All Good Things Come To An End: Goodbye Batch Normalization!
3 main points
✔️ A replacement for Batch Normalization using a novel adaptive gradient clipping method
✔️ Normalizer-free architectures called NFNets with SOTA performance
✔️ Better training speed and transfer-learning abilities than models using batch normalization
High-Performance Large-Scale Image Recognition Without Normalization
written by Andrew Brock, Soham De, Samuel L. Smith, Karen Simonyan
(Submitted on 11 Feb 2021)
Comments: Accepted to arXiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Machine Learning (stat.ML)




First of all
Many of today's deep learning networks use residual connections along with batch normalization, dropout, and activation functions like ReLU. Batch Normalization is a fairly new concept but has found its use in almost all deep learning tasks. It has been shown that they smoothen the loss surface and have a regularization effect on the network, allowing it to be trained in larger batches.
In spite of the performance improvements, batch normalization also has its downsides. It is a rather expensive operation and even worse, it breaks the independence between training examples. There might also be a discrepancy between model performance during inference and training, making it necessary to train additional hyperparameters. Therefore, it is doubtful whether batch normalization will continue to assist future models and appropriate to think whether it will instead have a detrimental effect.
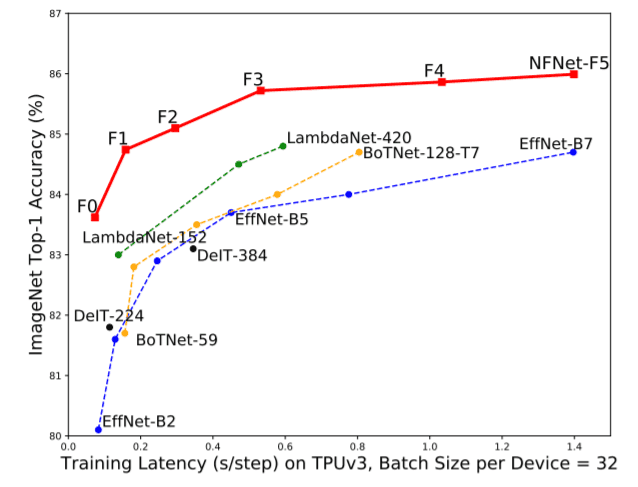
This paper introduces Adaptive Gradient Clipping(AGC), which is primarily based on the unit-wise ratio of gradient norms to parameter norms. AGC is used to create NFNets, a family of DNNs that do not use normalization but are able to obtain state of the art accuracies on the ImageNet benchmark. The NFNet-F1 which has accuracy comparable to EfficientNet-B7 is 8.5x faster to train. After pre-training on 300 million images and then fine-tuning on ImageNet, NFNets have better validation accuracy than models that use BN(89.5% top-1 for best model).
How does batch normalization help?
Given the upsides and downsides of BN, we want to develop technique(s) that eliminates the downsides while retaining the good features. Let us now look at what we need to retain.
Downscaling of residual branch
BN reduces the scale of hidden activations in the residual branch. So it prevents the gradients from becoming unstable earlier in training.
Mean-Shift elimination
Activation functions like ReLU have non-zero mean activations. The dot product of activations of independent training instances is larger even if the dot product of inputs is close to 0, and this problem worsens with increasing depth. BN makes the mean activation on each channel 0 and eliminates mean-shift at each step.
Regularization effect
The statistics computed on the mini-batches introduces some noise and enhances test accuracy.
Allows efficient large-batch training
BN smoothens the loss surface and allows to train with larger stable learning rates, larger batch sizes and fewer weight updates.
Removing Batch Normalization
This paper builds on 'Normalizer-Free ResNets' called NF-ResNets. NF-ResNets use the residual block:
hi+1 = hi + αfi(hi/βi)
hi denotes the input to the ith residual block. Note that fi preserves the variance i.e. Var(fi(z)) = Var(z). βi = sqrt(Var(hi)) is the standard deviation of the input to the ith residual block. α(usually 0.2) defines the rate of increase of variance at each step i.e Var(hi+1) =Var(hi)+α2. Just like BN, this residual block has the positive effect of scaled activations and makes the gradients more stable. In order to prevent mean-shift NF-ResNets use Scaled Weight Standardization given by(N is the fan-in):

In addition to this, the activation function(ReLU, GELU) is scaled by scalar γ specific to the activation function. For ReLU, γ = sqrt[2/(1 − (1/pi))]. This has the effect of reverting back the variance that was changed by the scaled weight standardization layer. In addition, NF-ResNets also make use of Dropout and Stochastic Depth as regularizers.
NF-ResNets are competitive with batch-normalized ResNets on ImageNet with up to 4096 batch size. However, performance degrades for batch sizes higher than 4096. More importantly, their performance is not as good as EfficientNets.
Creating better NF-ResNets
In order to be able to train NF-ResNets at higher batch sizes, gradient clipping was tried at first. Gradient clipping works by substituting the gradient values outside a permitted range.

However, it was found that the parameter λ was unstable and had to be tuned for any changes in batch size, model depth, or learning rate. To solve that problem, we proposed
Adaptive Gradient Clipping (AGC)
The ratio of the norm of the gradient to the norm of the weight vector gives an idea of how much the weights will change. A larger ratio suggests that the training is unstable and gradients need to be clipped. Instead of calculating the norm for the weight and gradient matrix of one layer in one go, we calculate the unit-wise(row-wise) ratio and using that information we clip the gradients unit-wise(row-wise). Mathematically, the AGC for the i-th row of the weight of layer ℓ is given by,

Ablation Studies
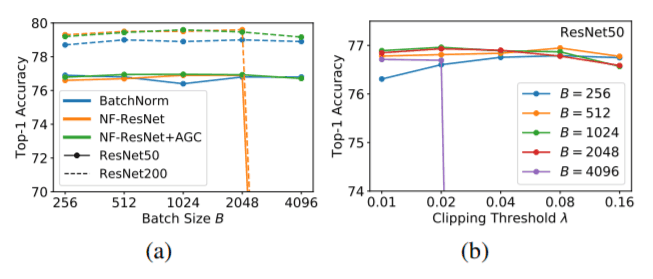
Through a series of ablation studies, it was found that NF-ResNet with AGC performs much better than NF-ResNet alone at higher batch sizes. It was also found that a smaller clipping threshold(<0.02) is necessary to train at higher batch sizes. Using AGC in all four ResNet block groups was found to be effective. On the contrary, applying AGC to the final linear layer led to a deteriorated performance.
Normalizer-Free Model Architecture: NFNets 
NF-Net Transition Block(left) and NF-Net Non-Transition Block(right)
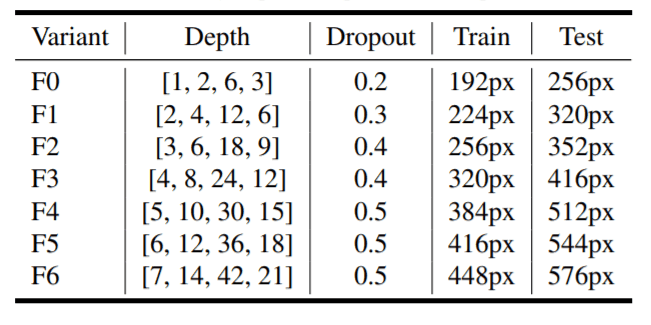 Different Variants of NF-Net with depth, dropout, and image resolutions.
Different Variants of NF-Net with depth, dropout, and image resolutions.
SF-Nets can be built by slight modifications to the SE-ResNeXt models with GELU activation. As mentioned earlier, all GELU activations in SE-ResNeXt are scaled with a scalar γ to preserve the variance. Also, all weights except the last linear layer make use of AGC.
There is an initial stem with three 3x3 convs layers(two of stride 2 and one of stride 1) which downsamples the images into a feature map with 128 channels. The next four stages each have a different number of blocks depending on the variants(F0~F6). The first block in each variant is a transition block as shown in the top-left figure and the rest of the blocks are non-transition blocks. The transition block downsamples the feature map and increases the number of channels.
Each block consists of a 1x1 convolution that reduces the number of channels to 0.5 times the number of output channels for the block. This is followed by two 3x3 convs with a constant group width of 128. Finally, a 1x1 convolution increases the no. of channels to double(i.e equal to the no. of output channels of the block)
Experiment and Evaluation
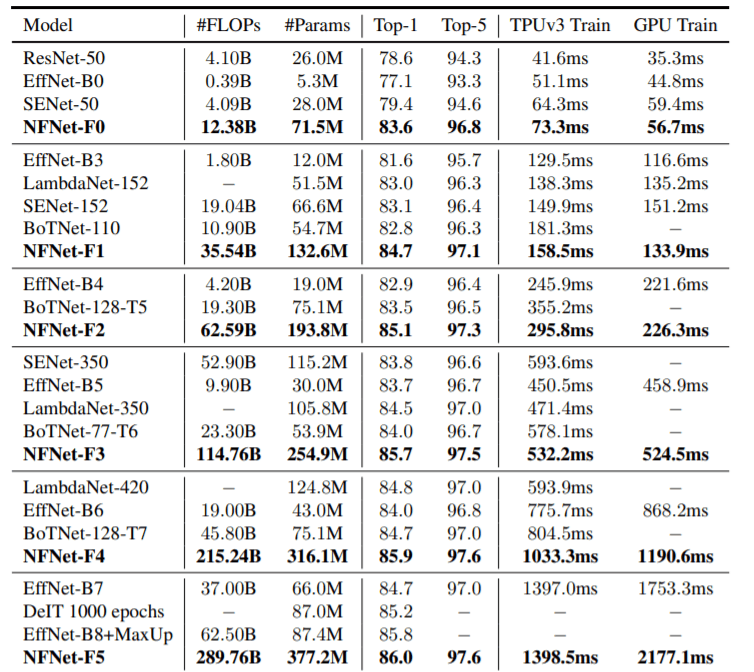
Comparison of NF-Net and SOTA models on ImageNet
TThe above table shows comparisons of NFNets and other current state of the art models in terms of accuracy on ImageNet, model size(FLOPs and Params), and GPU&TPU training time(single step).NFNet-F5 attains an accuracy of 86.0 but has a large number of parameters and FLOPs. The results of EfficientNet-B7 are comparable to NFNet-F1 which trains 8.7 times faster with slightly fewer FLOPs.
![]()
ImageNet Accuracy after pre-training.
ResNets with BN and NF-ResNets without BN were taken and pre-trained on 300 million images. The results obtained after they were fine-tuned on ImageNet is shown in the table above. In almost all cases Normalizer-Free models outperform BN-ResNets showing that removing BN can help transfer-learning tasks.
Conclusion
It was interesting to see that BN-free models can match and even outperform models using BN in Image Recognition tasks. The models preserved the good features of BN and some were quite faster to train. However, the paper does not explore if Normalizer-free models work equally well for NLP tasks, or even other vision tasks like instance segmentation, object detection. These would be interesting topics for future research works. For further information please refer to the original paper.
Easy to understand video explanation! I recommend you to subscribe to our channel.



Categories related to this article


![[Swin Transformer] T](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2024/swin_transformer-520x300.png)



