
See Finer, See More: Implicit Modality Alignment For Text-Based Person Search
3 main points
✔️ The same encoder was used for text and images so that the interaction of both modalities could be learned.
✔️ Text was divided into sentence, sentence, and word levels, and image-text matching was performed at multiple levels.
✔️ Image-text matching was done by using both image and text embeddings to solve mask language modeling.
See Finer, See More: Implicit Modality Alignment for Text-based Person Retrieval
written by Xiujun Shu, Wei Wen, Haoqian Wu, Keyu Chen, Yiran Song, Ruizhi Qiao, Bo Ren, Xiao Wang
(Submitted on 18 Aug 2022 (v1), last revised 26 Aug 2022 (this version, v2))
Comments: Accepted at ECCV Workshop on Real-World Surveillance (RWS 2022)
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

The images used in this article are from the paper, the introductory slides, or were created based on them.
Introduction.
Person re-identification, which searches for images of people, is in demand for many purposes, including finding suspects and lost children from security cameras. Among these, text-based person re-identification, which searches for images that show the same person as the input image, but instead searches for images that show a matching person from the text, has attracted a lot of attention. The field is quite hot, with the latest being a paper posted on April 5 ([2304.02278] Calibrating Cross-modal Feature for Text-Based Person Searching (arxiv.org )), which updated SOTA. (as of April 13)
The main approach in text-based person re-identification tasks is to map both image and text modalities into the same latent space. Traditional methods often use separate models for feature extraction, such as Resnet for image encoders and BERT for text encoders, but this approach has two challenges.
- There is no interaction between modalities in separate models. It is difficult to get a model with a huge number of parameters and deep layers to account for interactions simply by using matching losses. (Figure 1a)
- The diversity of texts makes it difficult to match parts. For example, some texts that refer to the same person have descriptions of hairstyles and pants, while others have descriptions of accessories and colors.
This paper approaches the first issue by using the same encoder, and the second issue by focusing on looking more at local semantic matching rather than looking more closely.
The first approach introduces an implicit visual and textual learning (IVT) framework that can learn representations of both modalities using a network (Figure 1b).
As a second approach, we propose two implicit semantic alignment paradigms for fine-grained modality matching: multilevel alignment (MLA) and bidirectional mask modeling (BMM). Specifically, as shown in Figure 1(c), MLA utilizes sentence-, phrase-, and word-level matching to explore fine-grained alignments, while BMM masks a certain percentage of visual and textual tokens to allow the model to mine more useful matching cues. The two proposed paradigms not only allow us to look more finely but also to see more semantic alignments.
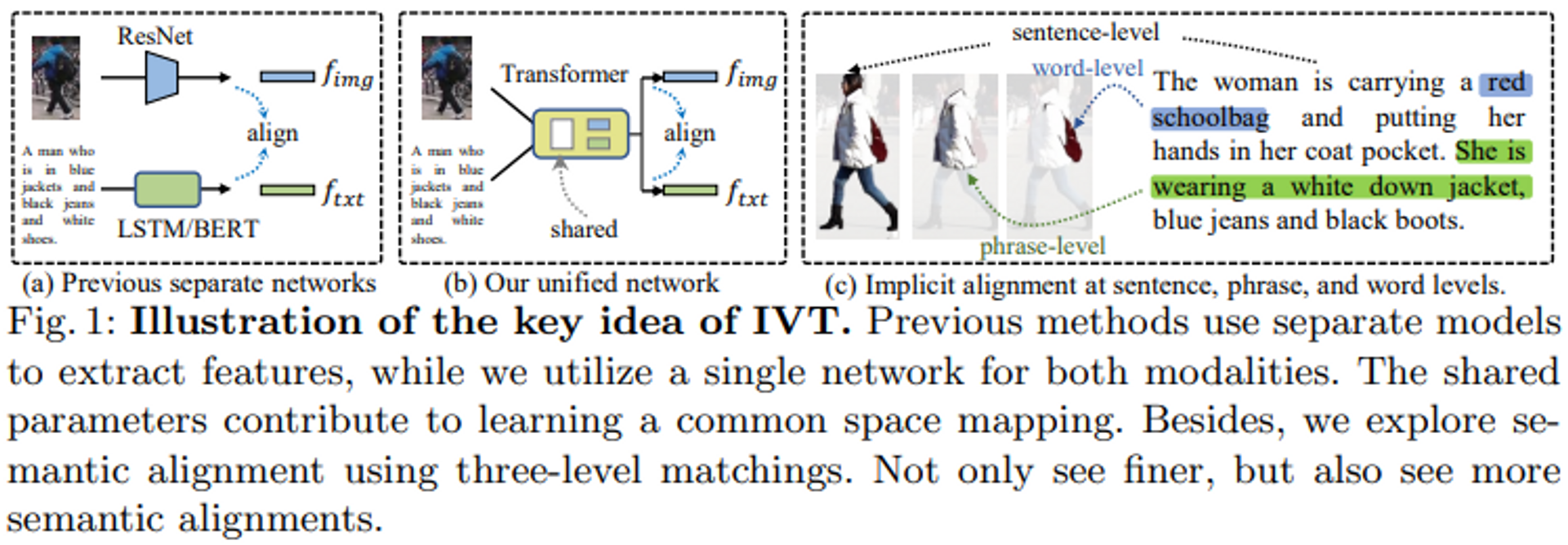
Proposed Method
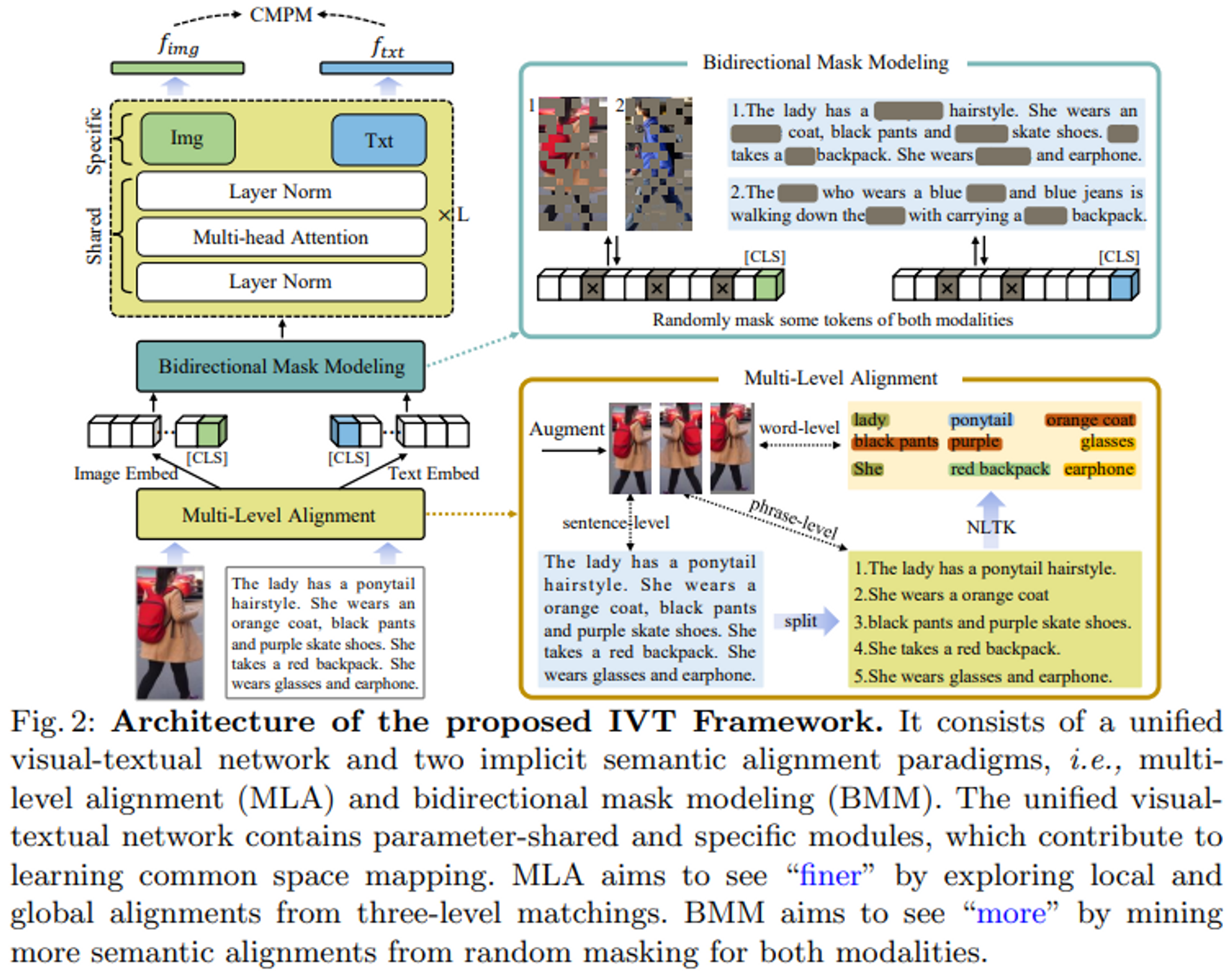
The IVT framework consists of a unified visual-text network and two implicit semantic alignment paradigms: multilevel alignment and bidirectional mask modeling.
One of the key concepts of IVT is to address modality alignment using a unified network. By sharing several modules, such as layer normalization and multi-head attention, the unified network contributes to learning common spatial mappings between visual and textual modalities. Different modules can also be used to learn modality-specific cues.
Two implicit semantic alignment paradigms, MLA and BMM, are proposed to explore fine-grained alignment.
encoder
Most conventional methods utilize separate models for text and image encoders and lack inter-modality interaction. Therefore, this paper proposes to employ a unified image-text network.
As shown in Figure 2, the network follows ViT's standard architecture, stacking L blocks in total. In each block, two modalities share layer normalization (LN) and multi-head self-attention (MSA), which contribute to learning a common spatial mapping between image and text modalities. The shared parameters help in learning common data statistics. For example, the LN will calculate the mean and standard deviation of the input token embedding, and the shared LN will learn the common statistical values for both modalities. This can be viewed as a "modality interaction" from a data-level perspective. Since image and text modalities are different, each block has a modality-specific feed-forward layer, i.e., the "Img" and "Txt" modules in Figure 2, to obtain modality-specific information. The complete processing of each block can be represented as follows
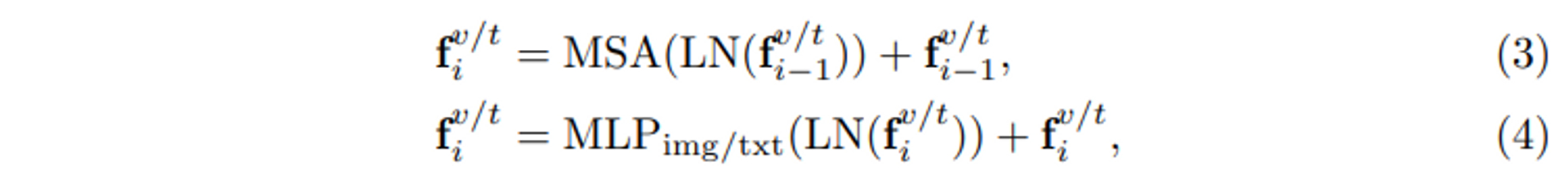
implicit semantic alignment
multilevel alignment
We propose an intuitive yet highly effective implicit positioning method: multi-step positioning.
As shown in Figure 2, the input image is first expanded in three ways, including horizontal flipping and random cropping. The input text is divided by periods or commas into shorter sentences. These shorter sentences are used as "phrase-level" representations describing partial appearance characteristics of the human body. To extract more detail, we use the Natural Language Toolkit (NLTK) to extract nouns and adjectives that describe specific local features such as bags, clothes, pants, etc. Three levels of text description - sentence level, phrase level, and word level - correspond to three types of augmented images; three-level image-text pairs are randomly generated at each iteration. In this way, a progressively refined matching process from global to local can be constructed, allowing the model to adopt a finer semantic alignment.
Bidirectional Mask Modeling
This paper argues that local alignment should not only be finer but also more diverse. Subtle visual and textual cues may complement global alignment. We propose a bi-directional mask modeling (BMM) method for mining more semantic alignments, as shown in Figure 2. A percentage of the image and text tokens are randomly masked to force the visual and text output to match. Typically, the masked tokens correspond to specific patches in the image or words in the text. When a particular patch or word is masked, the model tries to find useful alignment cues from other patches or words. Taking the woman in Figure 2 as an example, if the salient words "orange coat" and "black pants" are masked, the model will focus on other words, such as the ponytail hairstyle or the red backpack. In this way, more subtle visual textual positioning relationships can be explored. While this method makes it more difficult for the model to align images and text during the learning phase, it is useful for exploring more semantic alignments during the inference phase.
loss function
CMPM loss is used as the matching loss. I'll leave the details to Deep Cross-Modal Projection Learning for Image-Text Matching (thecvf.com ), but in brief, text-image embedding matching is done by KL divergence.
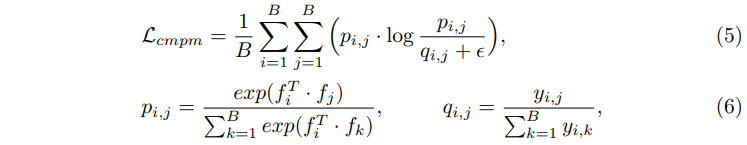
experiment
The proposed method IVT achieves SOTA on three datasets. The evaluation is done with Recall@n (n=1,5,10).
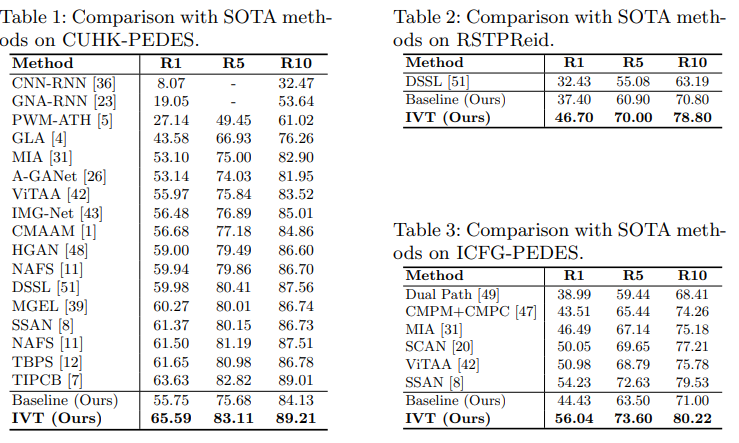
Figure 4 shows a visualization of the decision basis for the baseline and the proposed method IVT. (This is a visualization of the attention map with the [CLS] token.) In general, textual descriptions can correspond to the human body, demonstrating that the model has learned the semantic relevance of visual and textual modalities. Compared to the baseline, the IVT confirms that the model focuses on more attributes of the human body described by the text. For example, the male (row 1, column 1) is wearing gray shorts. While the baseline ignored this attribute, the IVT was able to capture it. Thus, the proposed IVT is more accurate and can handle a wider variety of personal attributes than the baseline method.

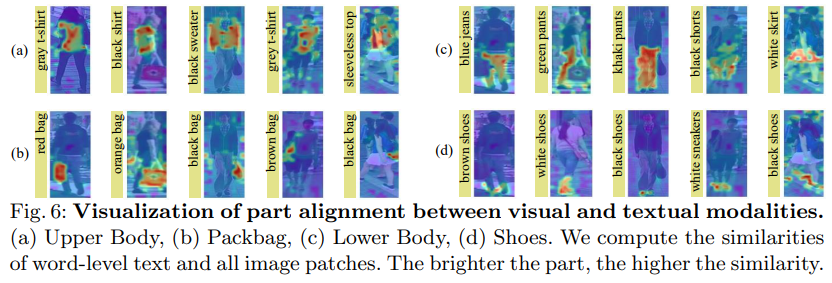
Figure 6 shows the attention to local tokens. Four different personal attributes are given: upper body, bag, lower body, and shoes. Each row in Figure 6 shares the same attributes. Figure 6 shows that our method can recognize not only prominent parts such as clothes and pants, but also subtle parts such as handbags and shoes. These visualization results show that our model can accurately focus on the correct body part given a word-level attribute description. This shows that our approach is capable of exploring fine alignments even without explicit visual and textual part alignment. This is a benefit of the two proposed implicit semantic alignment paradigms, namely MLA and BMM. Therefore, we can conclude that the proposed method can indeed achieve See Finer and See More in text-based person searches.
summary
In this paper, we proposed to address modality alignment from two perspectives: backbone networks and implicit semantic alignment. First, we introduced the Implicit Visual Text (IVT) framework for text-based person retrieval. It uses a single network to learn visual and textual representations. Second, we propose two implicit semantic alignment paradigms, BMM and MLA, to explore fine-grained alignment. These two paradigms can be seen "finer" by using 3-level matching and "more" by mining more semantic alignments Extensive experimental results on three public datasets demonstrate the effectiveness of our proposal (1) the number of semantic alignments in the data set



Categories related to this article






