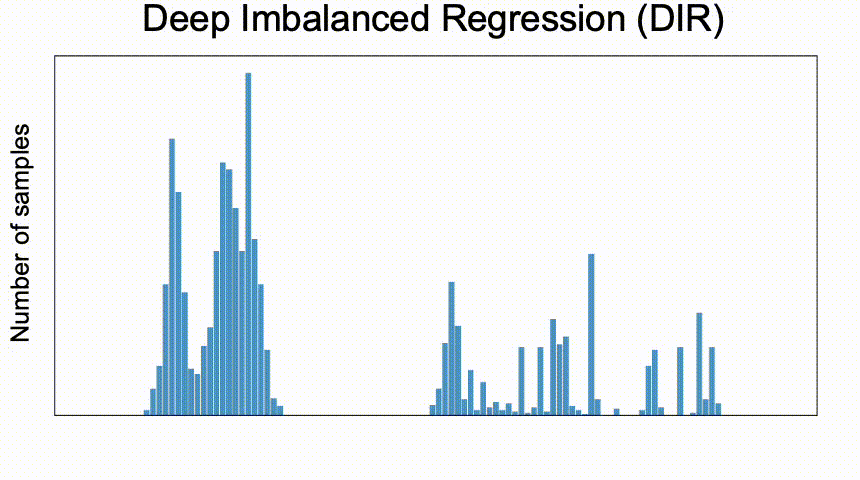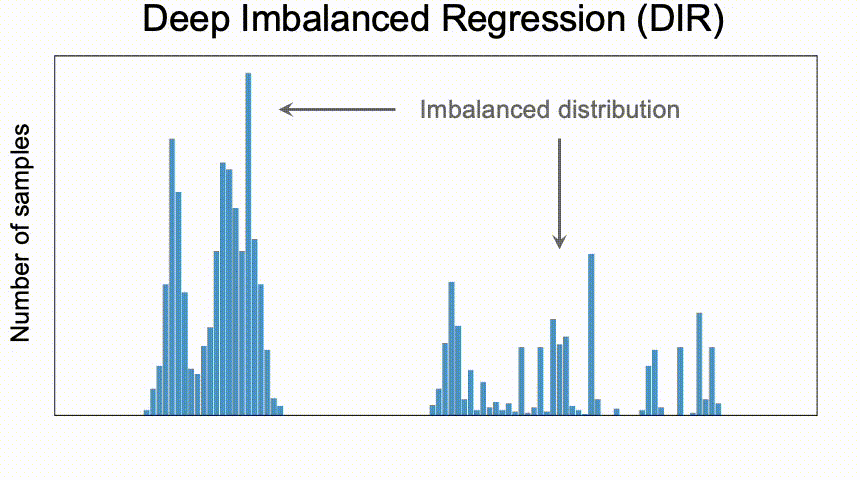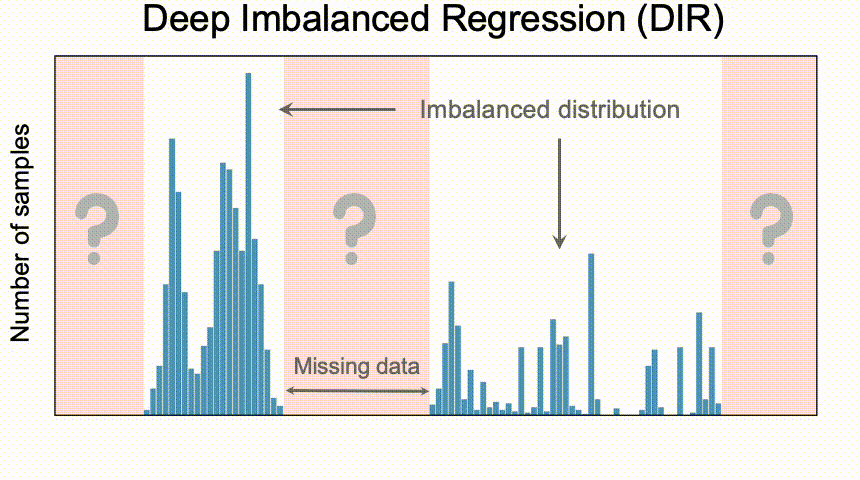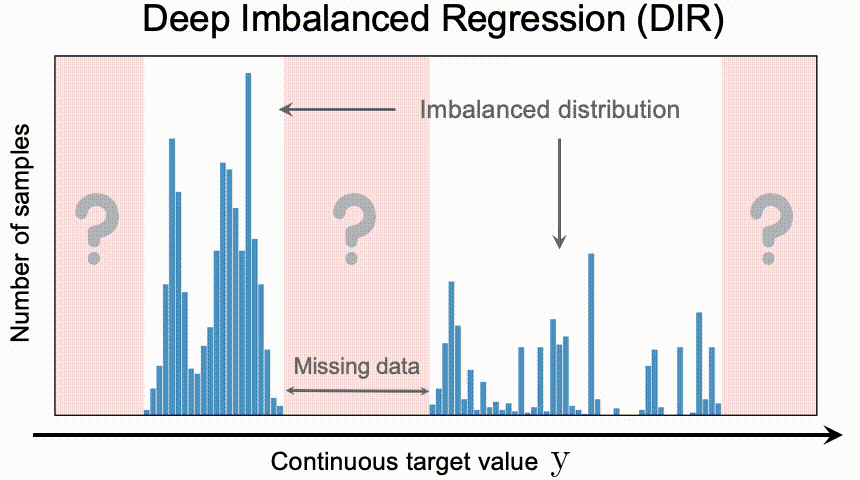
難しさと課題
ここで重要なのは、アンバランスな分類問題に比べて、DIRは次のような全く新しい課題を抱えているということです。
- 連続したターゲット値が与えられた場合、クラス間のハードな境界は存在しない。そのため、リサンプリングや再重み付けなどの従来手法を直接適用できない。
- 連続的ラベルは、ターゲット同士の距離に意味を持っています。これらのターゲットは、どのデータがより近くにあり、どのデータがより遠くにあるかを直接教えてくれます。この意味のある距離は、この連続した区間のデータの不均衡の度合いをどのように理解すべきかについてのさらなる指針ともなります。
- 分類問題とは異なり、DIRでは対象となる値にデータが全くない場合もある。 そのため、目標値の外挿や補間の必要である。
以上の問題点をまとめると、DIRは従来の問題設定と比較して新たな困難と課題を抱えていることがわかります。では、DIRはどのように行えばよいのでしょうか。 次の2つのセクションでは、ラベル空間と特徴空間における近隣のターゲット間の類似性を利用してモデルを改善するためのそれぞれラベル分布平滑化(Label distribution smoothing:LDS)と特徴分布平滑化(Feature distribution smoothing:FDS)という2つのシンプルで効果的な方法を提案します。
提案手法
ラベル分布平滑化(Label distribution smoothing:LDS)
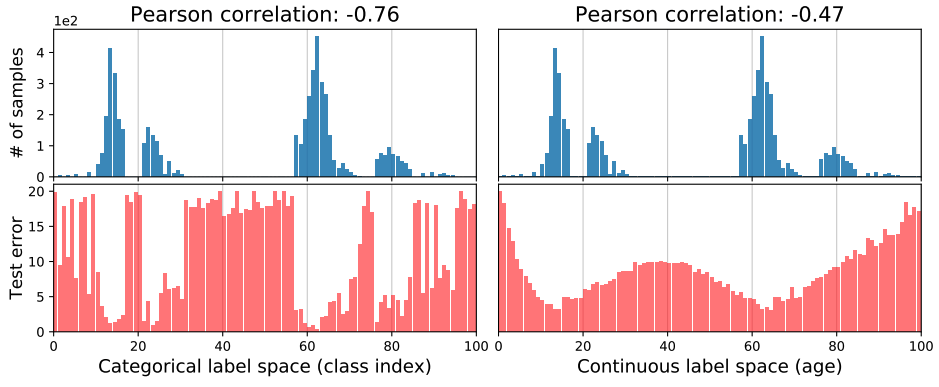
データの不均衡が存在する場合の分類問題と回帰問題の違いを示すために、シンプルな例を提示します。2つの異なるデータセット、CIFAR-10(100クラスの分類データセット)とIMDB-WIKI(人の外見から年齢を推定するための大規模な画像データセット)を使用しています。 この2つのデータセットは、本質的に全く異なるラベル空間です。CIFAR-100はカテゴリーラベル空間、つまりその値はクラスインデックスとなります。IMDB-WIKIは連続ラベル空間で、その値は年齢となります。 両データセットが同じ範囲のラベルを持つように、IMDB-WIKIの年齢範囲を0-99に制限し、さらに、データの不均衡をシミュレートするために、両データセットをサンプリングし、下図のようにラベルの密度分布が全く同じになるようにしました(青の棒グラフ)。本来は全く違うデータセットですが、ラベルの密度分布を合わせただけです。
次に、2つのデータセットでResNet-50モデルを学習し、テストエラー分布をプロットします(赤の棒グラフ)。図の左側より、誤差分布はラベル密度分布と相関していることがわかります。具体的には、クラスインデックスの関数としてのテスト誤差は、カテゴリーラベル空間において、ラベル密度分布と高い負のピアソン相関(-0.76)を示します。この現象は、サンプル数の多いクラスが少数のクラスよりもよく学習されることからも容易に予想されます。
しかし、興味深いことに図の右側に示すように、IMDB-WIKIでは、ラベル密度分布がCIFAR-100と同じであっても、連続ラベル空間では誤差の分布が大きく異なることがわかります。特に、誤差分布はより滑らかになり、ラベル密度分布(-0.47)とはあまり相関しなくなっています。この例が興味深いのは直接的にも間接的にもすべての不均衡学習法は、経験的なラベル密度分布の不均衡を補うことで動作するからだと思われます。これはクラスの不均衡には有効ですが、連続したラベルの場合、経験的な密度はニューラルネットワークが見た不均衡を正確に反映できないと言うことです。そのため、経験的なラベル密度に基づいてデータの不均衡を補正することは、連続的なラベル空間では不正確です。
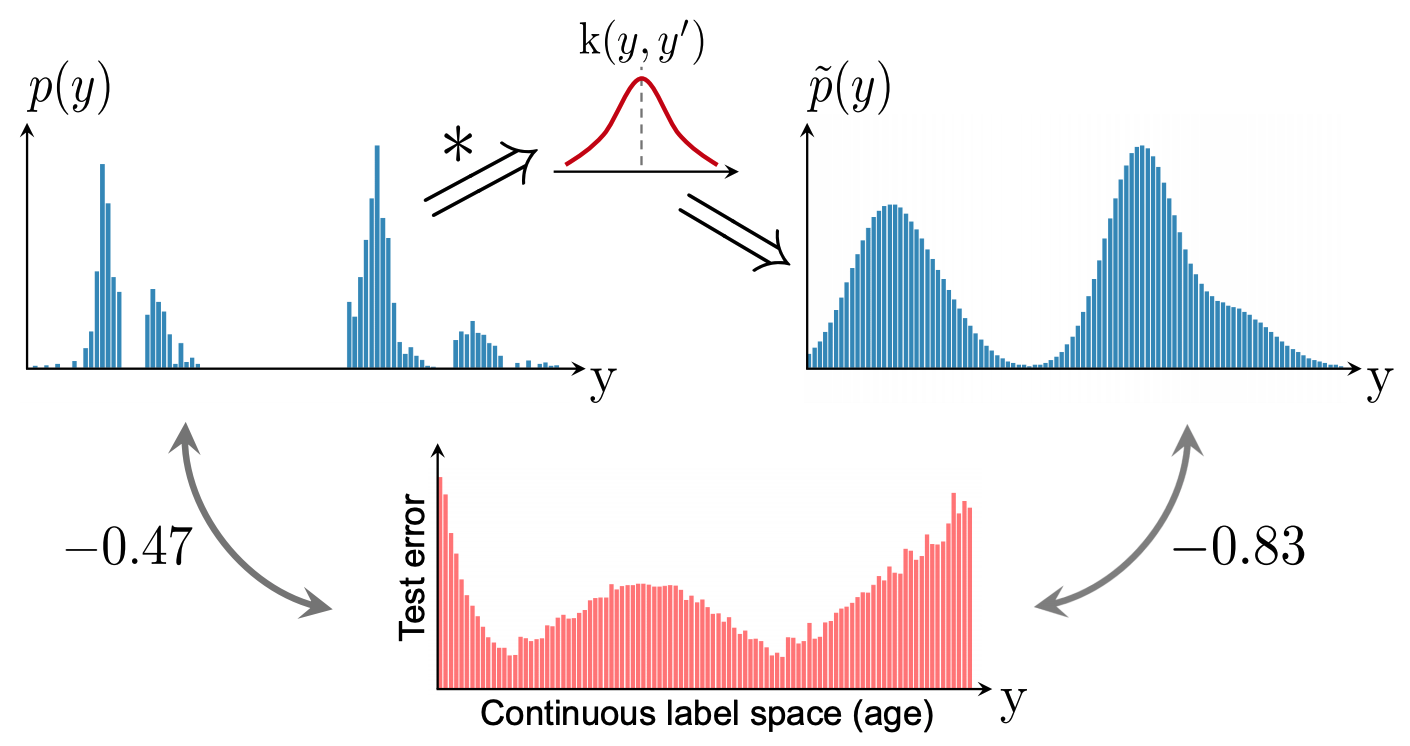
結果に基づいて連続的なラベルの場合に有効なラベル密度分布を推定するために、ラベル分布平滑化(Label distribution smoothing:LDS)を提案しています。この論文のアプローチは、統計的学習の分野におけるカーネル密度推定のアイデアを利用して、期待される密度を推定しています。具体的には、連続した経験的なラベル密度分布が与えられた場合、LDSは経験的な密度分布が畳み込まれた対称的なカーネル分布関数kを使用して、次のように求めます。
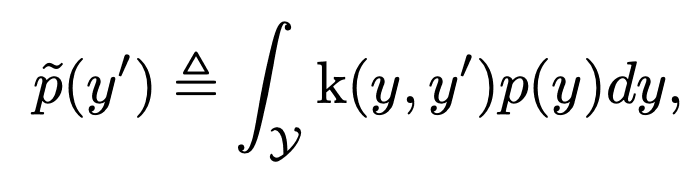
LDSによって算出された有効ラベル密度分布と誤差分布のピアソン相関係数が-0.83とよく相関していることが確認できます。 これは、LDSを用いることで、回帰問題に実際に影響を与える不均衡なラベル分布を作り出すことができると言うことです。
特徴分布平滑化(Feature distribution smoothing:FDS)
FDSの概要図を下記に示します。
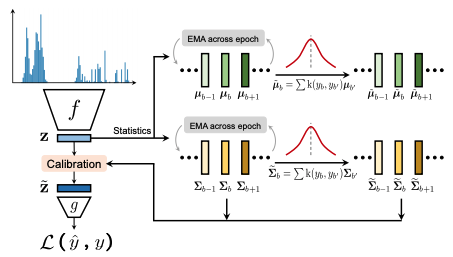
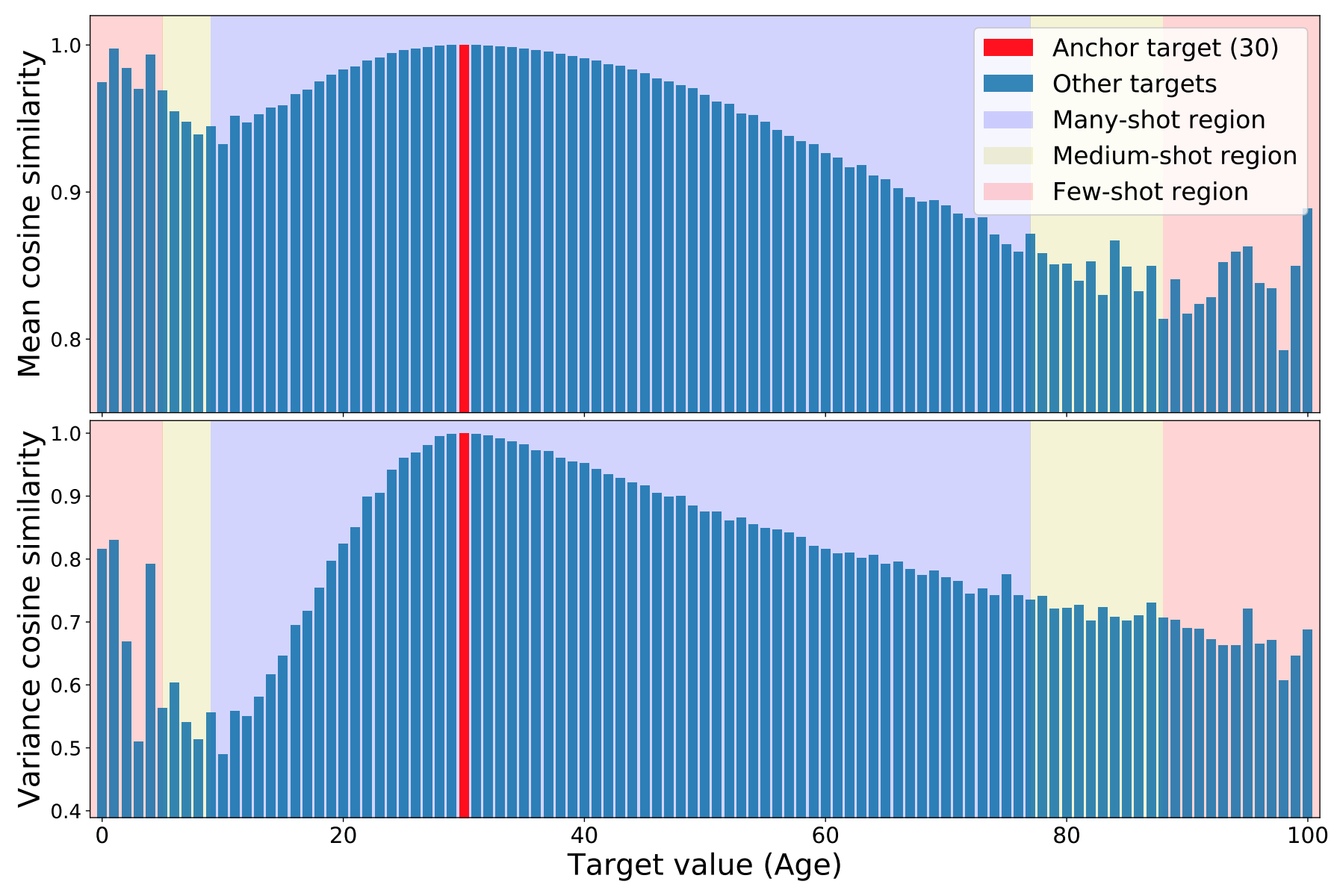
このFDSはターゲット空間での連続性は、それに対応する特徴空間での連続性を生むはずだという直観が動機となっています。つまり、モデルが正しく動作し、データがバランスを保っていれば、近くのターゲットに対応する特徴量の統計値が互いに近くなるはずだということです。データの不均衡がDIRの特徴量に与える影響を示していきます。IMDB-WIKIデータセットの画像で学習したモデルを用いて、見た目から人物の年齢を推測します。ここでは、各データに関する特徴の統計量(平均と分散)を計算し、これを{$µ_b,σ_b$}とします。特徴量の類似性を可視化するために、特定のデータを選択し、他のすべてのデータとの間の特徴量のコサイン類似度を計算します。
結果を下図に示します。30の場合は、データ密度の異なる領域を・紫・黄色・ピンクの色で示しています。図を見ると、30付近の特徴量の統計値は、非常に似ていることがわかります。具体的には、25歳から35歳までのすべての特徴平均と特徴分散のコサイン類似度は、30歳のときの値から数%以内に収まっています。このように、十分なデータがある場合や、連続したターゲットの場合、特徴の統計は似ているという直感を、この図は裏付けていると言えます。
興味深いことに、この図では、0歳から6歳までの年齢層(ピンク色)のように、データのサンプル数が非常に少ない領域の問題も示しています。この範囲の平均値と分散値は、30歳と予想外に高い類似性を示していることに注目してください。実際、30歳の特徴統計量が17歳よりも1歳に類似しているのは衝撃的です。この不当な類似性は、データの不均衡によるものです。
とにかく年齢を例で言えば、近い年齢同士は似ていて、遠い年齢同士は似ていないはずだ!だけど、実際はデータの偏りによっておかしなことが起きているということです。
FDS特徴空間の分布平滑化を行うもので、近傍のターゲット間で特徴統計量を移動させていきます。これは特に学習データに含まれる代表性の低いターゲット(中程度〜少数のグループなど)について、特徴量分布の偏った推定値を校正することを目的としています。FDSは、まず各統計量を推定することで実行され、一般性を損なわないように、z内の様々な特徴要素の関係も反映させるために、分散を共分散に置き換えます。
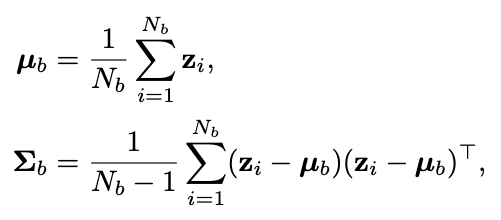
$N_b$はb番目のサンプル数。特徴量の統計値が与えられた場合、対称的なカーネルk($y_b$,$y_b'$)を再び採用して、対象となるデータ上の特徴量の平均と共分散の分布を平滑化します。これにより、統計値の平滑化バージョンが得られる。
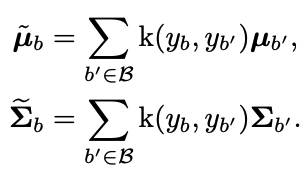
一般的な統計値と平滑化された統計値の両方を用いて、次に標準的なstandard whiteningとre-coloringの手順に従って、各入力サンプルの特徴表現をキャリブレーションします。
最終的な特徴マップの後に特徴キャリブレーション層を挿入することで、FDSをモデルに統合します。モデルを学習するために、各エポックにわたる実行統計量のモメンタム更新を採用し、これに対応して平滑化された統計量は、異なるエポック間では更新されるが、各学習エポック内では固定されます。FDSは、ラベルの不均衡を改善するための過去の研究と同様に、あらゆるモデルと統合することができます。実際論文では他の不均等問題を改善する手法に本手法を統合することで一貫して性能を向上させることができると実証しています。
ベンチマークであるDIRデータセット
データセットDIRでは、コンピュータビジョン、自然言語処理、ヘルスケアの5つのベンチマークを用意している。図はこれらのデータセットのラベル密度分布と、そのアンバランス度を示しています。(データの詳細は原著をご確認ください)
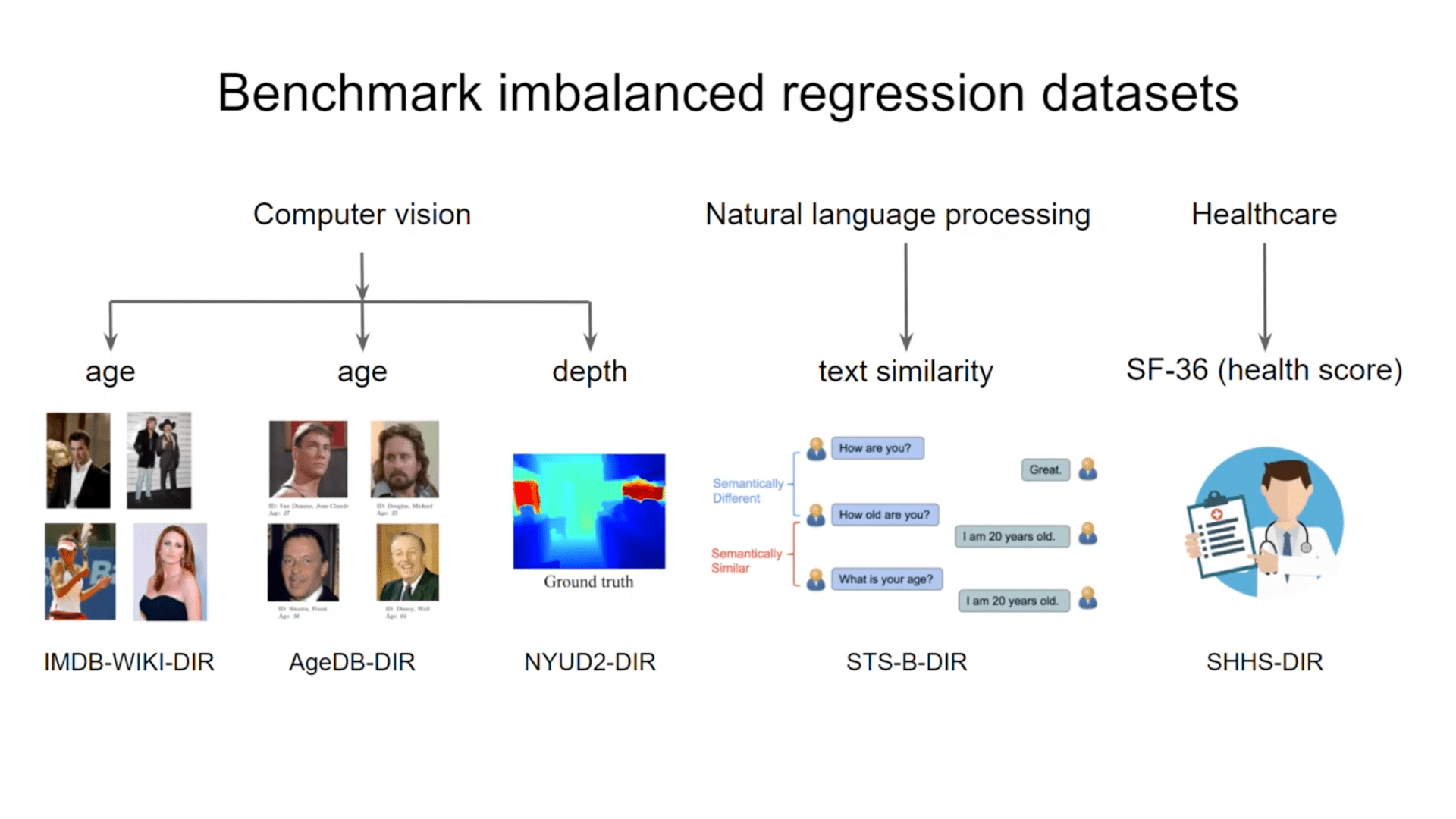

- IMDB-WIKI-DIR
523.0Kの顔画像とそれに対応する年齢を含むIMDB-WIKIデータセットからIMDB-WIKI-DIRを構築されています。 - AgeDB-DIR
AgeDB-DIRは、AgeDBデータセットから構築されています。 - STS-B-DIR
ニュースの見出し、動画や画像のキャプション、自然言語推論データから抽出した文のペアを集めたSemantic Textual Similarity Benchmarkから、STS-B-DIRを構築しています。 - NYUD2-DIR
NYUD2-DIRはNYU Depth Dataset V2より構築されいます。 - SHHS-DIR
SHHSデータセットは、2651人の被験者の終夜睡眠ポリグラフ(PSG)を含み、PSGの信号には、脳波、心電図、呼吸信号(空気の流れ、腹部、胸部)が含まれています。データセットには、各被験者の36項目のショートフォーム健康調査(SF-36)が含まれており、ここで一般的な健康状態のスコアが抽出されています。
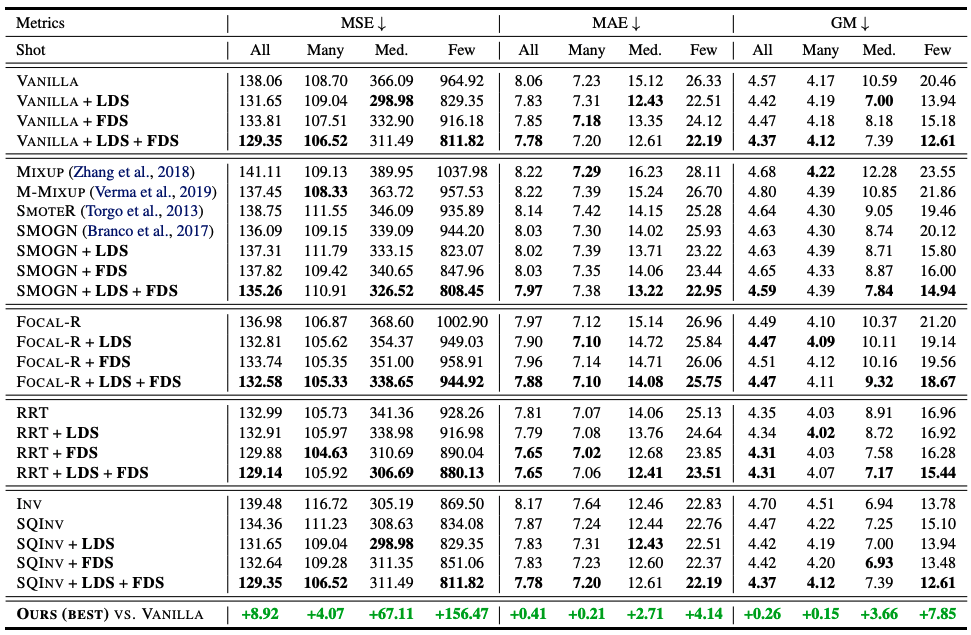
実験結果
ここではメイン結果として述べられているIMDB-WIKI-DIRの結果のみを示します。すべての結果の詳細は原著をご覧ください。以下に示すように、異なる手法との比較とそれぞれのLDS、FDS、およびLDSとFDSの組み合わせをベースライン手法に適用しています。 最後に、LDS+FDSのバニラモデルに対する性能向上について報告しています。 表に示すように、LDSとFDSは使用した学習方法の種類に関わらず非常に優れた性能を発揮し、数十%の改善が見られています。
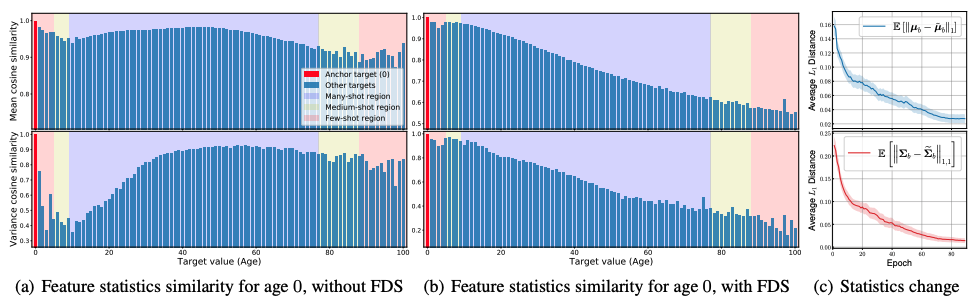
考察
FDSが機能する理由については、さらに詳しく分析しています。 1つ目は、FDSがネットワークの学習プロセスにどのような影響を与えるかについての分析です。 ベース年齢0の特徴統計量の類似性プロットを示しています。 このように、対象区間である0歳のサンプル数が少ないため、特徴量の統計値に大きな偏りが生じることがわかります。例えば0歳の統計値は、40歳から80歳までの区間とも類似していることになっています。
一方、FDSを加えた場合は、統計値がよりよくキャリブレーションされて、その周辺だけが高い類似性を持つようになり、ターゲット値が大きくなるにつれて類似性が減少していきます。さらに学習中の実行統計値と平滑化統計値の間の$L_1$距離を可視化すると興味深いことに、平均$L_1$距離は学習が進むにつれて減少し、0に収束しています。これは、平滑化を行わなくても、モデルがより正確な特徴量を生成するように学習し、最終的には推論プロセスにおいて、つまり平滑化モジュールを使用しなくても、良い結果が得られることを示しています。
まとめ
DIRを体系的に研究し、対応するシンプルで効果的な新しい手法LDSとFDSを提案して、連続的な目標を持つ不均衡データの学習問題を解決し、今後の不均衡データの回帰研究を促進するための5つの新しいベンチマークを確立しています。この論文では、非常に直感的な問題分析と説明がなされています。
実際今回の論文の著者は別件で、ヘルスケアAI関連のプロジェクトを運用しているそうです。著者は連続値でラベル分布は非常にまばらで偏っている経験から、今回の問題を定義し、最終的にLDSとFDSを提案しています。ベースラインモデルと比較して性能を大幅に向上できることが分かり、実社会タスクにおける有効性と実用性が検証され、この手法が学術的なデータセットだけに留まらないことが期待されています。
しかし今後の課題として対称的なカーネルを使用しているため、ハイパーパラメータ化の問題があり、最適なパラメータはタスクごとに異なる可能性があります。特定のタスクのラベリング空間に基づいて適切な値を決定する必要があります。ただ今回の論文はこの課題に対する問題定義として大きな出発点になると思います。



この記事に関するカテゴリー





