VGG Is Back!
3 main points
✔️ Simple but powerful VGG-like CNN architecture
✔️ Significantly faster compared to other SOTA models
✔️ Use of structural re-parameterization to convert the training-time multi-branch structure into inference-time plain architecture
RepVGG: Making VGG-style ConvNets Great Again
written by Xiaohan Ding, Xiangyu Zhang, Ningning Ma, Jungong Han, Guiguang Ding, Jian Sun
(Submitted on11 Jan 2021)
Comments: Accepted to arXiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
official
comm
Introduction
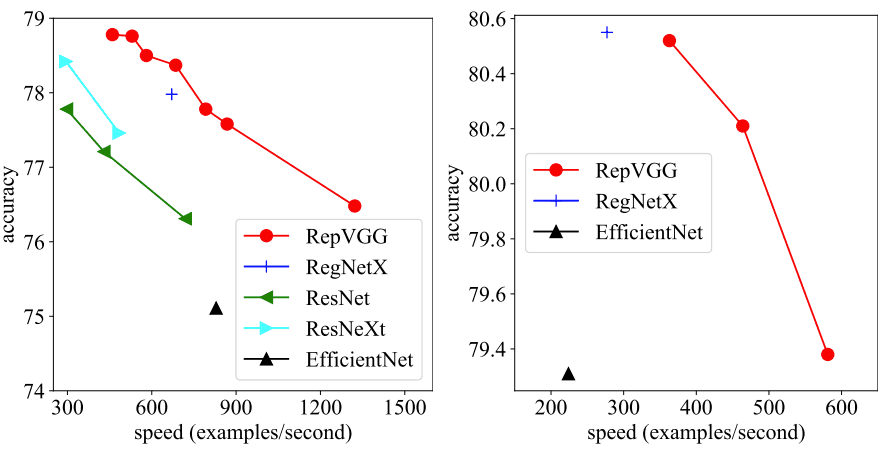
The VGGNet had a relatively simple architecture that has now been succeeded by more complex and powerful models such as ResNets, DenseNets, and EfficientNets. Although these models are more accurate, they are complicated and slower(despite some of them having lower FLOPs). Therefore, VGGs and ResNets are still widely used for real-world applications. This paper presents a new VGG-like architecture with impressive inference speed while having accuracy comparable to state of the art models. As will be described later, this can be achieved by training on a more complicated model and later restructuring the model to a more simple architecture for inference. The objective here is to create a simple and yet fast model that converges very well: RepVGG.
To read more,
Please register with AI-SCHOLAR.
OR


Categories related to this article


![[Swin Transformer] T](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2024/swin_transformer-520x300.png)



