
Diffusion Policy : 拡散モデルでロボットを動かす!ロボットがピザを作れる時代に!?
3つの要点
✔️ 拡散モデルで模倣学習を定式化
✔️ 多峰性・離散的なケースに対応し,従来手法に比べ学習も安定化
✔️ シミュレーション・実機実験において平均46.9%の成功率改善
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
written by Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, Shuran Song
(Submitted on 7 Mar 2023 (v1), last revised 1 Jun 2023 (this version, v4))
Comments: Project website: this https URL
Subjects: Robotics (cs.RO)
code:

本記事で使用している画像は論文中のもの,紹介スライドのもの,またはそれを参考に作成したものを使用しております.
はじめに
ロボットラーニングの分野においては多くの種類の研究がなされていますが,中でも活発に研究されている手法の一つが模倣学習です.模倣学習は,人間などのエキスパートがロボットを実際に操作したデータから,方策を学習する手法です.その特性上,強化学習などで問題になる報酬設計が不要であったり,実機でのデモデータを使用すればsim2realの問題がない等,他の手法に比べて優れたメリットがあります.本記事では,模倣学習の最新手法で,従来手法と比較して大きく性能を向上した研究を紹介します.
こちらの元論文の著者らのサイトには、実際にロボットが動いている様子や手法のイメージが紹介されているため、ぜひこちらも確認していただけるとより理解が深まるかと思います。
既存研究と課題
模倣学習ベースの手法では以下2つの問題に対処することが難しいとされていました.
Discontinuities(離散性)・MultiModalities(多峰性)
下図は,ロボットアームが黄色と青色のブロックを分けてそれぞれのゴールに入れるタスクを表しています.
そして,離散性とは,行動系列を離散的に切り替える必要があるケースのことで,この場合では毎度ゴールが切り替わるというタスクの特性に相当します.また,多峰性とは,目的を達成するための方法が複数存在する場合のことです.このタスクにおいては,動かすブロックは青色からでも黄色からでもよく,目的達成のための過程が複数考えられます.

Implicit Policyとその問題点
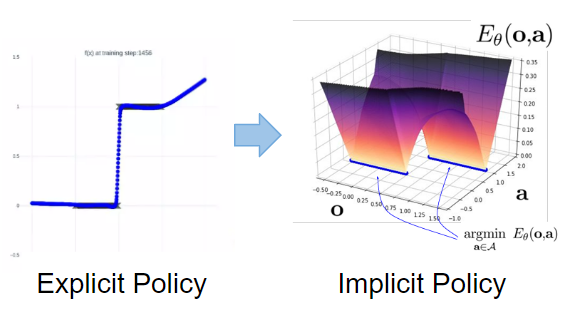
その問題に対応できるようになったのが,Implicit Policyです.これまでの従来手法はExplicit Policyと呼ばれており,その方策は$\boldsymbol{a} = F_{\theta}(\boldsymbol{o})$と,観測と行動の関係を連続関数で表現することから上記2つの問題に対処することができませんでした.
それに対して,Implicit Policyではエネルギーベースモデル(EBM)なるものを定め,$\boldsymbol{a}=\underset{\boldsymbol{a}}{\mathrm{argmin}} \hspace{2pt}E_{\theta}(\boldsymbol{o}, \boldsymbol{a})$と定義します.Explicit Policyが人が与えた軌道に連続モデルで近づけようとするのに対して,Implicit PolicyはEBMが最小となる行動を決定するので,下図のように離散性・多峰性に対処することができています.
しかし,Implicit Policyにも課題があり,それは学習が安定しないことです.行動を決定する確率は,$p_{\theta}(\boldsymbol{a}|\boldsymbol{o}) = \dfrac{e^{-E_{\theta}(\boldsymbol{o}, \boldsymbol{a})}}{z(\boldsymbol{o}, \theta)}$のようにあらわされ,その損失関数は$z(\boldsymbol{o}, \theta)$をサンプリング近似して,$L_{infoNCE}=-\mathrm{log}\left(\dfrac{e^{-E_{\theta}(\boldsymbol{o}, \boldsymbol{a})}}{e^{-E_{\theta}(\boldsymbol{o}, \boldsymbol{a})} + \color{red}{\sum_{j=1}^{N_{neg}}} e^{-E_{\theta}(\boldsymbol{o}, \tilde{\boldsymbol{a}}^j)}}\right)$と計算されます.
しかし,$z(\boldsymbol{o}, \theta)$がサンプリング近似されるために学習が不安定化する要因となってしまっています.
さらなる詳細についてはこちらの記事で解説していますので,ぜひご確認ください!
提案手法
これらの離散性・多峰性への対処や学習を安定化するために提案されたのがDiffusion Policyです.
Diffusion Policy
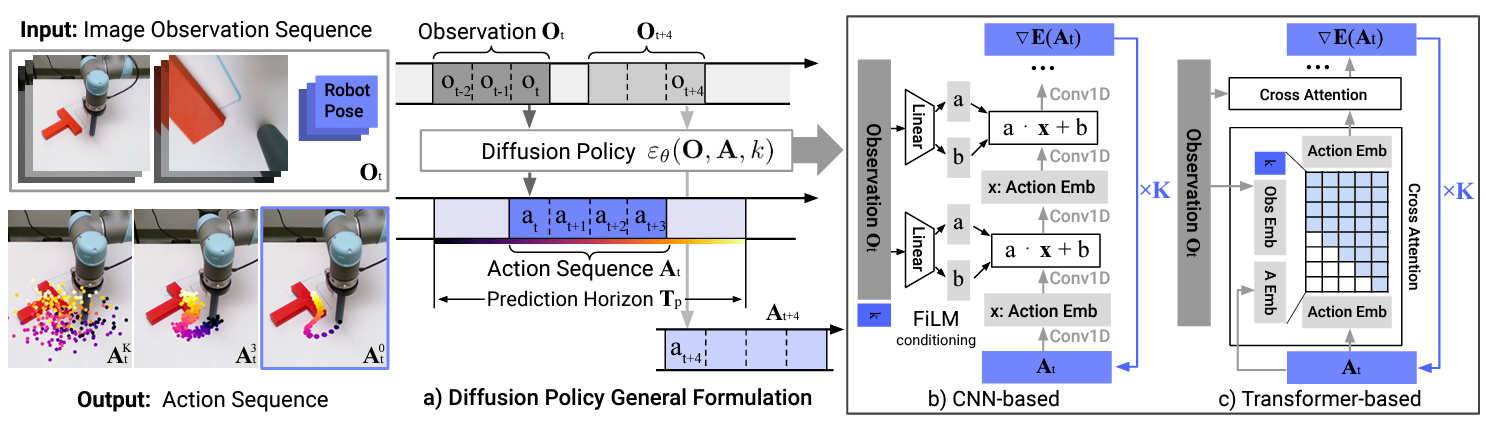
Difusion modelを利用して以下のように定式化します.
![]()
ここで,$\boldsymbol{A}_t$はロボットの行動で,$\boldsymbol{O}_t$は観測情報をembeddingしたものです.Diffusion Processに基づいて,$\boldsymbol{A}_t^K$をばらまいたのちに,ノイズの除去を繰り返し,最終的にロボットの行動軌道$\boldsymbol{A}_t^0$を生成します(下図左).また,予測型の閉ループ系になっており,一定時間ごとに観測系列を得たのち行動系列を生成するというフローです.これが制御系列を滑らかにしたり,外乱に対してロバストになることに貢献しています(下図中央).また,行動生成のアーキテクチャにはCNNとTransformerの2つを用いて検証しています(下図右).
数学的背景
なぜ,Diffusion Policyの定式化が離散性・多峰性への対処や学習の安定化へ有効かについて説明します.
まず,拡散過程におけるノイズの学習過程は,以下の過程におけるスコアを推定することと同等だと考えることができます.(詳しくはこちら)
)%7D_%7B%5Ctext%7B%E3%82%B9%E3%82%B3%E3%82%A2%7D%7D%20%2B%20%5Cunderbrace%7B%5Csqrt%7B%5Cepsilon%7D%7D_%7B%5Ctext%7B%E3%83%8E%E3%82%A4%E3%82%BA%7D%7D%20%5Cboldsymbol%7Bz%7D_t%24&f=c&r=300&m=p&b=f&k=f)
そして,このスコアを今回の問題設定で考えると,Implicit Policyで登場した行動生成確率の対数尤度の微分$\nabla_{\boldsymbol{a}} \mathrm{log} \hspace{2pt} p(\boldsymbol{a}|\boldsymbol{o})$と表現することができます.この時,スコアは,
と計算でき,サンプル近似しなければならなかった項の計算が不必要となり,学習が安定するという理論です.
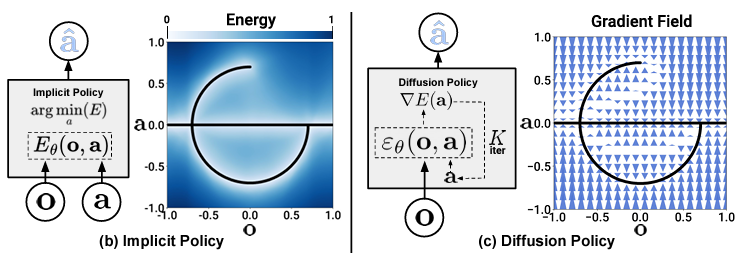
下図が,Implicit PolicyとDiffusion Policyの対応を示した図で,Implicit Policyの勾配場のようなものを考えているのがDiffusion Policyです.
特性
数学的背景を踏まえ,実際に求める特性が得られているか確認します.
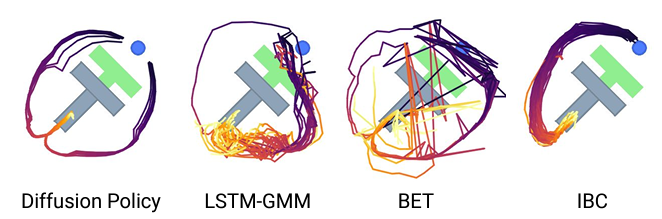
下図は,ロボットアームがT字ブロックを目標位置・姿勢にするようにどのような軌道をとったかを示しています.この場合左右どちらからロボットが向かってもよいため,解候補は大きく分けて2通りあるわけですが,Diffusion Policyのみ左右それぞれ均等に軌道を生成することができており,多峰性への対処が確認できます.
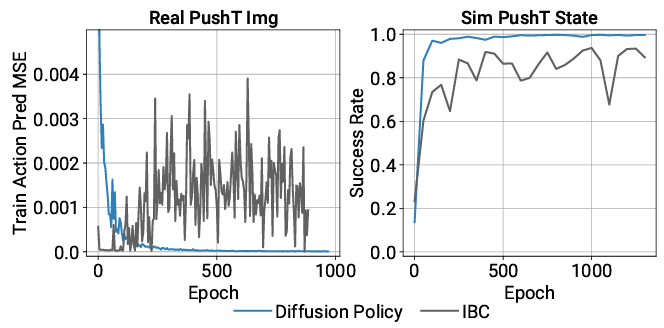
そして下図は,T字ブロックを押すタスクでの学習過程における行動の予測誤差やタスクの成功率を示しています.IBC(Implicit Policy)では学習が不安定なのに対して,Diffusion Policyは安定して学習することができており,サンプル近似をしないことの優位性が得られています.
実験
Diffusion Policyを用いて,シミュレーション実験および実機実験を行います.ここで,行動はロボットの手先位置指令や速度指令,観測はロボットの関節情報や画像情報をembeddingしたものです.こちらのサイトにある動画を見ると,よりイメージが湧くかと思います.
シミュレーション実験
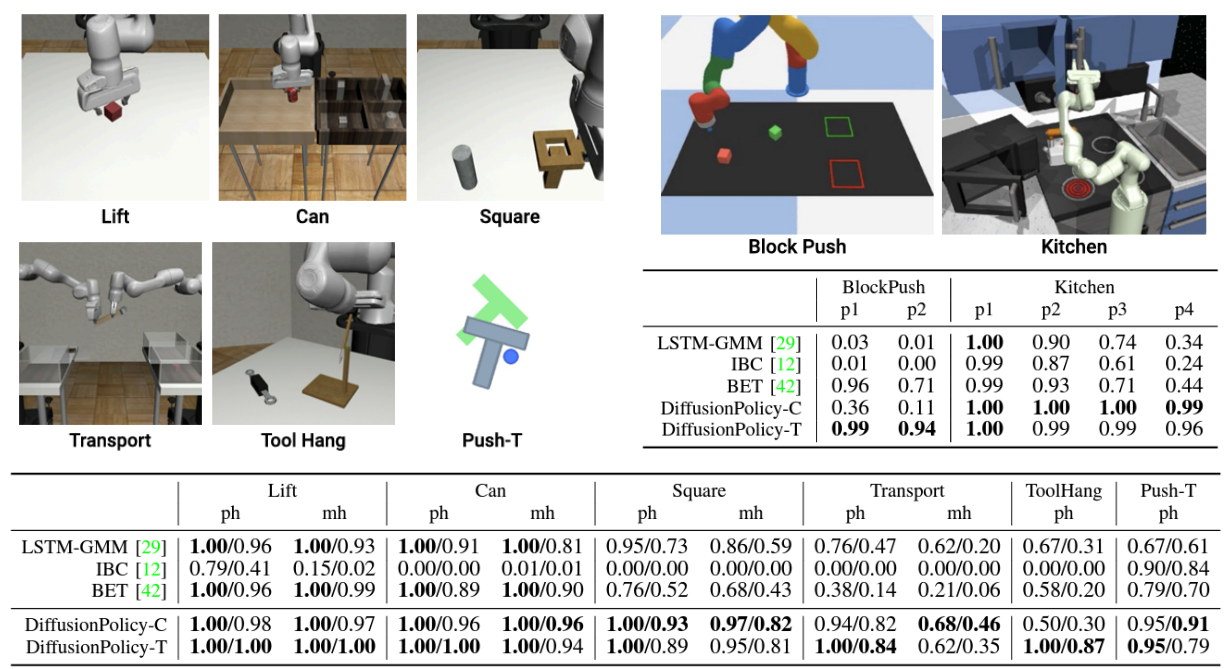
様々なシミュレーション環境・タスクで従来手法と比較を行っています.タスクの例や結果を以下に示します.従来手法の結果は各学習過程で最も性能の良いものを使用しているとのことですが,すべてのタスクにおいてDiffusion Policyがその性能を大きく上回っており,その成功率は平均で46.9%改善しています.
実機実験
行っている実験のうち2つを紹介します.
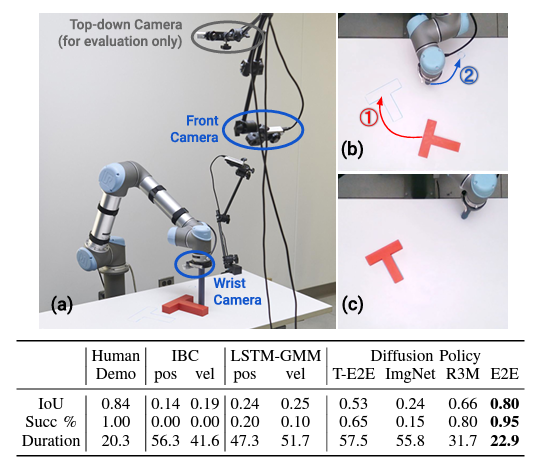
T字ブロックを目標位置・姿勢に動かすタスクでは,従来手法を大きく上回り成功率95%を達成しています(下図).動画を見るとわかりますが,人間がカメラを塞いでも微動だにしなかったり,ブロックを移動させてもすぐさま目標位置・姿勢に修正するなど,非常にロバストな方策が得られていることが確認できます.
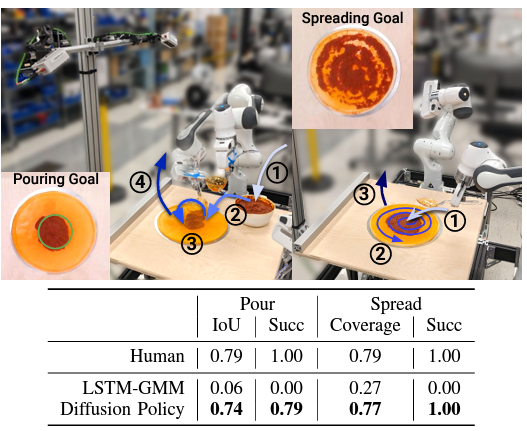
また,ピザを作るタスクにまで挑戦しています.ここでは,ピザソースをすくってピザ生地の上に乗せる動作と,そのソースをピザ生地にまんべんなく塗る動作を実験しています(下図).Diffusion Policyは,このような非剛体や流体を扱うタスクにおいても人間に匹敵する性能を発揮しています.従来手法の成功率はほとんど0%に近く,一連の行動デモデータから離散的な行動系列に分離すること(左①~④)ができずに失敗してしまっているのに対し,Diffusion Policyは行動系列を分離することができ,高い成功率を達成しています.
まとめ
本研究では,Explicit Policyの離散性・多峰性という問題とImplicit Policyの学習が不安定であるという問題に対して,Diffusion Modelを使用したDiffusion Policyが提案されました.数学的背景も存在し,実際にこれまでの課題を解決できていることも確認できています.また,シミュレーションから実環境まであらゆる実験を行い,先行研究を大きく上回る結果が得られました.
個人的には,ここまでの性能が出るのは,もちろんImplicit Policyの学習安定化という数学的側面はありますが,拡散モデルの表現力の高さも一つの要因ではないかと考えています.夢だと思っていたSFのような世界が近づいてきている感じがして,さらなる今後の発展が楽しみです.






この記事に関するカテゴリー






