Differences Between General And Medical Image Classification Models From The Perspective Of Adversarial Attacks
3 main points
✔️ Investigate the problem of adversarial attacks on medical image analysis based on deep learning
✔️ Due to the characteristics of medical images and DNN models, medical image classification models are very vulnerable to adversarial attacks
✔️ Surprisingly, the detection of adversarial attacks on medical images is very easy, achieving a detection AUC of more than 0.98
Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems
written by Xingjun Ma, Yuhao Niu, Lin Gu, Yisen Wang, Yitian Zhao, James Bailey, Feng Lu
(Submitted on 24 Jul 2019 (v1), last revised 13 Mar 2020 (this version, v2))
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Image and Video Processing (eess.IV)
code:
Outline of Research
Recently, an adversarial attack on AI models has been discovered. In this attack, the input data to the AI model is modified to make the AI model produce inappropriate output. There has been a great deal of research in this area. However, most of the datasets that have been considered are generic images. Therefore, the authors focused on medical images as a dataset to see how the adversarial attack behaves on different datasets.
In this paper, we investigate the nature of adversarial attacks on medical images and show that medical image classification models are highly vulnerable to adversarial attacks. We also show that while medical image classification models are vulnerable to adversarial attacks, they are surprisingly easy to detect. The authors argue that these differences between regular and medical image classification models are due to the properties of medical images and DNN models.
related research
What is Adversarial Attack?
An adversarial attack is an attack in which the input data is manipulated to cause the target model to produce incorrect output. The attack is performed by adding noise, called an adversarial perturbation, to the input data. For more details, please refer to the following article.
How To Prevent Overfitting In Adversarial Training
Medical Image Analysis
Most of the diagnostic methods are based on inputting various images from ophthalmology, dermatology, radiology, etc. into a CNN and learning the features. The CNNs used here are the state of the art that existed at the time, such as AlexNet, VGG, Inception, and ResNet. While these methods have done as well as standard computer vision object recognition, they have been criticized for their lack of transparency. Because of the nature of deep learning-based models, it is currently difficult to validate inferences, and the presence of adversarial samples may further undermine confidence in the models.
Analysis of hostile attacks on medical imaging.
Now we will show the results of the attack on the DNN model, which has shown some success against medical images.
Setting up an attack
We assumed the following four types of attacks.
- FGSM
- BIM
- PGD
- CW
All these attacks generate the adversary sample after setting the size of the noise to be put on the data. Therefore, if the attack succeeds even with a small noise, the attacker is considered vulnerable, and conversely, if the attack only succeeds with a large noise, the attacker is considered robust.
Results on a binary classification data set

The results for the binary classification data set are shown above. As generally expected, when large noise is added, the accuracy drops significantly, as it does for normal images. However, for normal image data such as CIFAR-10 and ImageNet, the size of the noise at which an attack succeeds is $\epsilon = \frac{8}{255}$, so medical images that are successfully attacked with $\epsilon = \frac{1}{255}$ are relatively vulnerable. This means that medical images are relatively vulnerable.
Results on multi-level classification data sets.
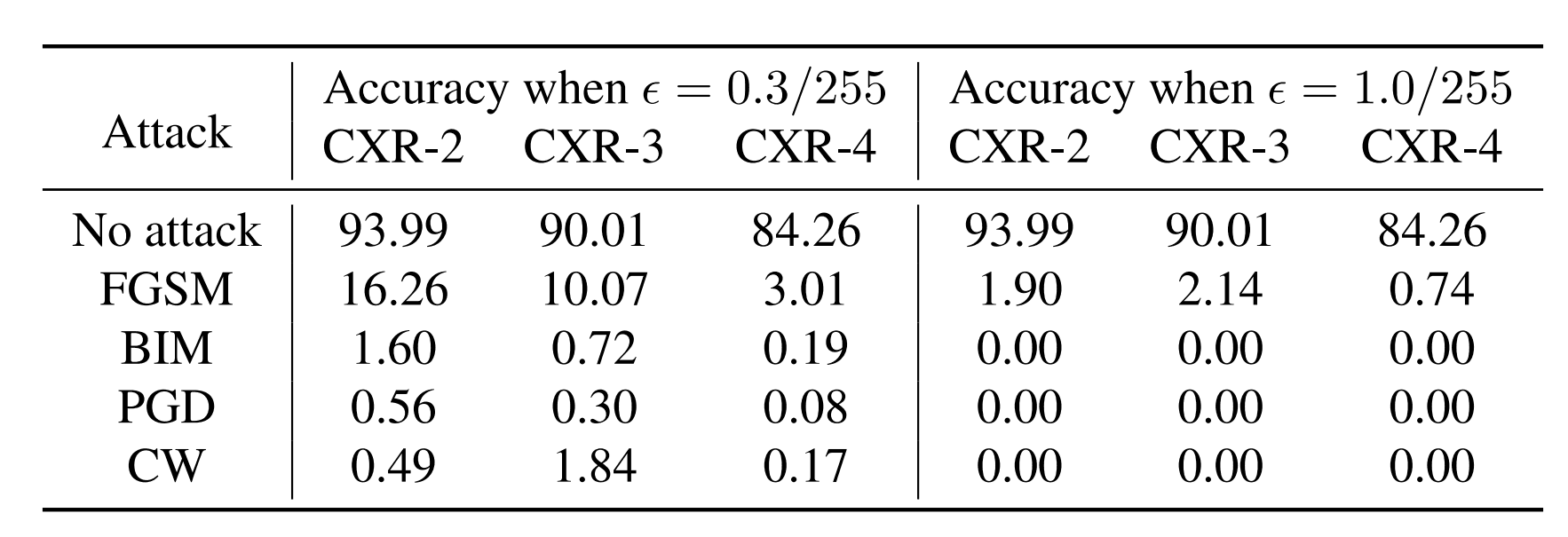
The results for the multi-level classification dataset are shown above, where the numbers in CXR-2 and CXR-3 represent the number of classes. Therefore, CXR-2 is binary classification and CXR-3 is trivalent classification. The higher the number of classes, the higher the success rate of the attack. When comparing the same noise magnitude to each other, it can be seen that the more classes there are, the lower the accuracy becomes. In our dataset of medical images, the attack succeeds even for a very small value of $\epsilon = \frac{0.3}{255}$, indicating that medical images are very vulnerable.
Why are medical images more vulnerable than ImageNet images? It is a very interesting fact because the image size is the same. We will now discuss this phenomenon in more depth.
Why is the medical model so fragile?
Medical Image Analysis

The figure above shows the saliency map of normal images and medical images. In the normal image, the high saliency area is concentrated in a small area, but in the medical image, it is spread over a wide area. Since a hostile attack adds noise to the entire image, the medical image will have a larger proportion of noise in the high saliency areas when the noise is of the same size. It is thought that this leads to the vulnerability of medical images to hostile attacks. However, we could not conclude that this is the complete cause because there are also normal images that have this kind of saliency map.
Analysis of the DNN model
The structure of DNNs performing tasks on medical images is based on network structures that have been used with great success for normal images, such as ResNet. We will show that these networks are overly complex for simple medical image analysis tasks, which is one source of vulnerability.

The third line in the above figure shows the representation learned in the middle layer of ResNet-50. Surprisingly, we can see that the deep representation of medical images is much simpler than that of normal images. This indicates that in medical images, the DNN model learns simple patterns from a large region of interest, perhaps only relevant to the lesion.
In the above discussion, we have seen that we only need to learn simple patterns for medical image analysis. Complex DNN models are not required for learning simple patterns. Therefore, the authors decided to investigate the loss distribution of individual input samples to see if the high vulnerability can be attributed to the use of an overly parameterized network.

The above figure visualizes the loss distribution for an input image. Normal images show a gentle loss distribution, while medical images show a relatively steep distribution. Medical images are vulnerable to adversarial attacks because the loss values are large except where the loss drops sharply. This is caused by using a network that is overparameterized for the task.
Therefore, if we consider the vulnerability of medical models in terms of DNN models, we can see that it is due to the use of over-parameterized models.
Attack detection on medical images

The above figure shows the flow of hostile sample detection. We used the intermediate features of the medical image classification model to create the classifier. The result was as follows.

The results of four different attacks on three different datasets (Fundoscopy, Chest X-Ray, and Dermoscopy) are shown. In most cases, the AUC is less than 0.8 for normal images, whereas, for medical images, the AUC is higher. Especially in the case of KD-based detectors, which are very high AUCs for all datasets and attacks, DFeat is the case of using only deep features, but even in this case, it achieves very high AUCs, indicating that the deep features may be fundamentally different for hostile and normal samples.
Deep feature analysis

In order to compare the deep feature values of normal and hostile samples, an example of visualization using t-SNE is shown in the figure above. In this visualization, we can see that there is a big difference in the feature values between the normal sample and the hostile sample. In the case of normal image datasets, it is difficult to separate them cleanly like this even using t-SNE, so we can see that the deep features of medical images have different properties.
Summary
In this paper, we investigate the vulnerability of medical image classification models to adversarial attacks. As a result, we found that the medical image classification model is much more vulnerable than the normal image classification model. However, we also found that attack detection is easier for medical images than for normal images, and this is due to the fact that the deep features of adversarial samples and normal samples for medical images are easier to classify than those for normal images. These findings contribute significantly to ensuring the reliability of medical image analysis models.



Categories related to this article






