[Video Recognition] Supervised Learning Using YouTube! New Video Recognition Framework OmniSource!
3 main points
✔️ New video recognition framework OmniSource achieves SOTA
✔️ Supervised Learning using images and videos from the web such as Instagram and YouTube
✔️ Joint Training overcomes differences between data formats such as images, short videos, and long uncropped videos
Omni-sourced Webly-supervised Learning for Video Recognition
written by Haodong Duan, Yue Zhao, Yuanjun Xiong, Wentao Liu, Dahua Lin
(Submitted on 29 Mar 2020 (v1), last revised 25 Aug 2020 (this version, v2))
Comments: Accepted to ECCV2020.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
official
comm
outline
This paper, accepted for ECCV2020, proposes a novel framework for video recognition, OmniSource. It overcomes the differences between data formats of various data on the Web (e.g., images, short videos, and long untrimmed videos) and achieves highly accurate video recognition through Web-supervised learning.
First, task-specific data is collected and the TEACHER MODEL transforms the data with multiple formats into a single format. Next, a method called joint training is proposed to address the domain gap between multiple data sources and formats. Joint training employs techniques such as data balancing, resampling, and cross-dataset mixup.
Experiments show that OmniSource is data-efficient in training by using data from multiple data sources and formats. With only 3.5 million images and 800,000 minutes of video crawled from the Internet without human labeling (less than 2% of the previous study), OmniSource-trained models outperformed the 2D and 3D-ConvNet baseline models on the Kinetics-400 benchmark by 3.0%. OmniSource has also achieved SOTA with this and other pre-training.
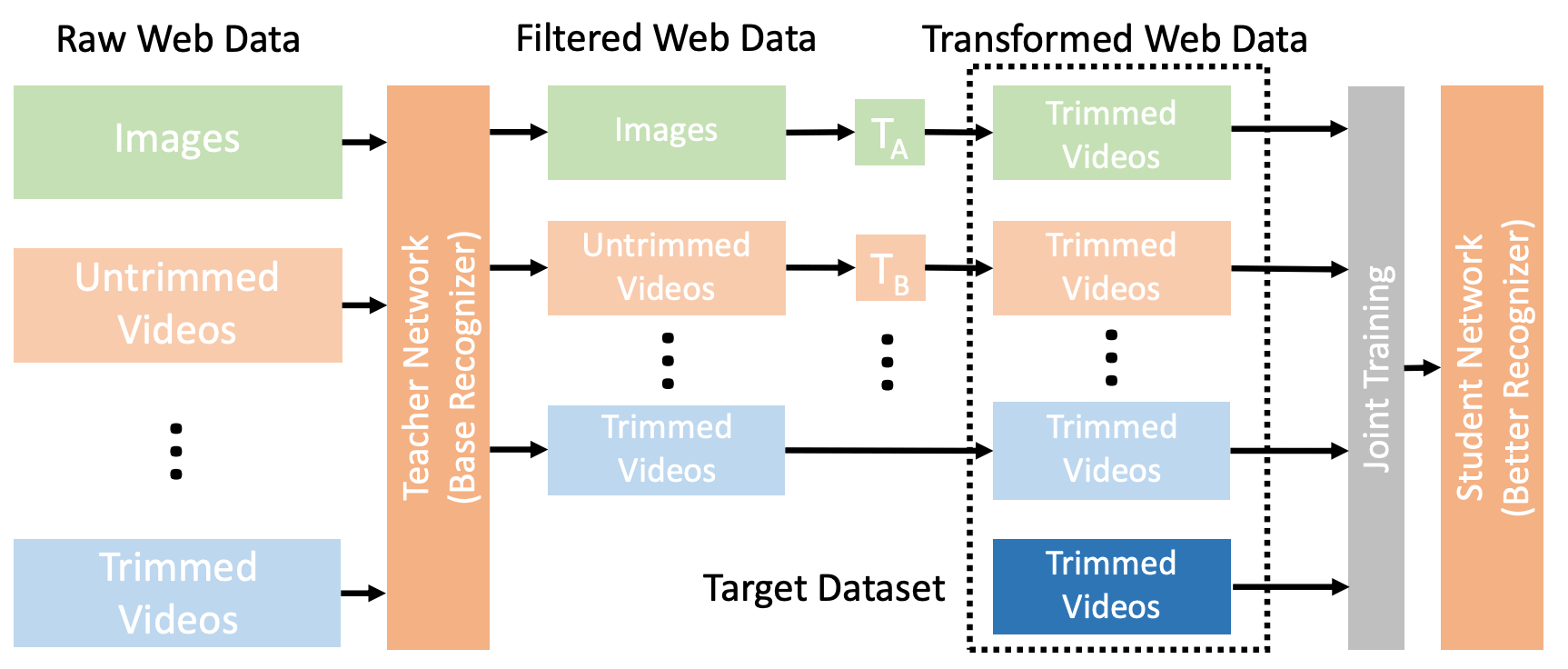
The above figure shows the conceptual diagram of OmniSource. First, we train a teacher network on the dataset of interest. The teacher network is then used to extract various collected web data to reduce noise and improve the quality of the data. We also perform special transformations on the extracted data for each format. Joint Training of the teacher network is performed using the target and supplementary web datasets.
To read more,
Please register with AI-SCHOLAR.
OR


Categories related to this article


![[Swin Transformer] T](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2024/swin_transformer-520x300.png)



