![MMSEARCH] Multimodal Search System Integrating Image And Text](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2024/mmsearch_1_.png)
MMSEARCH] Multimodal Search System Integrating Image And Text
3 main points
✔️ MMSEARCH-ENGINE proposes a multimodal search system that integrates image and text retrieval
✔️ Experiments show GPT-4o has superior retrieval accuracy, surpassing traditional search engines
✔️ Improvements in Requery and Rerank tasks are key to further performance gains
MMSearch: Benchmarking the Potential of Large Models as Multi-modal Search Engines
written by Dongzhi Jiang, Renrui Zhang, Ziyu Guo, Yanmin Wu, Jiayi Lei, Pengshuo Qiu, Pan Lu, Zehui Chen, Guanglu Song, Peng Gao, Yu Liu, Chunyuan Li, Hongsheng Li
(Submitted on 19 Sep 2024)
Comments: Project Page: this https URL
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Information Retrieval (cs.IR)
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
Background
Conventional search engines deal primarily with text only, making it difficult to adequately search for and process information that combines images and text. For example, it is common for websites to display complex intersections of images and text, but current AI search engines are not able to process such content efficiently.
To address this issue, researchers have developed a system called MMSEARCH-ENGINE. This system is a mechanism to provide a multimodal search function that can be applied to any LMM. This will allow LMMs to respond to more complex search requests, utilizing image information as well as mere text search. The actual process of web search requires a series of steps that involve converting user questions into a format more suitable for search engines, re-evaluating and re-ranking the search results obtained, and finally presenting that information in a summarized form.
The system leaves all its steps to the LMM, which ultimately aims to provide more accurate and relevant information.
Proposed Method
The method proposed in this paper is MMSEARCH-ENGINE, which is specific to LMM as a multimodal search engine.
MMSEARCH-ENGINE is a framework developed to add multimodal search capabilities to LMM that can process both image and text information simultaneously. The system begins with the step of reconverting (Requery) the user's query (search request) into the appropriate format. In many cases, the query entered by the user may not be suitable for search engines, so LMMs optimizes the query. Next, the most relevant websites from the resulting search results are re-ranked (Rerank), and finally, a summary (Summarization) is performed based on that information.
This MMSEARCH-ENGINE has the ability to integrate and process visual and textual information, specifically, by using Google Lens to extract information from images and by taking screenshots of websites and passing them to the LMM, which also searches for visual cues process. This allows for more accurate search results based on the content of the images, even if the user's query includes images.
In addition, a benchmark, MMSEARCH, has been established to evaluate this methodology. It measures the multimodal search capabilities of LMMs using 300 manually collected queries. The queries span current news and professional knowledge areas, and each query contains a complex mix of image and textual information.
Experiment
The experiments in this paper are evaluated using several large-scale multimodal models (LMMs) to validate the proposed MMSEARCH-ENGINE. The experiments measure the performance of the proposed method using closed LMMs (e.g., GPT-4V and Claude 3.5 Sonnet) and open source LMMs (e.g., Qwen2-VL-7B and LLaVA-OneVision).
The experiment involves three main core tasks. They are Requery, Rerank, and Summarization. First, the Requery task converts the user's query into a format suitable for search engines, followed by the Rerank task, which selects the most relevant ones based on the information obtained from several websites. Finally, a Summarization task is performed to extract the appropriate answers from the selected information.
In addition to these three tasks, an "end-to-end" evaluation was also conducted, which takes place throughout all steps. This end-to-end task measures how accurately the entire system delivers results to a user's query, simulating a scenario that most closely resembles real-world use.
As a result, GPT-4o performed best among the closed-source LMMs, while the open-source Qwen2-VL-72B also showed excellent results. Of particular interest is the fact that the proposed method outperformed Perplexity Pro, a commercial AI search engine. This demonstrates that MMSEARCH-ENGINE has superior multimodal search capabilities compared to existing systems.
The results of the experiment also highlighted the models' weaknesses in the Requery and Rerank portions, indicating that improvements are needed in these tasks, especially for the open source models. On the other hand, many models performed relatively well on the Summarization task, confirming their strong ability to summarize the extracted information.
Conclusion
The conclusions of this paper demonstrate that the proposed MMSEARCH-ENGINE is very promising in current multimodal search. The use of large-scale multimodal models (LMMs) confirms its ability to effectively handle complex queries that include images as well as text.
Another drawback of the proposed method is that current LMMs do not have sufficient accuracy in Requery and Rerank tasks. Improving performance in these tasks is a future challenge, and with further improvement, the performance of LMM in multimodal search will be dramatically improved.
Explanation of Figures and Tables

This figure shows the multidisciplinary questions and their answers, and provides an example of how to evaluate the functionality of the MMSearch system.
The figure shows questions primarily related to news and knowledge, broken down by category. First, news-related questions are divided into six categories: Finance, Sports, Science, Entertainment, General, and False Assumptions. Within each category, examples of specific questions and their answers are provided. For example, in the "Finance" section, a question is asked regarding a company's stock price.
Next, the section on knowledge is divided into six categories: astronomy, automobiles, fashion, art, architecture, and animation. In this section, the "Fashion" section asks for the release date of the clothing.
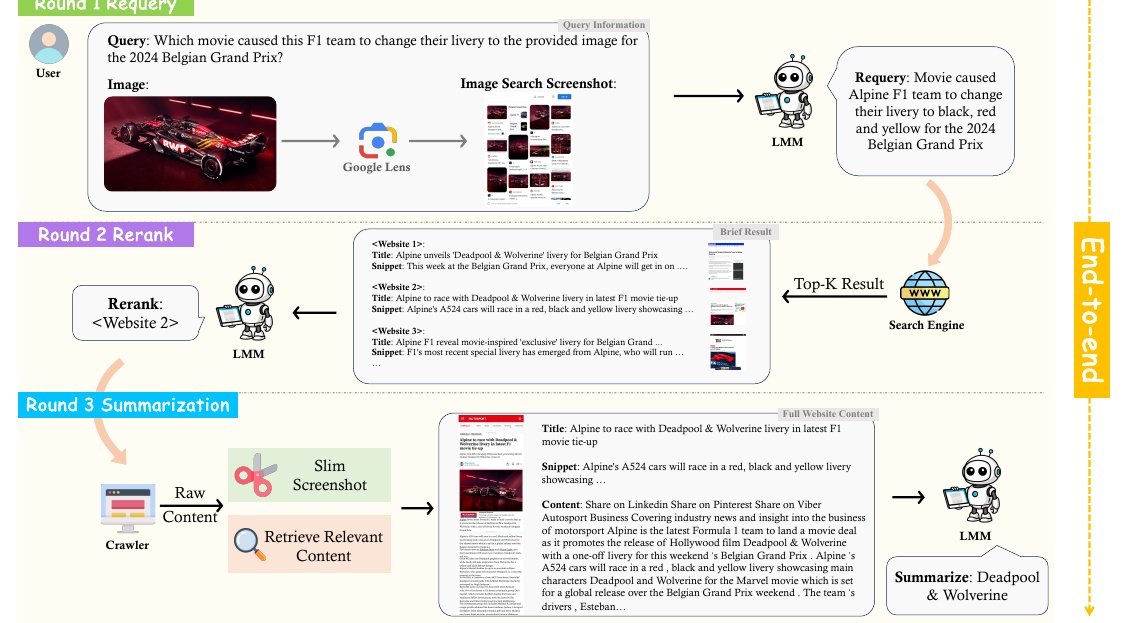
This diagram shows the procedure for retrieving information about F1 team rebadging changes. The contents are as follows
First, the user asks, "What film caused the F1 team to change the libary provided in this image for the 2024 Belgian Grand Prix?" The question is asked. The user uses the relevant image, which is then searched through Google Lens to retrieve the relevant information.
In the next step, "Requery" (Request Reconstruction), the LMM (Large Multimodal Model) creates a new search query in the search engine based on the images and the information retrieved, "Movies that changed the liveries to black, red, and yellow for the 2024 Belgian Grand Prix". The most relevant websites are then listed by the search engine as the top k
In the "Rerank" step, the LMM selects from the listed websites the one that provides the best information. In this example, "Website 2" is selected.
Finally, in the "Summarization" step, LMM analyzes the details of the selected websites and summarizes that the movie "Deadpool & Wolverine" caused the reverie change.
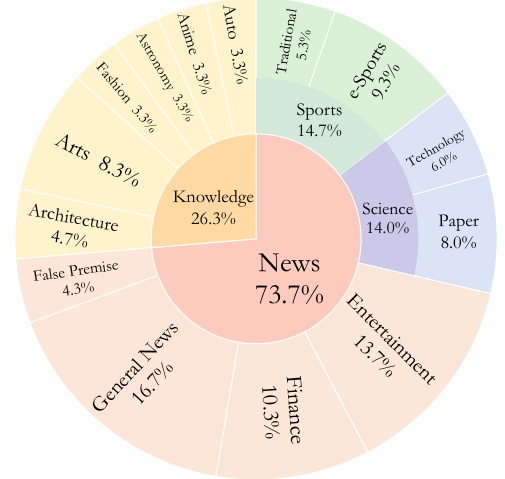
This figure shows the percentage of categories and subcategories in the MMSEARCH dataset that the paper evaluates. 73.7% of the total belong to the "News" category and 26.3% to the "Knowledge" category.
The "News" category is broken down in more detail, with "General News" accounting for 16.7% and "Sports" at 14.7% and including both traditional and eSports. Entertainment," at 13.7%, is a topic of interest to many. In addition, "Finance," at 10.3%, includes a lot of information about the economy. Science" and "Technology" are also rich in science and technology news, at 14.0% and 6.0% respectively. Paper, at 8.0%, also contains academic information.
In the "Knowledge" category, "Arts" and "Architecture" account for 8.3% and 4.7%, respectively, covering specific knowledge about art and architecture. False Premise, at 4.3%, covers questions involving false premises. Astronomy," "Anime," "Auto," and "Fashion" each account for 3.3% and examine knowledge in these areas.
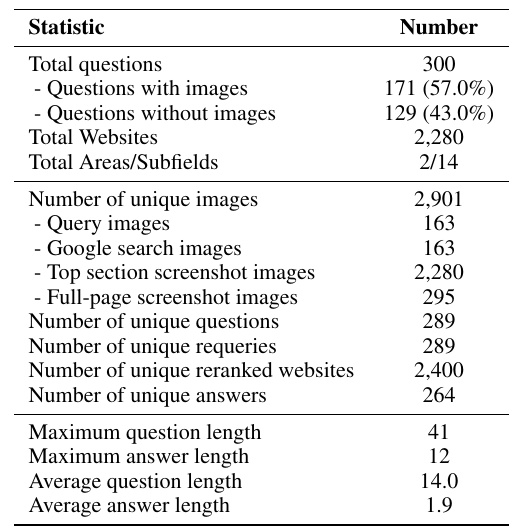
This table shows the statistics of the data set in a study. In all, 300 questions are included, of which 171 have images and 129 are text-only questions. The number of websites associated with each question amounts to 2,280. In addition, the dataset is divided into 14 areas, but is focused on two main areas.
There are 2,901 unique images, including 163 used in queries, 163 resulting from Google searches, and 2,280 screenshots of the top section of the website. In addition, there are 295 screenshots of the entire web page.
There are 289 unique questions and 289 unique re-queries as well. There are 2,400 reranked websites, with 264 unique answers. The maximum question length is 41 words and the maximum answer length is 12 words. The average question length is 14 words and the average answer length is 1.9 words.

This figure provides an overview of the dataset associated with the paper. First, the total number of questions is 300, of which 57% are with images and 43% are without images. 2,280 websites were used. The data is divided into two broad areas, each consisting of 14 subfields: news and knowledge. News accounts for 73.7% of the data and includes general news, entertainment, sports, wallets, science and technology, and more. Knowledge accounts for 26.3%.
As for images, there are a total of 2,901 unique images, of which 163 are query images and 163 are Google search images. There are also 2,280 top section screenshots of the website with 2,280 content and 295 full page screenshots. The number of unique questions is 289, unique re-queries (queries) is also 289, and the number of unique re-ranked websites is 2,400. There are 264 unique answers available.
The maximum length of a question text is 41 words and the maximum length of an answer is 12 characters. On average, questions are 14.0 words long and answers are 1.9 characters long. A variety of news and knowledge questions have been studied based on this data.

This chart describes each of the four different tasks (requery, re-rank, summary, and end-to-end). Specifically, it shows the correspondence between the input content, Large Multimodal Model (LMM) output, and the correct answer (Ground Truth) for each task.
1. requery
- Input: Data called "query information" is used.
- LMM output: The model yields a newly reworked "LMM requery".
- Correct: The correct answer to the requery is shown as a "requery annotation.
2. reerank: a.
- Input: "query information" and "simplified results" are used. This determines which information is important.
- LMM Output: The model outputs "LMM reranks" to pick out the most important information.
- Correct: The correct ranking is noted in the "Re-rank Annotation".
Summarization: The process of summarizing the data in a single document.
- Input: "query information" and "complete website content" will be provided.
- LMM Output: The model summarizes against the query as an "LMM Answer".
- Correct: The "Answer Note" provides an accurate summary.
4. end-to-end
- Input: "query information" is used to indicate the flow, which includes a series of processes (re-query, re-rank, summary).
- LMM Output: The "LMM Answer" obtained throughout the entire process appears as the final product.
- Correct: An "answer annotation" is provided as a result of the entire end-to-end process.
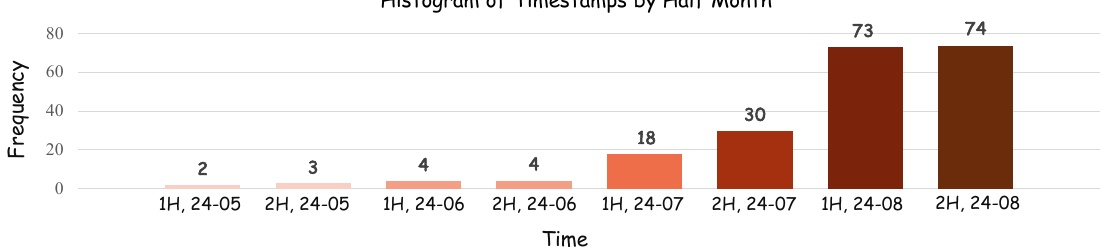
This figure is a histogram showing the frequency of the data, separated by semi-monthly intervals of when the data occurred. The horizontal axis represents time (year-month) and the vertical axis represents frequency. The figure shows that data from May to August 2024 is included, with the frequency of data particularly high in August.
The labels 1H and 2H indicate the semi-monthly divisions and visually show the amount of data generated in each period. In particular, the second half of August 2024 is the highest, and it can be read that data collection is concentrated in this period.

This diagram illustrates the process used to determine the date and time of the cancellation of NASA's VIPER lunar exploration program. The diagram is divided into three steps.
Re-query (Task1 Requery): 1.
- My first question was, "On what date in 2024 was the lunar exploration program shown in this image announced as cancelled?" The first question was, "On what date in 2024 was the lunar exploration program shown in this image announced to be cancelled?
- The LMM (Large Scale Language Model) proposed the re-query "VIPER was announced to be cancelled". This is the stage where the question is re-constructed to obtain accurate information.
Task2 Rerank
- It shows potential websites retrieved from search engines based on the re-query.
- For example, it includes snippets of official NASA announcements and related news articles.
- LMM has chosen <Website 2> as the most useful source of information. This step is to determine which resource provides the most information.
Summarization (Task 3 Summarization)
- Detailed information on the selected websites will be analyzed to arrive at a final answer.
- The figure shows that the answer "July 17" was obtained. This answer indicates the date when the exploration program was discontinued.
Through this process, we see that LMM has the ability to extract accurate information using images and online information.
This figure shows the performance of the multimodal model (LMM) in an end-to-end task. In the figure, the LMM's determination of July 17 and "07-17" as the correct annotation of the answer are presented side by side.
The LMM answer "July 17" is shown at the top of the figure, and "07-17" is presented at the bottom as an annotation to the answer. These are intended to assess the model's ability to correctly derive the answer based on the given information.
This information indicates how accurately the model is able to answer the question. Thus, we can understand the performance of the model by looking at how the answers generated by the LMM compare to the annotations of the correct answers.
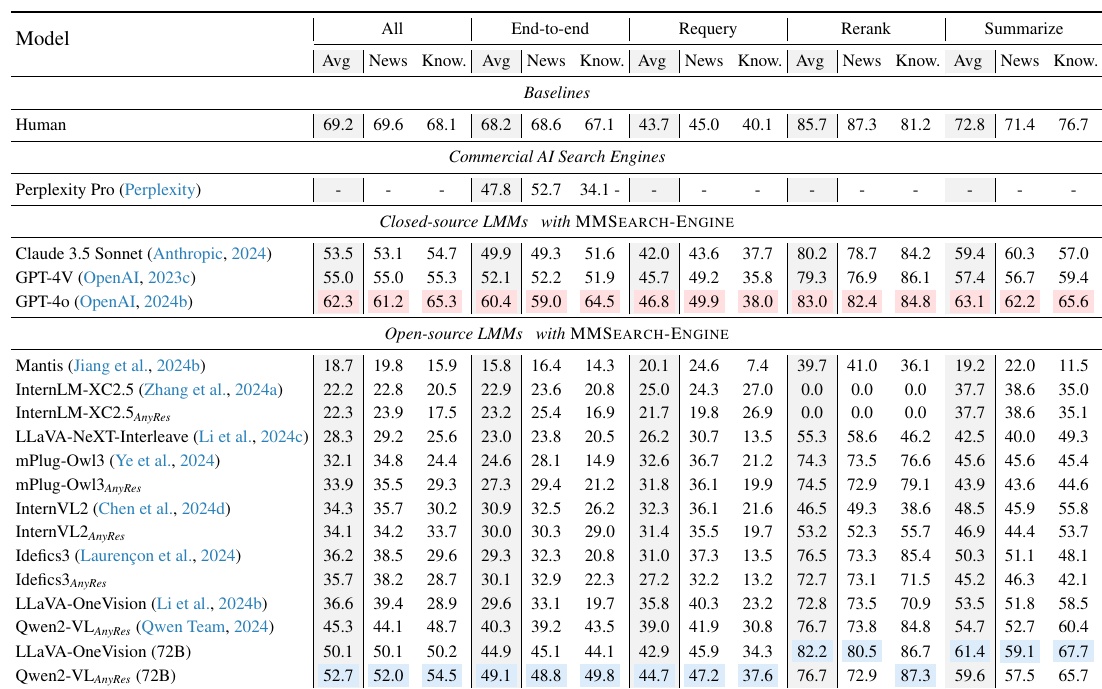
This chart shows how well different large-scale multimodal models (LMMs) perform on "MMSEARCH-ENGINE". The evaluation is divided into four main tasks: End-to-end, Requery, Rerank, and Summarize.
- Row and column organization: each row represents a different LMM, and each column represents a specific evaluation measure in the task (average score, score in the news domain, score in the knowledge domain).
- Model comparison: There are two major categories: "Closed-source LMMs" and "Open-source LMMs. In "Closed-source LMMs," GPT-4o has the highest score. On the other hand, for "Open-source LMMs," Qwen2-VL shows relatively high performance.
- Distribution of scores: The performance of each model varies considerably from task to task. For example, GPT-4o in the "End-to-end" task has a score of 64.5, the highest score in this task. It also shows high results in the "Rerank" task.
- Human Criteria: Human scores are also shown as a basis for comparison. Overall, the human scores are the highest, although there are some instances where the machine comes close for some tasks.
This chart is an indicator of how well a large multimodal model can perform multifaceted tasks and helps to understand the improvements and strengths of the model.

This figure shows the types of model errors in the search engine. The pie chart on the left shows the types of errors in the re-search process, and the pie chart on the right shows the types of errors in the summarization process.
Re-search error type:
- Irrelevant: 27.6% of the time, indicating that the re-search query is inappropriate.
- Lacking Specificity: 24.1% of errors are due to lack of query detail.
- Inefficient Query: 20.7%, due to queries not optimized for search engines.
- Excluding Image Search Results: This is also 20.7%, with image information missing from the query.
- No Change:6.9%, the query is used as is.
Summary Error Type:
- Text Reasoning Error: 53.0%, mainly failure to reason from text.
- Informal (format incompatibility): 24.2%, indicating that the output is not suitable for the format.
- Image-text Aggregation Error: 10.6% did not properly integrate image and text information.
- Image Reasoning Error: 9.1%, there is a problem with reasoning from images.
- Hallucination: 3.0% and contains information not based on reality.
This diagram highlights specific challenges, particularly in the process of generating model responses to user questions.
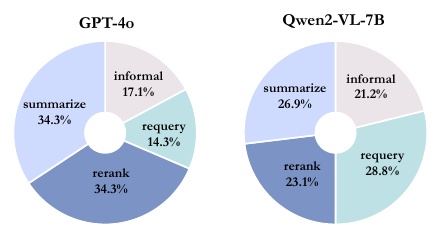
This figure shows the breakdown of errors for two different models GPT-4o and Qwen2-VL-7B. Each pie chart visually shows what type of error each model committed and by how much.
On the left is a breakdown of GPT-4o errors. Summarize" and "rerank" errors account for a large percentage, 34.3% each. Informal" errors accounted for 17.1%, and "rerank" errors 14.3%. This suggests that there is room for improvement, especially in the summarization and re-ranking tasks.
The right-hand side shows the error breakdown for Qwen2-VL-7B, with "requery" errors being the most common, accounting for 28.8%. Errors in "summarize" account for 26.9%, "informal" errors 21.2%, and "rerank" errors 23.1%. We see that errors related to rerank are particularly prevalent in this model. Although there are some structural differences, we can see that errors occur in multiple work steps in both models.
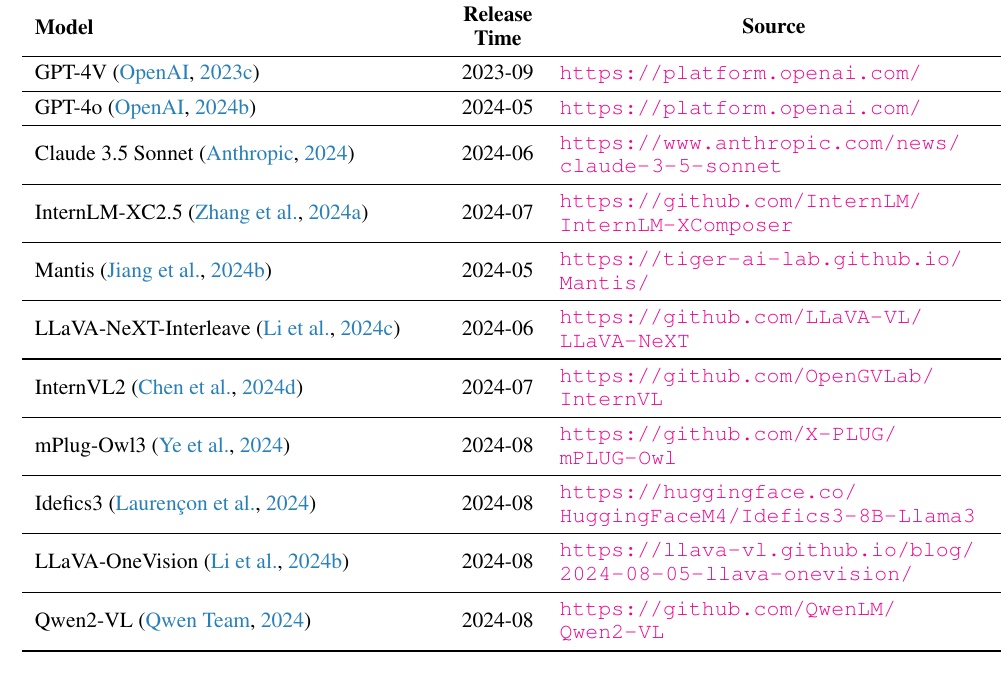
This table organizes information on several large-scale multimodal models (LMMs). The name of each model, the release date, and a link to the source are provided. Specifically, sources such as OpenAI, Anthropic, and multiple GitHub repositories are lined up to help you keep up with the latest research and development.
On the left side of the table, the model names are listed and include links to their respective developers and related papers. These links provide direct access for those wishing to obtain further information. The right-hand column also lists the release date, allowing you to compare when each model was released to the public.

This chart shows the answer to the question, "How many teams were in Group Ascend during the LPL 2024 summer season?" The answer is "9 teams.
The top of the figure shows the question and its answer, indicating that the information is part of sports news.
Next, the center portion of the figure shows examples of three different queries the model made to the search engine. Here, GPT-4o, Qwen-VL, and LLaVA-OneVision each generate similar queries, trying to find information.
Below that is the Brief Results section, which lists titles and snippets of information retrieved from various websites. This provides an example of how the model sorts the most relevant results.
Finally, at the bottom of the figure, the website chosen by GPT-4o is shown, which is indicated to be the "Wikipedia" page.

This diagram shows how different search engines display search results for a website for the same query.
First, the section at the top labeled "Round2 Rerank" shows a summary of several websites retrieved based on a particular query. Here, the title and a snippet (brief description) of each website is listed, giving an overview of their respective content. For example, sites include information about "LPL 2024 Summer - Group Stage," which describes the league's groupings and match formats.
The center portion of the figure shows an example of a website selected by "Qwen2-VL". The model evaluates search results and selects sites that contain the best information.
The "LLaVA-OneVision Brief Results" at the bottom presents results for the same query generated by another search engine.
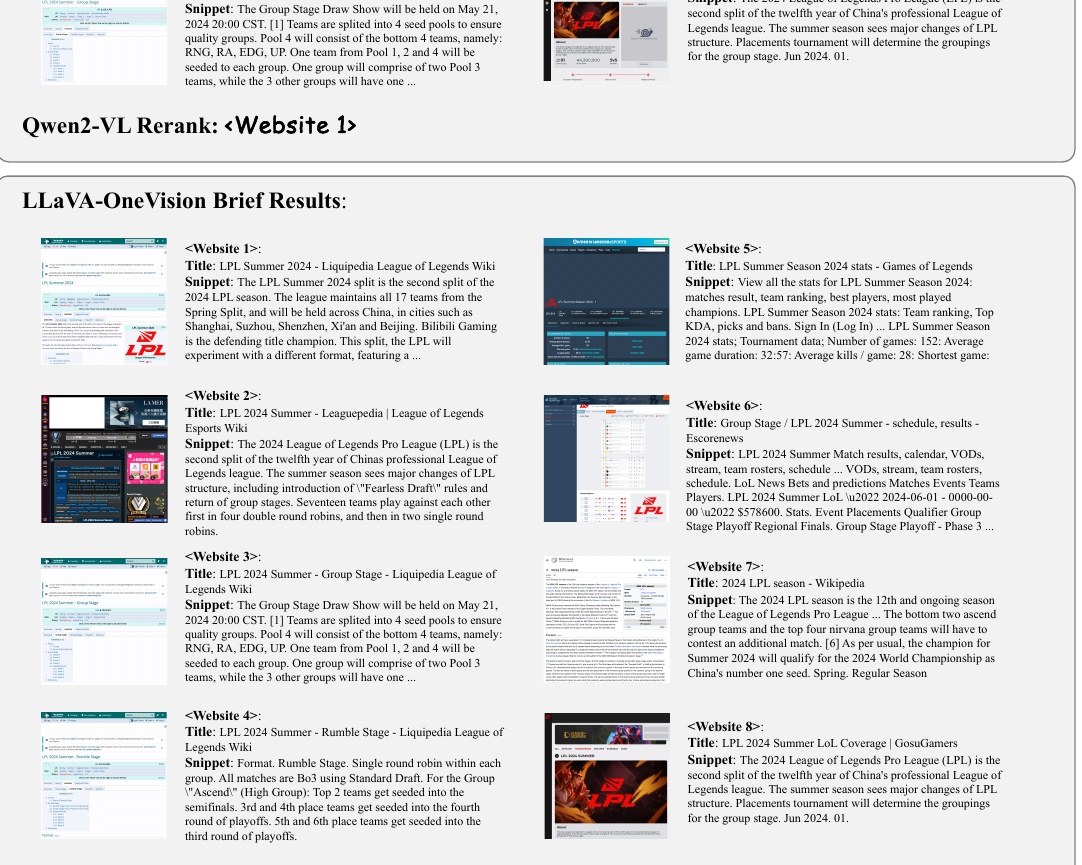
This chart shows information gathered from several websites. Each website contains information about the 2024 League of Legends Professional League (LPL) summer season. Specifically, the websites deal with match results, team standings, and viewing-related information, and include details about the LPL's match format and participating teams.
In the diagram, summaries and headings from several sites are listed, for example, "LPL 2024 Summer - Liquipedia League of Legends Wiki". Each site covers a different aspect of the LPL summer season, but they all have in common a description of the teams, the structure of the matches, and the latest match results.
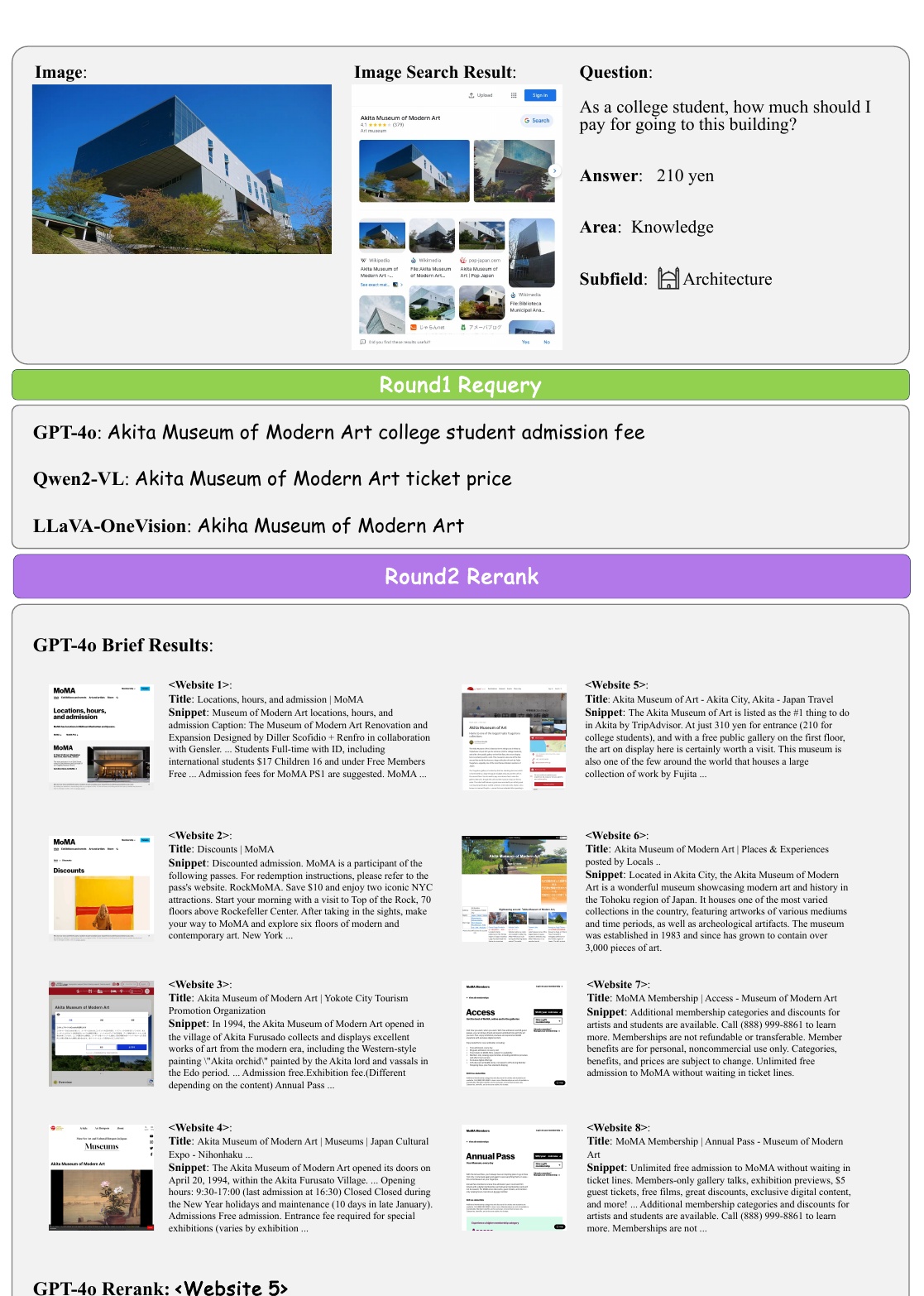
This figure illustrates the process a university student goes through to find out the cost of admission to the Akita Museum of Modern Art. The image search results are used to illustrate the process of finding the appropriate information.
First, an image showing the exterior of the Akita Museum of Modern Art and its image search results are shown. Next, the question "How much should college students pay to enter this building?" This shows the intention of the visitors to gain knowledge about the admission fee of this building.
Based on the image search results, the AI models enter different questions into the search engine. GPT-4o and Qwen2-VL use somewhat different approaches to find information, such as "admission fee for college students" and "ticket price," respectively.
Finally, "GPT-4o" determined that "Website 5" was the most relevant, and based on its content, "¥210" is presented as the correct admission fee.

This image shows the exterior of the building, and the search results indicate that the museum is called "Akita Museum of Modern Art". The question asks how much it costs to enter this building as a college student, and the answer is "210 yen. This information is related to the field of "architecture," which is one of the most important areas of knowledge. The information exhibited is intended to identify specific locations and costs by utilizing images and their search results.
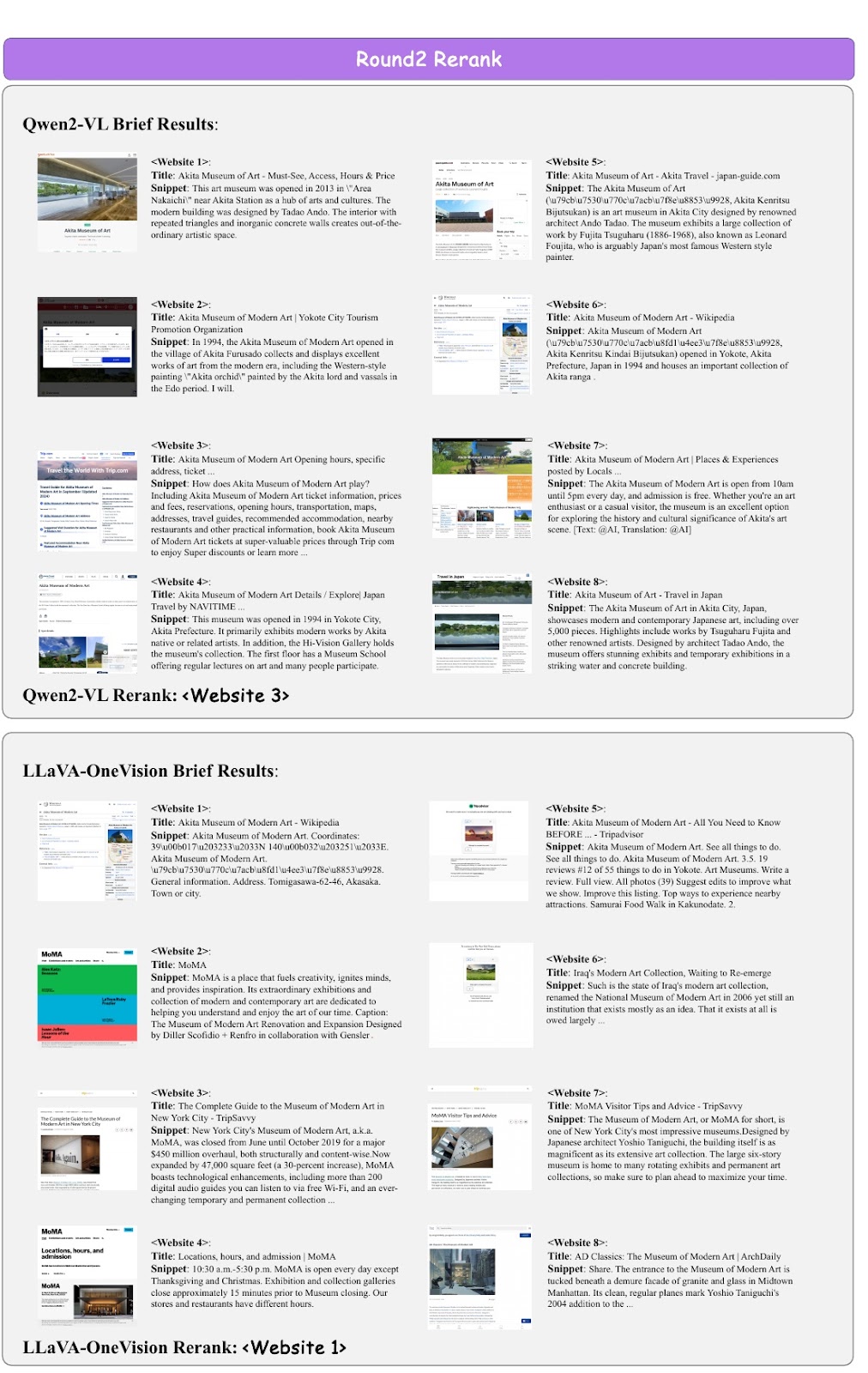
This figure illustrates the selection of search results in the "round 2 re-rank" process of the paper. Specifically, two different models, Qwen2-VL and LLaVA-OneVision, visualize the scene of selecting the appropriate website from given information.
Let's start with the Qwen2-VL results. This model is based on information about the Akita Museum of Modern Art (Akita Museum of Modern Art). In the search results, Qwen2-VL selects "Website 3". This website provides the museum's hours of operation and specific address information, and also includes a travel guide and neighborhood recommendations.
Next, we discuss the results of LLaVA-OneVision. This model also deals with information about the Akita Museum of Contemporary Art and selects "Website 1" from the websites provided. This website is based on information from Wikipedia and has general and location information.
Both models pick out the websites they find most useful from the information they are given.

This figure, in the section of the paper titled "Round2 Rerank," shows the brief results of the websites used by the model Qwen2-VL to perform the re-ranking. The purpose of the figure is to evaluate which Web sites provide the most useful information for the question.
The figure shows the titles and snippets (brief descriptions) of eight websites. These snippets contain an overview of what each site is about. Through this process, the model determines which site to choose and how that choice affects the following information gathering and response generation.
In detail, the Qwen2-VL model indicates that <Website 3> was selected. This website provides detailed information about the Akita Museum of Modern Art, specifically including information about the exhibits and admission fees that visitors would like to know about. This helps the model identify the most appropriate source of information for the question and generate an answer based on that information.



Categories related to this article
![Libra] A New Multimo](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2025/libra-520x300.png)




