分類タスクではクロスエントロピーを用いるべきか?
3つの要点
✔️ 分類タスクにおけるクロスエントロピー損失と平均二乗誤差を比較
✔️ 自然言語処理、音声認識、コンピュータビジョン等の様々なタスクで検証
✔️ 二乗誤差を利用したモデルの方が全体として優れた性能を発揮
Evaluation of Neural Architectures Trained with Square Loss vs Cross-Entropy in Classification Tasks
written by Like Hui, Mikhail Belkin
(Submitted on 12 Jun 2020 (v1), last revised 4 Nov 2020 (this version, v3))
Comments: Accepted to ICLR2021.
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
code:
はじめに
分類タスクにおける損失関数として一般的に用いられるのは、平均二乗誤差(Mean Squared Error:MSE)ではなくクロスエントロピー損失(Cross-entropy loss)です。
これは果たして正しいことなのでしょうか?
つまり、分類タスクではMSEよりクロスエントロピー損失の方が有効なのでしょうか?
本記事で紹介する論文では、自然言語処理・音声認識・コンピュータビジョンなどの様々なタスクにおいて、クロスエントロピーと二乗誤差の比較を行いました。その結果として、二乗誤差を用いて学習されたモデルは、クロスエントロピーを利用したモデルと同等以上の性能を発揮したこと、初期化のランダム性に対して分散が小さいことなど、むしろ有利となる場合が多く存在することが示されました。
実験
データセット
クロスエントロピーと二乗誤差の比較には、自然言語処理(NLP)、音声認識(ASR)、コンピュータビジョン(CV)の三つの領域に渡るタスクが用いられました。それぞれ以下に示すデータセットにて実験が行われました。
NLP
- MRPC
- SST-2
- QNLI
- QQP
ASR
- TIMIT
- WSJ
- Librispeech
CV
- MNIST
- CIFAR-10
- ImageNet
アーキテクチャ
実験に用いられたアーキテクチャは以下の通りです。
NLP
ASR
CV
それぞれのタスクについて、データセットの統計量は以下の通りです。
NLP

ASR
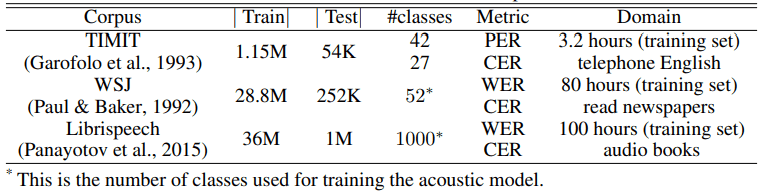
CV

実験プロトコル
クロスエントロピー損失による訓練時は、5エポック連続でvalidation性能が向上しなかった場合に学習が停止されます。二乗損失による訓練時は、以下の二つのプロトコルが用いられました。
- クロスエントロピー損失と同様、5エポック連続でvalidation性能が向上しなかった場合に学習が停止される
- クロスエントロピー損失の訓練時のエポック数と同じエポック数で学習を行う
後者は、クロスエントロピー損失と二乗損失とで計算リソースが同じになるように設計されており、クロスエントロピー損失にとって有利な設定となります。また、以下に示す実験結果では、各タスクについて異なる5回のランダムな初期化を用いて実験を行った場合の平均が表記されています。
実装の重要点
実装の詳細については元論文に譲りますが、特に重要な点については以下にて説明します。
・ソフトマックス層の削除
クロスエントロピー損失の場合、最後にソフトマックス層が存在します。
二乗損失利用時には、この層は削除されます。
・損失の再スケーリング
出力クラス数が多い(実験では42以上)データセットでは、学習の高速化のため、損失の再スケーリング(loss rescaling)を行っています。
$x \in R^d$を特徴ベクトル、$y \in R^C$(Cは出力クラス数)はラベルを表すone-hotベクトルとし、モデルは$f:R^d→R^C$として表します。
このとき、通常の(クラス数が少ない場合の)二乗損失は以下のように表されます。
$l=\frac{1}{C}((f_c(x)-1)^2+\sum^C_{i=1,i\neq c}f_i(x)^2$
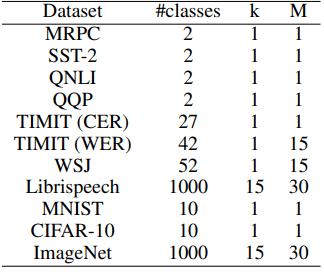
一方、クラス数が大きい場合の損失は、二つのパラメータ$(k,M)$を用いて以下の式のように定義されます。
$l=\frac{1}{C}(k*(f_c(x)-M)^2+\sum^C_{i=1,i\neq c}f_i(x)^2$
$k=1,M=1$の場合は通常時と同じとなります。実験でのパラメータと各データセットのクラス数は以下の表の通りです。
NLPにおける実験結果
自然言語処理タスクにおける、クロスエントロピー損失と二乗損失の比較は以下の通りです。上図は精度(accuracy)を、下図はF1スコアを示しています。
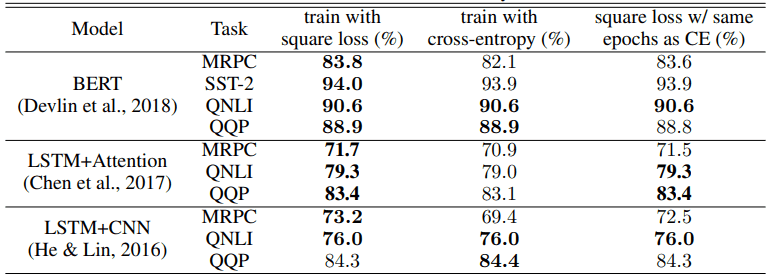
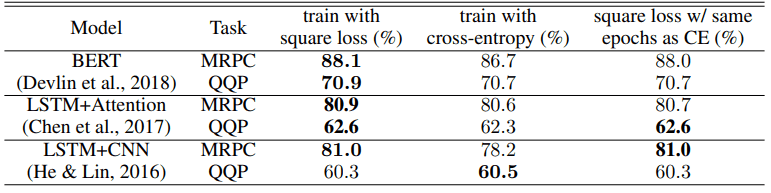
精度については、10個のタスク・アーキテクチャ設定下のうち9個について、二乗損失はクロスエントロピー以上の性能を示しています。F1スコアの場合では、6個の設定のうち5個について、同じく二乗損失がクロスエントロピーによる学習結果以上の性能を発揮しています。
エポック数が同一の場合(表の右端)でも、精度は8/10、F1スコアは5/6の設定で二乗損失の方が優れた結果を示しています。
二乗損失を利用することによる改善はタスク・モデルアーキテクチャによって異なりますが、特にQQPタスクにおけるLSTM+CNNの場合を除き、二乗損失はクロスエントロピー損失と同等以上の性能をもたらすことがわかりました。
ASRにおける実験結果
音声認識タスクにおける比較結果は以下の通りです。
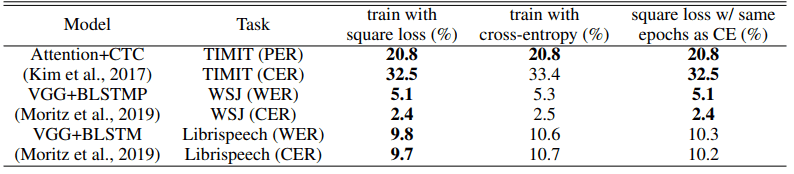
PERはphone error rateを、CERはcharacter error rateを、WERはword error rateを示しています(数値が小さい方が優れています)。全てのタスク・モデルアーキテクチャ設定下にて、二乗損失はクロスエントロピー損失の同等以上の結果を示しました。
また、利用されたデータセットの中で最もデータ量が大きいLibrispeechの場合が、相対的な性能差が最も大きくなっています(CERで9.3%、WERで7.5%)。
次に大きいデータセットであるWSJでは、性能の改善度は約4%となっており、ちょうどデータセットのサイズが大きいほど、二乗損失利用時の相対的な性能が高いという結果になっています。これが偶然なのか、データセットサイズが大きいほど二乗損失が有利となるような性質が存在するのかは不明です。学習に要したエポック数については、TIMITとWSJでは同等でした。Librispeechでは二乗損失の方が多く必要となったものの、性能面では優れた結果を示しています。
CVにおける実験結果
コンピュータビジョンタスクにおける結果は以下のようになります。

全体として、二乗損失はクロスエントロピー損失利用時と同等以下の性能を示すことが多くなっています。特にEfficientNet利用時には性能が低下していることがわかります。また、三つのデータセット全てにおいて、学習が収束するまでのエポック数はほぼ同等となりました。
NLPやASRと比べると、CVにおける二乗損失の優位性はあまり示されなかったといえます。
異なる初期化に対する性能
モデル初期化のランダム性に対するロバスト性の評価のため、異なるランダムシードを用いて初期化した場合の比較を行います。以下の図にて、二乗損失利用時と、クロスエントロピー損失利用時の精度(またはエラー率)の差が示されています。
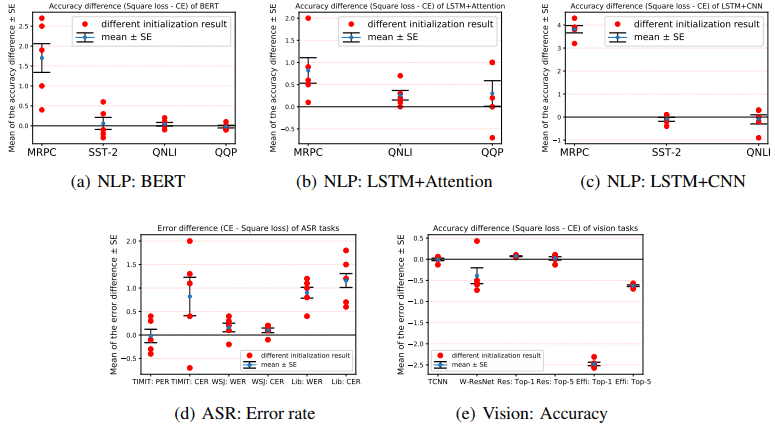
平均は青い点で、平均±標準偏差の位置が横棒で、試行結果は赤い点で示されています。
また、標準偏差の比較結果は以下の表の通りです。
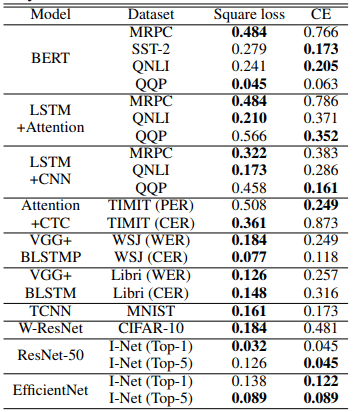
20個の設定のうち、15の設定で二乗損失の方が分散は小さくなっています。これは、二乗損失を利用した場合の方が初期化のランダム性からの影響を比較的受けにくいことを示しています。
学習曲線の観察
トレーニングの収束速度について、クラス数が少ない場合・多い場合の比較を行います。
・クラス数が少ない場合の収束速度
以下の図は、QNLIデータセットにおける学習曲線を示しています。これは2クラス分類タスクで、クラス数が少ない場合に該当します。
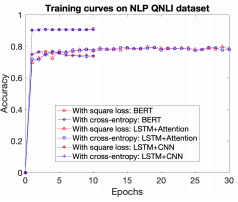
二乗損失を用いた場合は全て赤色で、クロスエントロピー損失を用いた場合は全て青色で示されています。図の通り、どちらの場合も収束速度はほぼ同じとなっています(精度は二乗損失の方が全体として優れています)。
・クラス数が大きい場合の収束速度
次に、クラス数が大きい場合の検証として、音声データセットLibrespeechと視覚データセットImageNetについての学習曲線を以下に示します。
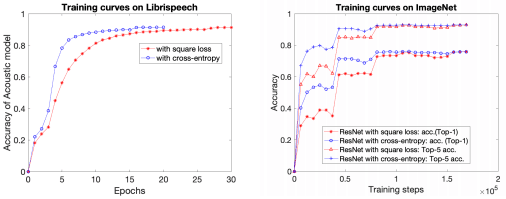
先ほどと同様、赤色は二乗損失利用時、青色はクロスエントロピー損失利用時を示しています。Librispeechでは、最終的な性能は二乗損失利用時のほうが優れているものの、収束速度は低下していることがわかります。ImageNetでも収束速度は少し低下しており、最終的な性能はほぼ同じとなっています。
解決するタスクのクラス数など、タスクの性質によって収束速度が変化するのかもしれません。
まとめ
分類タスクにおいてはクロスエントロピー損失を用いることが一般的です。しかし本論文での検証の結果、NLP・ASR・CVなどの様々なタスクにおける精度やエラー率、ランダムな初期化に対するロバスト性などの点で、二乗損失がクロスエントロピー損失と同等以上の結果を示しました。これらの結果は経験的なものですが、分類タスクにおける平均二乗誤差は、クロスエントロピー損失と同等以上に有効である可能性が示されたと言えます。
ただし、CVタスクにおける性能やクラス数が大きい場合の収束速度など、クロスエントロピー損失に劣る結果も得られており、どちらが常に優れていると断言することは出来ない点には注意が必要です。
分類タスクにおける損失関数としてクロスエントロピー損失だけを用いるのではなく、二乗損失も選択肢の一つとして検討するべきかもしれません。





この記事に関するカテゴリー






