
TaPA: Robot Action Generation Agent Using LLM
3 main points
✔️TAsk Planing Agent (TaPA) with LLM and visual perception models to generate executable plans according to objects present in the scene
✔️ open-vocabulary for complex tasks in realityGeneralized object detector
✔️ Increased average success rate of robot action steps compared to ChatGPT3.5
Embodied Task Planning with Large Language Models
written by Zhenyu Wu, Ziwei Wang, Xiuwei Xu, Jiwen Lu, Haibin Yan
(Submitted on 4 Jul 2023)
Comments: Project Page
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Robotics (cs.RO)
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
Introduction.
You may have heard the name natural language processing mentioned more often recently with the advent of ChatGPT. Natural language processing is not only required for tasks like ChatGPT, but also for robots. For example, when robots are introduced into fields such as housekeeping services, medicine, and agriculture, they need to accomplish those complex tasks. One of the problems these fields face is that the actions to be substituted by robots and the situations in which they can run autonomously differ depending on the field. In addition, it is practically impossible to anticipate and train robots for each field and situation.
However, recent advances in large-scale language models (LLMs) have made it possible to acquire a wealth of "knowledge" from vast amounts of data. This may enable robots to respond to human commands (in natural language) and generate actions that are appropriate for various situations.
issue
However, there is a problem with generating robot actions using LLMs. That is that LLMs cannot recognize the surrounding scene. In addition, the generation of robot actions requires interaction with objects that do not exist, which can lead to the generation of infeasible actions.
For example, given the human command "Give me some wine," the action step generated by GPT-3.5 is "pour wine from the bottle into the glass. In reality, however, only a mug may exist instead of a glass, and the feasible action should be "pour wine from the bottle into the mug". Therefore, executing the task plan generated by LLM in the real world is necessary to build an embodied Agent for accomplishing complex tasks.
*Agent here refers to the ability of LLM to select and execute the means and order according to the user's requirements.
The TAsk Planing Agent (TaPA) presented in this article is an Agent that combines LLM and visual perception models to generate executable plans according to objects present in a scene.
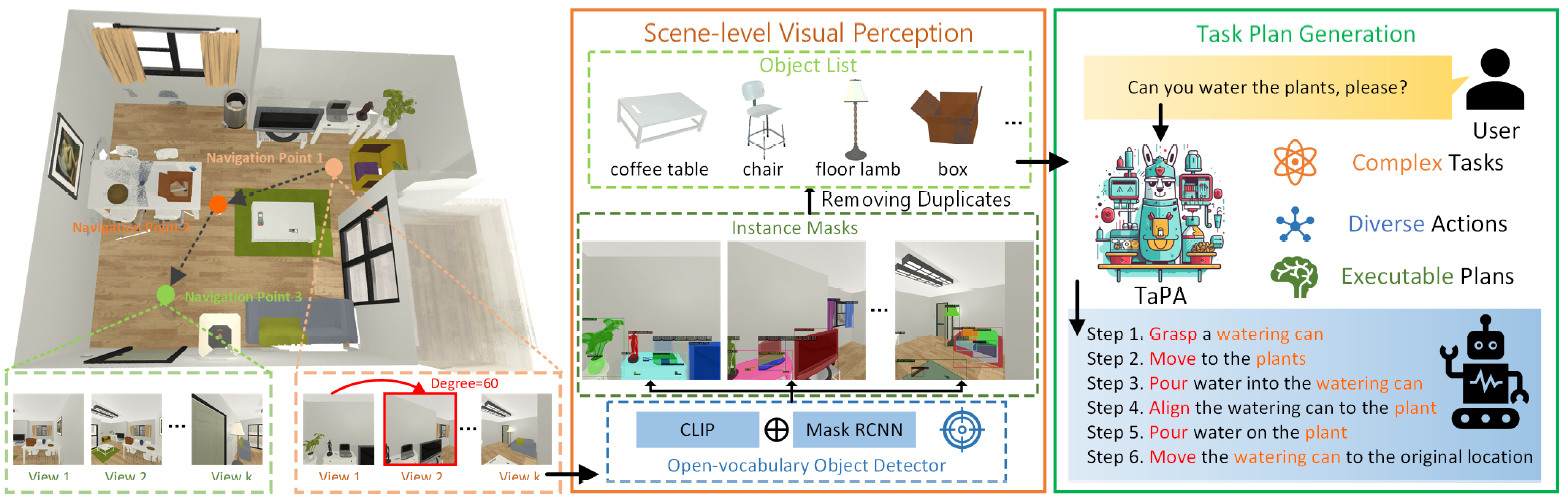
TaPA:TAsk Planing Agent
The TAsk Planing Agent (TaPA) is an Agent that combines LLM and visual perception models to generate executable plans according to objects present in a scene.
Specifically, we first construct a multimodal dataset that includes indoor scenes, instructions, and action plans. Next, we generate a large number of instructions and corresponding action plans by providing a list of objects present in the prompts and scenes generated by GPT-3.5.
The data generated is used to tune the pre-trained LLM's execution plan to reality. During inference, objects in the scene are found by extending the open vocabulary object detector to multi-view RGB images collected at different achievable locations.
TaPA is achieved through two major approaches, as follows
Data Generation of Embodied Task Planning
This section describes the construction of a multimodal instruction data set to be utilized for tuning the TaPA task planner.
Given an embodied 3D scene Xs, we use the class names of all objects directly as a representation of the scene: Xl = [table, chair, keyboard, ...]. and all duplicate names are removed to provide scene information to the LLM.
Based on the above scene information, the LFRED benchmark approach to generating multimodal instructions that follow an embodied task plan data set is to artificially design a set of instructions with corresponding step-by-step actions. However, artificial design requires high annotation costs to generate practical and complex task plans for realistic service robots, such as those that clean up the bathroom or make sandwiches.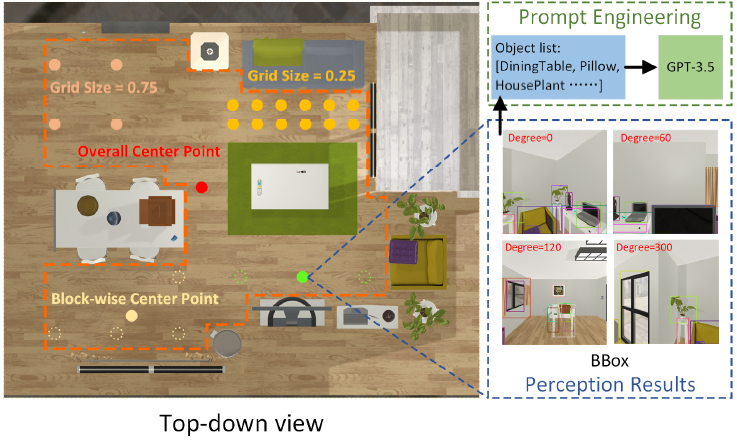
Therefore, TaPA will utilize GPT-3.5 along with presented scene representations and prompts designed to generate large multimodal data sets for Agent tuning.
For GPT-3.5, we designed a prompt that simulates an embodied task planning scenario that automatically synthesizes data based on an object name list Xl to efficiently generate a large, complex instruction Xq and an executable correspondence plan Xa for a given 3D scene.
Specifically, the prompt designs a conversation between a service robot and a human, simulating the robot's exploration in an embodied environment by generating executable instructions and actions, and providing requests from the human. The instructions generated are diverse, including requests, commands, and queries, and only instructions with explicit executable actions are added to the dataset. For the object list used in the prompts for dataset generation, the groundtruth label of the instance present in the scene is used.
The figure below shows an example of a generated sample that includes a list of object names for the scene, instructions, and action steps that can be executed. In the embodied task plan, the Agent can only access visual scenes containing all dialogue objects without a truth object list.

Therefore, a multimodal dataset is constructed by defining X = (Xv,Xq,Xa) for each sample. The training of the task planner makes use of the groundtruth object list for each scene to avoid the effects of inaccurate visual recognition. Inference predicts a list of all objects present in a scene with an extended open vocabulary object detector.
The AI2-THOR simulator was also employed as the Agent's concrete environment, with 80 scenes divided for training and 20 for evaluation. For fine-tuning an effective task planner, the original 80 training scenes are expanded to 6400 training scenes by modifying the groundtruth object list to expand the scale and diversity of instructions and action steps in the training samples.
For each scene, we first enumerate all rooms of the same room type to obtain a list of objects that may appear in this type of scene. Next, we randomly replace the objects that are present with other objects that are not observed because they may be present in the same room type.
Grounding Task Plans to Surrounding Scenes
This section details the grounding of the specific task plan for the scene through image collection and open vocabulary detection.
In order to adapt the embodied task plan to a feasible reality, it is necessary to accurately acquire a list of objects in the scene without generating missing instances or false positives. To explore the surrounding scene in 3D, several strategies for image collection will be designed. Location selection criteria include traversal locations, random locations, global center points, and block-wise center points; Agent rotates the camera and acquires multi-view images for each location selection criteria.
The strategy S for image collection is expressed by the following formula
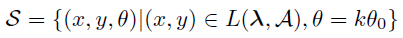
(x,y,θ): position and camera orientation, L(λ,A): criteria for selecting position by hyper parameter λ
θ0: unit angle of camera rotation, k: integer to define different scene orientations
The hyperparameter common to all location selection criteria is the length of the grid edge, which divides the achievable area into grids.
The traversal position selects all grid points for RGB image collection. The overall center point represents the center of the entire scene without hyperparameters. The block-wise center point selects the center of each segment in the scene for efficient acquisition of fine-grained visual information.
The clustering method uses the K-means clustering method because it can improve perceptual performance by dividing the entire scene into several subregions. In addition, the within-cluster sum of squared errors (WCSS) principle is employed to select the optimal number of clusters for each scene.
Furthermore, assuming that new objects appear in the scene that are not in the trained detector, it is necessary to retrieve the object list. Therefore, we generalize the open vocabulary object detector. In addition, the Agent collects RGB images at different locations to discover objects present in the scene.
The predicted object list Xl is represented by the following formula
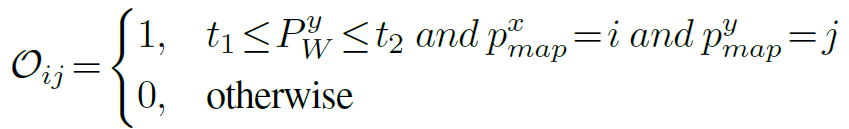
The predictive object list is obtained by removing duplicate object names from the multi-view image detection results. Here, Rd is the operation to remove duplicate object names, and D(Ii ) represents the object name detected for the i-th RGB image collected in the scene.
These two approaches enable the Agent to generate an executable plan while predicting unknown objects to objects present in the scene.
experiment
In the experiment, 60 validation samples were used to compare the TaPA method, state-of-the-art LLMs including LLaMA and GPT-3.5, and LMMs including LLaMA. The success rates of the action steps generated from the different methods are shown in the table below.

TaPA achieved optimal performance among all large models in all four scenarios, including kitchen, living room, bedroom, and bathroom. The average success rate of TaPA is 6.38% higher than that of GPT-3.5.
In addition, the performance of the current larger models is lower than other room types because Agents in kitchen scenes typically deal with complex cooking instructions with more steps. On the other hand, LLaVA's poor performance in visual question-answering tasks suggests that overall scene information cannot be represented in a single image, and inadequate scene information leads to low success rates in task planning.

In addition, the figure above shows examples of action steps generated from different large models for a given scene. The scene is shown in a top-down view and also provides a grand-truth object list for reference; the content from LLaMA is independent of human instructions, and LLaVA provides infeasible plans for objects that do not exist. GPT-3.5 also yields embodied task plans, but TaPA's action steps are more complete and closer to human values.
Conclusion
Recently, research on generating robot behavior through natural language processing has been gaining momentum. If technologies that allow robots to act on human commands are further developed, robots that can respond to environmental changes, such as weather, which is a problem in automated driving technology, may be created.
In addition, as interactive technology develops in the future, as in the research discussed here, we expect that safe collaboration between humans and robots will be realized, and the way people work will change.



Categories related to this article
![Libra] A New Multimo](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2025/libra-520x300.png)




