![MuLan] Multimodal Music-Text Using Contrastive Learning](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/mulan.png)
MuLan] Multimodal Music-Text Using Contrastive Learning
3 main points
✔️ Music-Text multimodal with contrastive learning
✔️ Using two encoders to add text to music
✔️ Music search and tagging with text hit high accuracy
MuLan: A Joint Embedding of Music Audio and Natural Language
written by Qingqing Huang, Aren Jansen, Joonseok Lee, Ravi Ganti, Judith Yue Li, Daniel P. W. Ellis
(Submitted on 26 Aug 2022)
Comments: To appear in ISMIR 2022
Subjects: Audio and Speech Processing (eess.AS); Computation and Language (cs.CL); Sound (cs.SD); Machine Learning (stat.ML)
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
Introduction
Recently, there has been a lot of research into explaining and classifying data in natural language. Specifically, the idea is to use text to describe images and sounds. For example, a dog in a picture can be described by the text "dog," or a certain sound can be classified as "birdcalls.
Especially in the image field, there is a large amount of captioned image data available, which allows for more accurate learning. However, audio data is currently less accurate than images because there is less such captioned data available.
Therefore, in this study, a system called MuLan was created to successfully represent images of music ("sad" or "rock") with text. This MuLan is a contrastive learning model for learning the relationship between music and text.
With this MuLan, it is now possible to find information about music with high precision and to describe music in words.
Technique
The main method of this study is Contrastive Leraning (Contrastive Learning) using "music" and "text" as shown in the figure below.
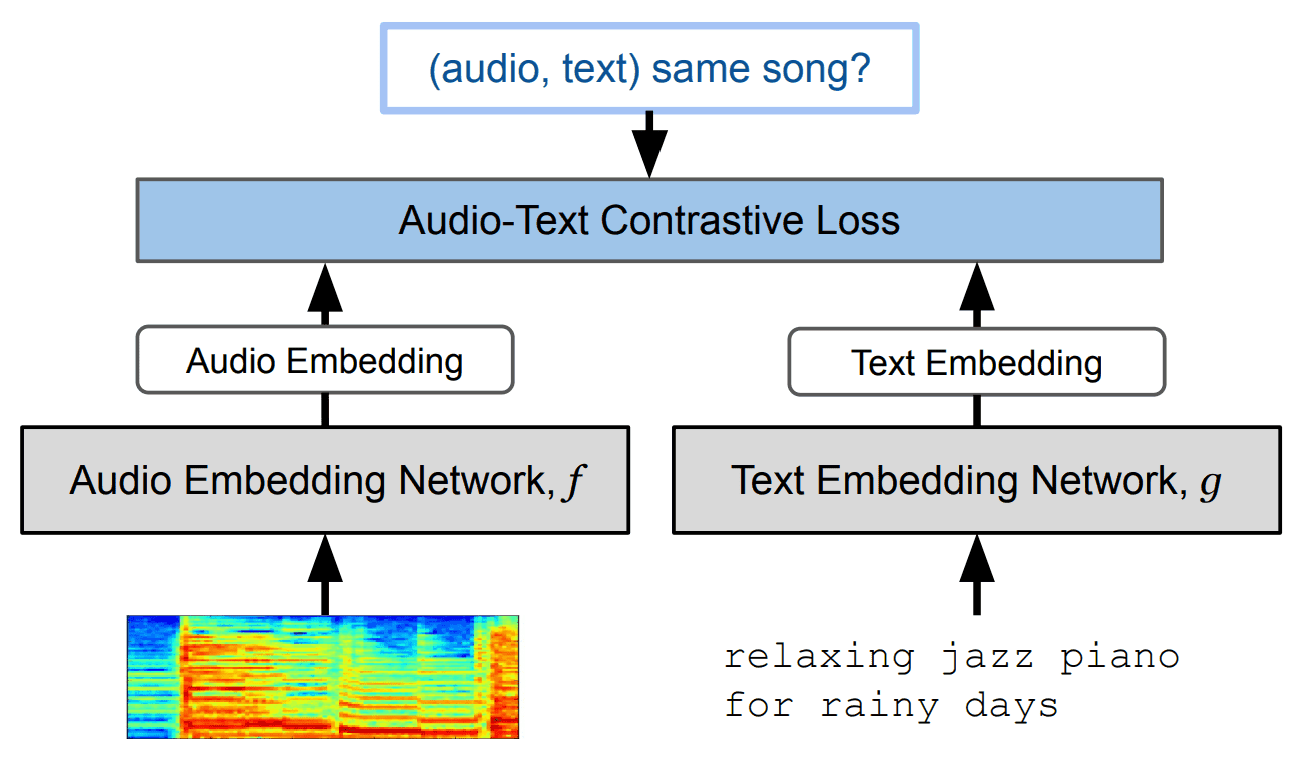
Specifically, the procedure is as follows
- Encode music log-mel spectrograms with Resnet-50 or AudioSpectrogramTransformer
- Encode text in BERT
- Minimize the following loss function using the above two embeddings
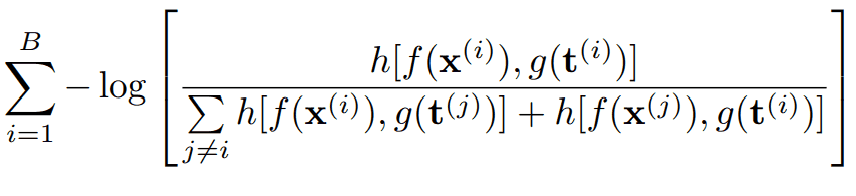
The components of this loss function are, respectively
- B: Mini batch size
- f(x ): Music embedding
- g(t): text embedding
- h[a, b]: critic function
Here, the "Audio Spectrogram Transformer (AST)" is based on the Vision Transformer (ViT) technology, which has been successful in the field of image processing. AST uses 12 layers of Transformer to process spectrograms as "tokens.
Resnet-50 is also used, indicating that the music log-mel spectrogram is treated as an "image" in the encoding of music data.
Data-set
MuLan's training is based on a dataset collected from 50 million music videos on the Internet.
Voice data
First, "30 seconds of audio beginning at the 30th second" is cut from the Internet music video as audio data. Next, the music data, of which more than half is not music, is discarded to determine if these audios are in fact music. This results in a total data set of approximately 370,000 hours.
Character data
In addition, the following three types of text data are used
- SF: Short text, e.g. title of the music
- LF: Longer text, such as song descriptions or comments by viewers
- PL: Title of the playlist containing this song
Examples of text data are as follows

Here, BERT is used to clean up the text and remove text unrelated to the music content for LF and SF. The resulting text data size is as follows
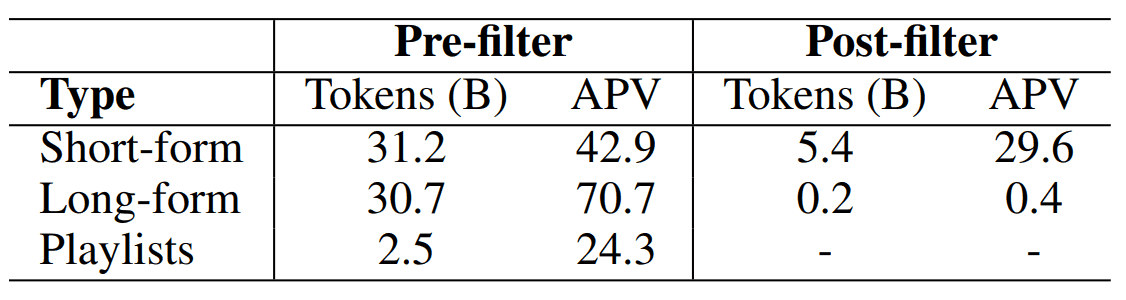
(APV is the average of text annotations per piece of data, including those without text annotations)
AudioSet
A dataset called AudioSet was used to create 10-second audio-text pairs, and approximately 2 million data were added to the dataset.
These different data sources vary widely in size and quality, so they are divided into smaller "mini batches" of data and mixed together in a balanced manner.
Evaluation Experiments and Results
The following four task performances were evaluated for performance assessment
- Tagged with zero shot music
- Transition learning to the above model
- Music search from text query
- Text Encoder Rating
As for MuLan's audio encoders, as mentioned earlier, ResNet-50 (M-ResNet-50) and AudioSpectrogramTransformer (M-AST) are available, and comparisons are made separately in each case.
Let's look at each of these in turn, the methods and the results.
Zero-Shot Music Tagging and Transition Learning
This assessment was conducted with the following two benchmarks
- MagnaTagATune (MTAT)
- AudioSet
The predictive score for tagging zero shot music is defined by the cosine similarity between the "audio embedding" of the music clip and the "text embedding" of each tag.
We also use the same two benchmarks in our evaluation of transition learning as we did earlier.
Those results are as follows.
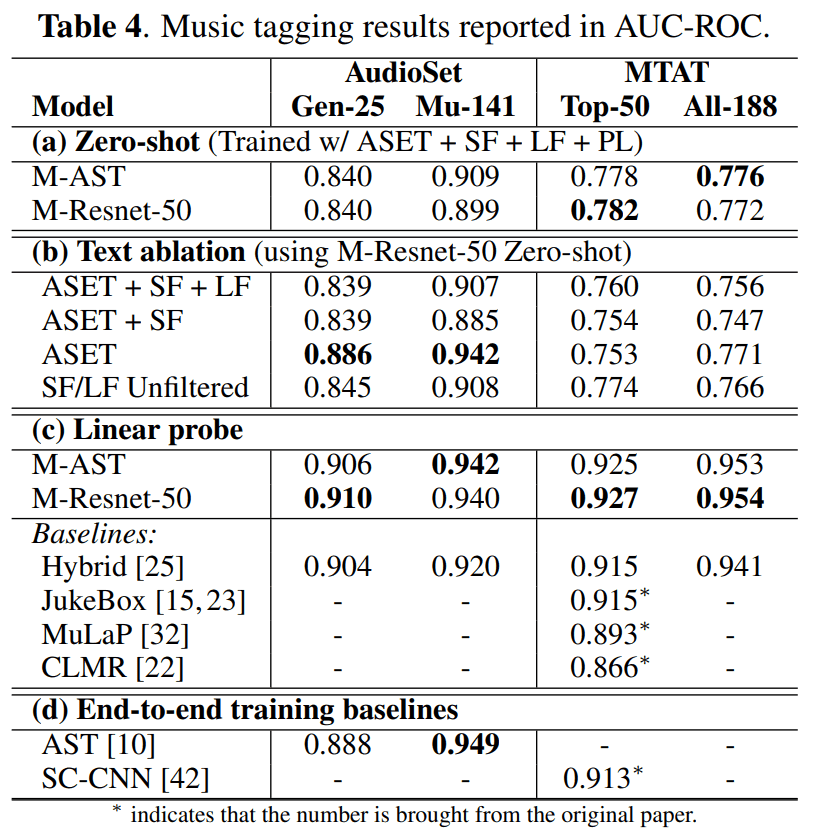
・Zero-shot tagging performance for music
Table 4(a) shows the results of "tagging music with zero shots". The audio encoders Resnet-50 and AST show similar performance.
・Impact of filtering text data
Table 4(b) shows the results of the impact of filtering text data on performance. As can be seen, the highest accuracy is achieved when training using only the AudioSet.
Here, surprisingly, training with unfiltered data achieved performance comparable to the filtered case. It is possible that the text filtering was excessive, and that some of the judged text that was not explicitly music-related was actually significant. Alternatively, it could be that the contrast learning with MuLan is robust to noise.
・Transition learning results
Table 4(c) shows that when linear exploration is applied to MuLan's speech embedding, it achieves the best performance in transition learning for all tagging tasks.
Therefore, MuLan's pre-trained speech encoder could be diverted to other tasks.
Music search from text query
The assessment uses a collection of 7,000 expert-selected playlists that do not duplicate the playlist information used in the study. Each expert-selected playlist has a title and description and contains 10,100 music recordings.
The title of a playlist is usually a short phrase, consisting of a genre, subgenre, mood, activity, or artist name. The "Playlist" in the table below is an example.

Here, the AUC-ROC and the mean average goodness of fit (mAP) are the indicators. Also, as in the zero shot tagging case, the evaluation is based on cosine similarity.
The results are as follows
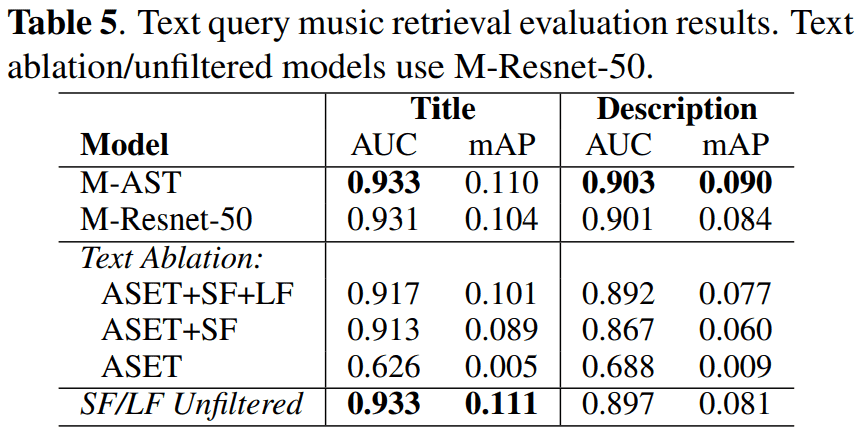
The results show that adding "large SF retrieved from the Internet" to ASET helps the model learn more detailed musical concepts. Furthermore, the inclusion of comments and playlist data enabled the model to understand more complex queries.
Again, good performance was observed with unfiltered text.
Text Encoder Rating
To measure the performance of MuLan's text encoder compared to traditional pre-trained BERT models, we evaluate it using a triplet classification task.
Each triplet consists of three text strings of the form "anchor," "positive," and "negative. If the positive is closer to the anchor than the negative in the text embedding space, it is considered correct.
The following two datasets were used for this evaluation
| data-set | Contents |
|---|---|
| AudioSet Ontology | For each of the 141 music-related classes, 5 triplets were constructed using the label string as anchor text, the long form description as positive text, and the long form description of 5 random classes as negative text |
| Playlist data collected by experts |
Sampling playlists and setting their titles and descriptions as anchor text and positive text, respectively Set negative text as a description of another randomly sampled playlist |
An example of the contents of the data set can be found in Table 3 earlier.
The results are as follows
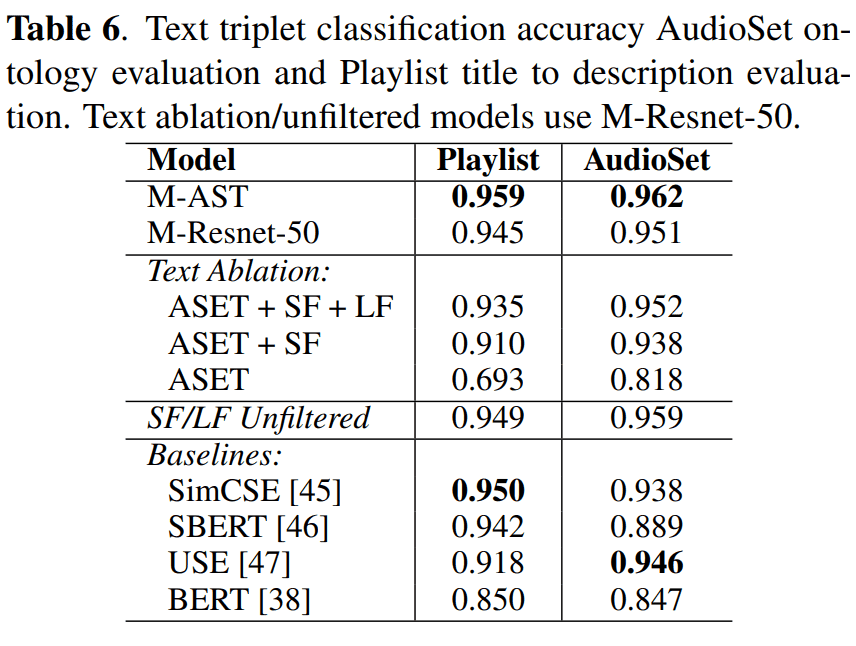
Here we compare the following four models
- Sentence Transformer
- SimCSE
- Universal Sentence Embedding
- BERT
The results show that the MuLan text encoder performs better than other general-purpose models. In this regard, MuLan is a music-specific model, so its high performance in the music field is not in itself surprising.
However, I think it is great that you have achieved SOTA without using fine tuning or other methods.
Summary
MuLan, introduced in this article, is also used in MusicLM, a Text-to-Music generation model. This MusicLM model takes a text prompt as input and generates music according to its content.
In this way, MuLan can be helpful in "linking music and text.



Categories related to this article

![CLAP] Contrastive Le](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/December2023/clap_2_-520x300.png)
![LP-MusicCaps] Automa](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/November2023/lp-musiccaps-520x300.png)


