![InfiMM-WebMath-40B] Improves The Mathematical Performance Of LLM With A Dataset Consisting Of 2.4 Billion Mathematical Documents!](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2024/infimm-webmath-40b_1_.png)
InfiMM-WebMath-40B] Improves The Mathematical Performance Of LLM With A Dataset Consisting Of 2.4 Billion Mathematical Documents!
3 main points
✔️ Proposes InfiMM-WebMath-40B, a large multimodal dataset to improve mathematical reasoning capabilities
✔️ Combines text and images collected from 2.4 billion web pages to optimize MLLM training
✔️ Demonstrates superior inference performance on MathVerse and We-Math benchmarks, pushing the limits of open source models
InfiMM-WebMath-40B: Advancing Multimodal Pre-Training for Enhanced Mathematical Reasoning
written by Xiaotian Han, Yiren Jian, Xuefeng Hu, Haogeng Liu, Yiqi Wang, Qihang Fan, Yuang Ai, Huaibo Huang, Ran He, Zhenheng Yang, Quanzeng You
(Submitted on 19 Sep 2024)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
Proposed Method
In this paper, we propose a new large-scale multimodal pre-training dataset, InfiMM-WebMath-40B, to enhance mathematical reasoning capabilities. This dataset consists of 2.4 billion science and math related web documents, 8.5 billion image URLs, and approximately 40 billion text tokens. It supports the training of Multimodal Large Language Models (MLLMs), which have the ability to process a combination of text and images to improve reasoning, especially in mathematical problems.
Specifically, this dataset is collected from CommonCrawl, a large web-scraping repository. It is created by first screening billions of web pages to select only those related to science and mathematics, and then further filtering the data from there with images and text linked to each other. This process uses specific rule-based and model-based filtering techniques. The end result is 24 million high-quality web documents, optimized for mathematical reasoning training.
Several experimental results have confirmed that this dataset can be used to build MLLMs that show performance beyond that of traditional open source models. For example, recent benchmarks such as "MathVerse" and "We-Math" have made significant advances in problem solving by effectively combining text and images, especially in mathematical reasoning with a visual component.
This approach is expected to accelerate the development of MLLMs that can effectively solve complex mathematical problems, especially those that make extensive use of mathematical expressions, graphs, and diagrams. It is emphasized that the large scale and high quality of the proposed dataset makes it a very important resource for the entire open source community.
Experiment
The experiments in this paper use several benchmarks to validate the InfiMM-WebMath-40B dataset. The purpose of the experiments is to verify how well the proposed dataset improves the performance of a large-scale multimodal mathematical reasoning model (MLLM).
First, the architecture of the model is based on state-of-the-art vision language learning methods, using the SigLip model to extract visual features and the Perceiver Resampler for the visual and textual binding part. two LLMs (DeepSeek- Coder 1.3B and DeepSeek-Coder 7B) were used in the experiments.
Training was conducted in three phases. The first was the modality alignment phase, in which we trained using common image-text pairs to bridge the gap between visual and textual modalities. In this phase, the visual encoder and LLM backbone were fixed and only the Perceiver Resampler was trained.
Additional pre-training was then performed using the InfiMM-WebMath-40B dataset to enhance multimodal mathematical knowledge acquisition. Here, training was performed for one epoch using a context length of 4096 tokens and a maximum of 32 images.
The last stage involved fine tuning using the instruction data set. In this phase, the visual encoders were fixed and the parameters of the Perceiver Resampler and LLM were updated. Datasets such as ScienceQA and DocVQA were used for training, which improved the instruction following capability.
As a result of the experiments, models using InfiMM-WebMath-40B performed well on two benchmarks, MathVerse and We-Math. In particular, the MathVerse benchmark outperformed the traditional open source model, and the We-Math model also demonstrated excellent multimodal inference capabilities. In particular, the 7B model showed performance comparable to other 72B and 110B models.
Conclusion
The conclusion of this paper highlights that InfiMM-WebMath-40B, as the first publicly available large-scale multimodal mathematical pre-training dataset, is an important contribution to the open source research community. The dataset enables advanced learning, especially in mathematical reasoning, combining text and images, and provides a foundation for improving the ability to solve complex mathematical problems.
Models using InfiMM-WebMath-40B performed better than traditional open source models, especially on the latest benchmarks such as MathVerse and We-Math. In particular, the 7B model achieved performance comparable to other large models of 72B and 110B. These results demonstrate that InfiMM-We-Math-40B's high-quality multimodal dataset greatly enhances its mathematical inference capabilities.
Future research indicates plans to enhance visual encoders to efficiently process mathematical symbols, diagrams, and expressions, and to further improve mathematical reasoning capabilities using reinforcement learning techniques. This is said to pave the way for addressing the complexity of multimodal mathematical reasoning and developing even more accurate AI models.
Explanation of Figures and Tables
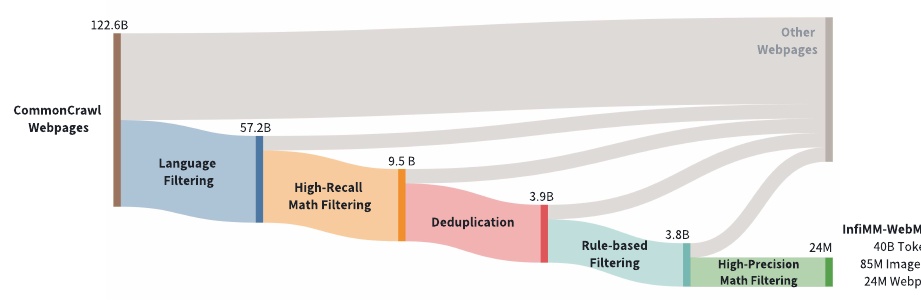
This figure illustrates the process of building the InfiMM-WebMath-40B math-related dataset. To begin, we start with a large web dataset called CommonCrawl, which covers 12.26 billion web pages.
In the first step, "Language Filtering" is applied to narrow down the list to 5.72 billion pages filtered on a language basis. High-Recall Math Filtering" is then applied to identify relevant math content, resulting in 950 million pages.
Next, "Deduplication" removes duplicate data, reducing the number of pages to 390 million. After this process, "Rule-based Filtering" is performed to remove more unnecessary elements. The number of data at this stage is 380 million pages.
Finally, "High-Precision Math Filtering" retains only high-precision math content, ultimately selecting approximately 240,000 pages. These 240,000 pages contain 4 billion text tokens and 85 million images. This filtering process builds a high-quality, math-specific dataset.
This diagram visually illustrates the concept of "electric flux" as it relates to Gauss's Law. The diagram shows a charge in a curved surface-like shape with electric field lines drawn around it. These electric field lines show how the electric field spreads around the charge.
Positive and negative charges are shown in the center of the diagram, with electric field lines toward or away from them. The electric flux is the sum of the electric field lines passing through this plane and is proportional to the sum of the charges enclosed by the plane. In other words, the greater the amount of charge enclosed, the greater the electrical flux.
The dA vector represents a minute area element at just that part of the surface and depicts the relationship between the electric field lines and the surface. This diagram serves as part of a visual aid in physics and electromagnetism to help students understand important concepts.
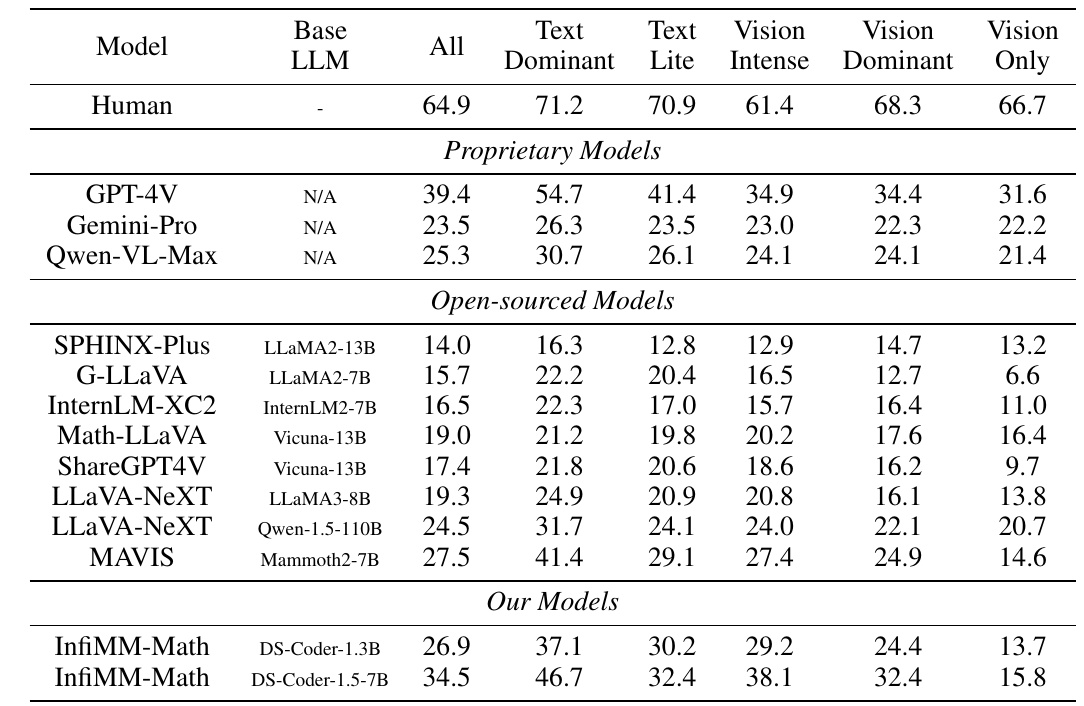
This table evaluates the performance of different models.
- The first column of the table shows the model name. Human" indicates the human performance criterion.
- Next, "Base LLM" indicates the type of large-scale language model (LLM) on which each model is based.
- The "All" column represents the overall score for all types of tasks.
- The following columns show the scores according to the characteristics of the task: "Text Dominant" indicates a task with text as the main source of information, "Text Lite" indicates a task with little text information, "Vision Intense" indicates a task with a lot of image information, "Vision Dominant" indicates a task with images as the main source of information, and "Vision Only" indicates a task with completely image information. Vision Dominant" is for tasks with images as the main source of information, and "Vision Only" is for tasks that are completely image-only.
In this table, three non-public models are evaluated as "Proprietary Models": GPT-4V, Gemini-Pro, and Qwen-VL-Max. In addition, "Open-sourced Models" is a group of models that are publicly available, including SPHINX-Plus, G-LLaVA, InternLM-XC2, and Math-LLAVA, among others.
Finally, "Our Models" lists two models, InfiMM-Math DS-Coder-1.3B and DS-Coder-1.5-7B. These models outperform other open source models on some scores.
Overall, the InfiMM-Math model performs well, especially in "All," "Text Dominant," and "Vision Intense," demonstrating its superiority in tasks that combine visual and textual information. This is the result of designing the model to improve its ability in complex tasks that use both visual and textual information in a way that is easy for even novice machine learners to understand.
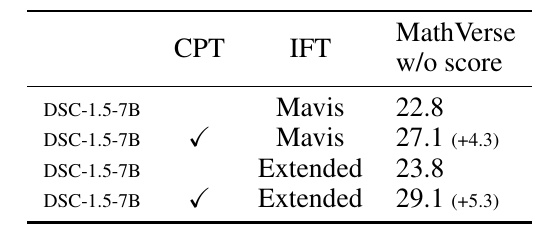
This figure shows the evaluation results of the machine learning model. Specifically, it compares the DeepSeek-Coder 1.5-7B model's scores on the evaluation criterion MathVerse in different training settings.
There are two main training methods in the table: CPT (Continue Pre-training) and IFT (Instruction Fine-Tuning). These are methods that improve the performance of the model.
- Results are shown for two different datasets, "Mavis" and "Extended".
- Without CPT, a score of 22.8 was obtained on the Mavis data set, which improves to 27.1 with CPT.
- In the Extended dataset, using CPT improves the score from 23.8 to 29.1.
From this table, we can see that the performance of the model is enhanced when CPT is used. The improvement is especially noticeable on the Extended data set, which uses more diverse data.
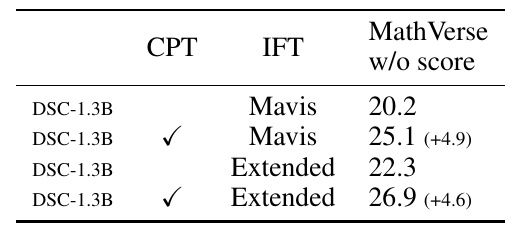
This table shows the results of an experiment conducted on one machine learning model. Specifically, it measures the effect of two different training methods, "CPT" and "IFT," when combined.
- CPT" stands for Continual Pre-Training, a method of retraining models while using existing data sets.
- IFT" stands for Instruction Fine-Tuning, a method of tuning a model with an instruction-based data set.
The table shows the following information
- DSC-1.3B" is the name of the model used.
- Mavis" and "Extended" are the names of different data sets.
- The "MathVerse w/o score" indicates your score on the MathVerse rubric. Its score measures your ability to solve mathematical problems.
- For example, the score is 20.2 when evaluated on the "Mavis" data set alone, but improves to 25.1 when the "CPT" is performed.
These results show that combining different training methods improves the performance of the model. The range of score improvement for each is also shown in detail to help understand the specific effects of the methods.
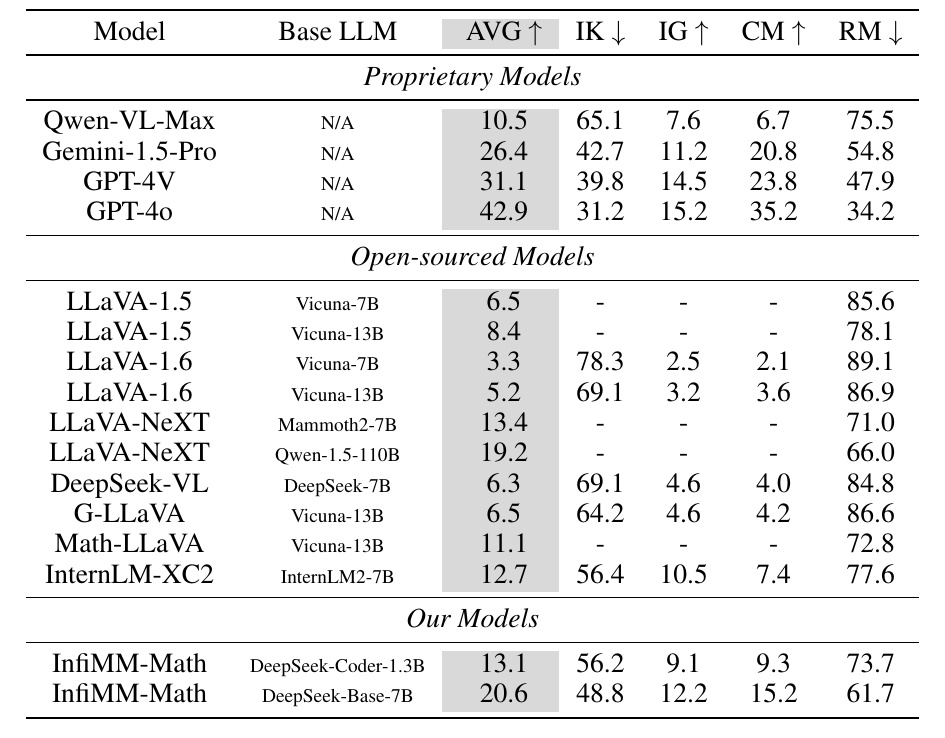
This table compares how well various language models (LLMs) perform on a math-related benchmark called We-Math.
Model and Base LLM columns:.
- The Model column lists the name of each model, with the base model (Base LLM) used below it.
- Base LLM is the primary model used for natural language processing and is used in each model.
Proprietary Models:.
- These are private models owned by companies.
- Various models with different performance are available, such as Qwen-VL-Max and GPT-4o.
Open-sourced Models: Open-sourced models are used to create a variety of models.
- It is a publicly available open source model.
- Many models are listed, including the LLaVA series and DeepSeek-VL.
Our Models:.
- This is a model that the research team developed themselves.
- We can see that InfiMM-Math uses the DeepSeek-Coder-1.3B and DeepSeek-Base-7B base models.
Performance Indicators
- AVG indicates the average performance score. Higher means better overall.
- IK (Insufficient Knowledge) is the percentage of cases of insufficient knowledge, the lower the better.
- Inadequate Generalization (IG) is a measure of inadequate generalization; the higher this value, the better.
- CM (Complete Mastery) indicates complete understanding and should be high.
- RM (Rote Memorization) is the rate of rote memorization, with lower values indicating more natural understanding.
The purpose of this chart is to provide an easy visual indication of how well each model performs. It serves as a means of measuring a model's overall mastery or lack of knowledge. It also shows that proprietary models are competitive with other publicly available models.
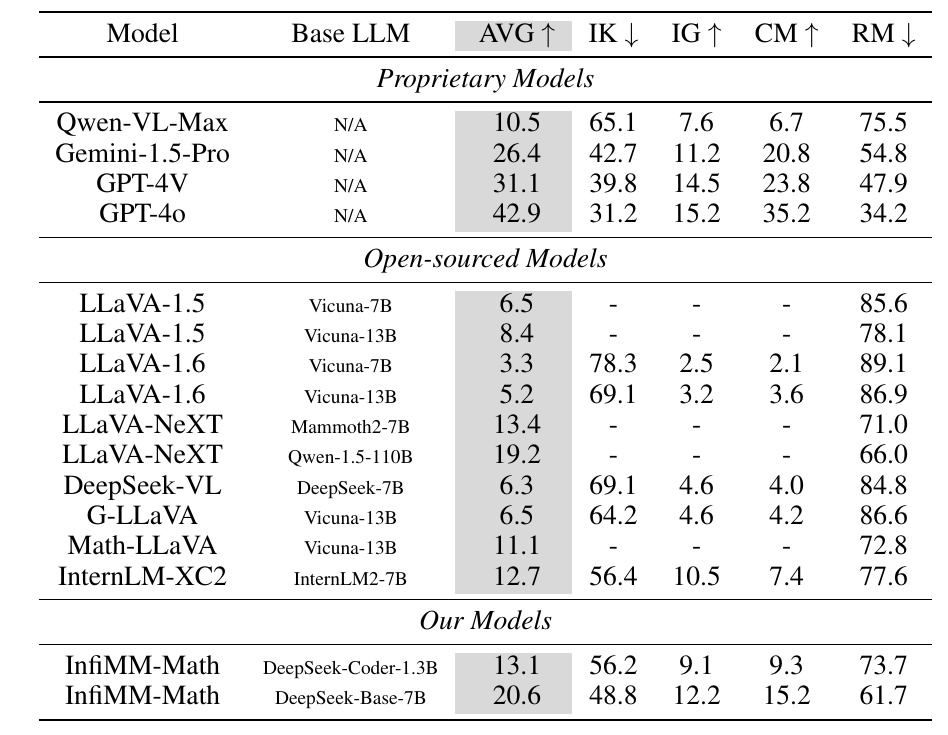
This figure is a table comparing the performance of different machine learning models. It includes the average score for each model (AVG) and scores based on specific evaluation criteria (IK, IG, CM, RM).
- The category "Proprietary Models" includes proprietary models such as Qwen-VL-Max and GPT-4V, each of which is scored on a different evaluation index. For example, GPT-4o has a particularly high "CM" score (35.2) compared to the other models.
- The category "Open-sourced Models" includes open-source models such as the LLaVA series and Math-LLaVA. These models generally tend to have lower AVG scores than proprietary models, but some models with more emphasis on visual information can be found.
- Our Models" shows a proprietary model called InfiMM-Math, which uses basic models such as DeepSeek-Coder-1.3B and DeepSeek-Base-7B. These models score as well or better than other open source models on some evaluation criteria (IK, IG, CM).
This table is intended to provide an at-a-glance understanding of the strengths and weaknesses in the performance of different models and is especially useful for those interested in mathematical reasoning skills.

This table shows the results of the evaluation of the classification models. The two models used are the LLM-Classifier and the FastText-Classifier. For each model, the scores on the benchmarks MMLU (STEM) and GSM8K are listed.
First, the "MMLU (STEM)" is an assessment to measure knowledge in various scientific and technical fields, with the LLM-Classifier scoring 32.8 and the FastText-Classifier 31.1. Next, the GSM8K is a benchmark that assesses mathematical reasoning, with the LLM-Classifier scoring 17.5% and the FastText-Classifier 20.2%. This indicates that FastText-Classifier is superior in GSM8K.
The average length of the text is also shown, with the LLM-Classifier averaging 2500 and the FastText-Classifier averaging 1700. This suggests that the FastText-Classifier may be more effective even when there is less information listed.



Categories related to this article

![[EDAT24] Event-based](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/July2024/edat24-520x300.png)

