
VoxFormer" Generates 3D Volumes From Images For Use In Automated Driving Technology.
3 main points
✔️ Proposal of a Transformer-based semantic scene completion framework "VoxFormer"
✔️ It is possible to output full 3D volume semantics from 2D images only
✔️ LiDAR information Camera-based method using datasets
VoxFormer: Sparse Voxel Transformer for Camera-based 3D Semantic Scene Completion
written by Yiming Li, Zhiding Yu, Christopher Choy, Chaowei Xiao, Jose M. Alvarez, Sanja Fidler, Chen Feng, Anima Anandkumar
(Submitted on 23 Feb 2023 (v1), last revised 25 Mar 2023 (this version, v2))
Comments: CVPR 2023 Highlight
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Robotics (cs.RO)
code:

The images used in this article are from the paper, the introductory slides, or were created based on them.
Introduction
In the past few years, with the spread of artificial intelligence and information technology, there has been an increase in efforts to implement and popularize automated driving in society. Although many challenges still exist in automated driving, research for safe driving is progressing with the widespread use of drive recorders and sensors, as well as various other approaches. Among these, image processing technology is often responsible for the development and application of the field as well as automated driving.
The ability to see the whole scene in 3D is a key issue in "sensing" automated driving. For example, it has a direct impact on tasks such as planning the route of a self-driving car and its route. However, it is difficult to perfectly capture the 3D information from the real world due to insufficient sensing technology, limited angles of view, and imperfections caused by occlusion.
VoxFormer, presented in this article, generates 3D volume semantics from images to enable safe automated driving, regardless of camera and sensor specifications.
Related Research
To solve the challenges that arise when obtaining information from the real world, a semantic scene completion (SSC) technique was proposed to infer the complete shape and meaning of a scene from a limited range of observations. SSC solutions are based on the prediction of the overall scene and its meaning from partial human observation and simultaneously address two subtasks: reconstruction of the scene into the visible domain and illusory completion of the scene into the hidden domain. However, there is a significant difference between state-of-the-art SSC methods and human perception in automobile driving.
Many existing SSC solutions also use LiDAR (Light Detection and Ranging) as their primary sensor to enable accurate 3D shape measurement. LiDAR is a sensor technology that uses laser beams to determine the distance and shape of an object based on the reflected light. However, LiDAR sensors are expensive and not portable.
On the other hand, cameras such as drive recorders are inexpensive and can receive information on visual cues of the driving scene. Therefore, a camera-based study was conducted with MonoScene as one of the SSC solutions; MonoScene converts 2D image input into 3D using high-density feature projection. However, such projections inevitably assign 2D features in the visible domain to empty or occluded voxels
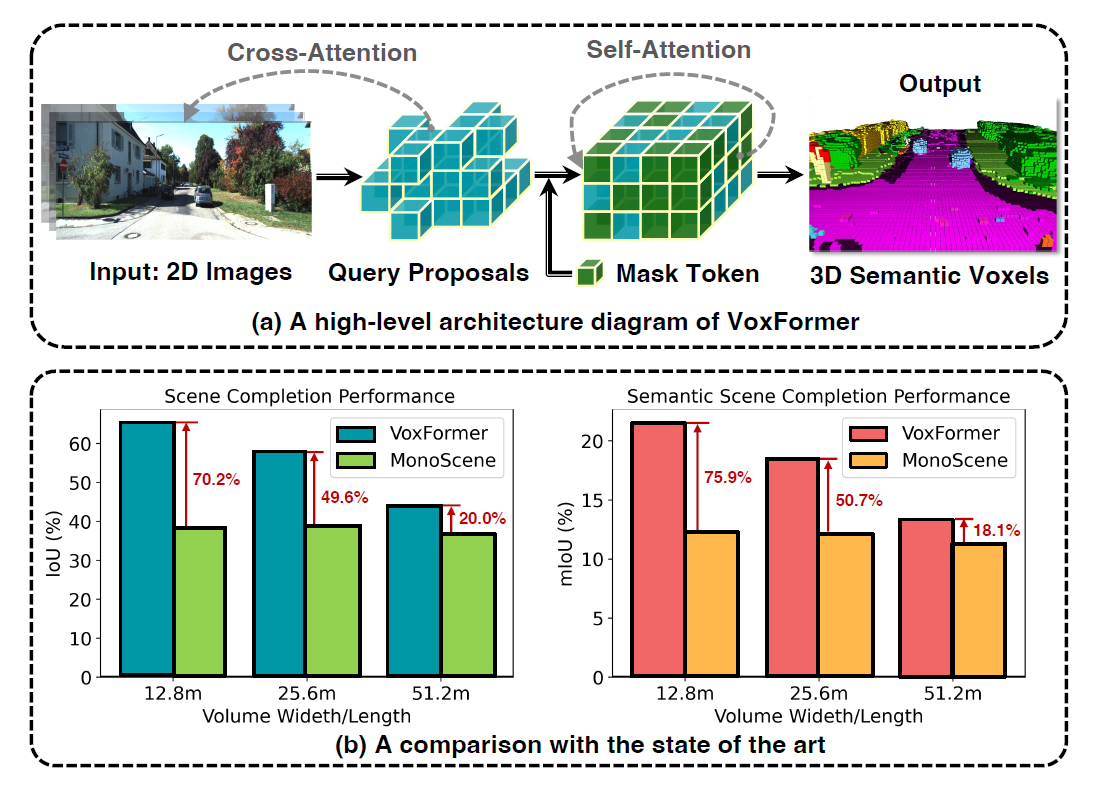 Unlike MonoScene, the VoxFormer presented in this study considers 3D-to-2D cross-attention to express sparse Query, and achieves the following four things.
Unlike MonoScene, the VoxFormer presented in this study considers 3D-to-2D cross-attention to express sparse Query, and achieves the following four things.
- Development of a new two-step framework for converting images into complete 3D voxelized semantic scenes
- Build a network that proposes a new Query based on 2D convolution that generates reliable Query from image depth.
- New Transformer similar to Masked Autoencoder (MAE) for full 3D scene representation
- Realization of a state-of-the-art camera-based SSC method using the SemanticKITTI dataset
VoxFormer Overview
VoxFormer consists of a class-independent query proposal (Stage-1) and a class-specific semantic segmentation (Stage2); Stage-1 proposes a sparse set of occupied voxels and Stage-2 represents a scene from the Stage-1 proposal.
Stage-1 has a lightweight 2D CNN-based Query proposal network that reconstructs the shape of the scene using image depth. It then proposes a sparse set of voxels from a predefined trainable voxel Query of the full field of view.
Stage-2 is based on a new sparse-to-dense, MAE-like architecture. It features proposed voxels, associates unproposed voxels with learnable mask tokens, and represents the scene through voxel-by-voxel semantic segmentation.
architecture
As shown in the figure below, SSC with TransFormer learns 3D voxel features from 2D images.
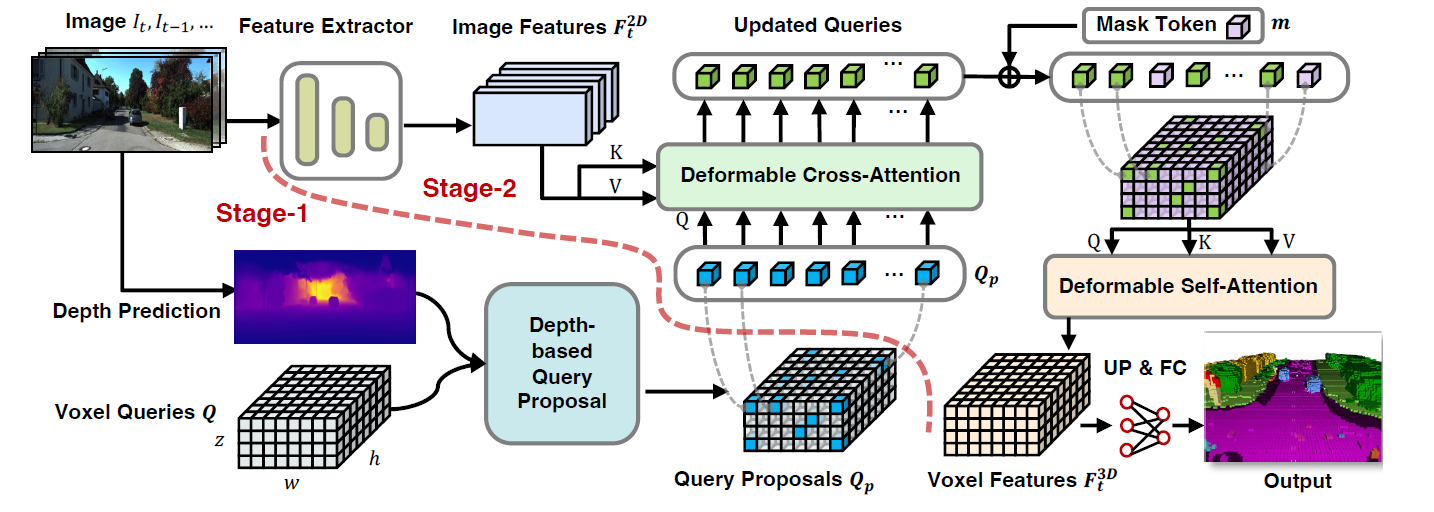
The VoxFormer architecture extracts 2D features from RGB images, uses a sparse set of 3D voxel Query, indexes these 2D features, and links the 3D positions to the image stream using the camera projection matrix.
A voxel query is a 3D lattice of learnable parameters that query features in the 3D volume from the image via the Attention mechanism. A total of Nq voxel queries are predefined as clusters of 3D lattice-like learnable parameters, as shown in the lower left of the figure above.
Some voxel Query is also selected to focus on the image, and the remaining voxels are associated with another trainable parameter to complete the 3D voxel features. These parameters are called Mask tokens, indicating the presence of predicted missing voxels.
training loss
Stage-2 is studied with weighted cross-entropy loss.
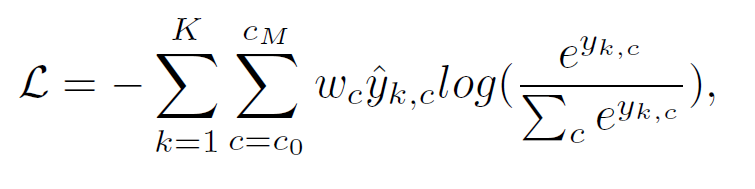
k: voxel indexK: total number of voxelsc: class index
Stage-1 employs binary cross-entropy to predict occupancy maps with lower spatial resolution.
experiment
data-set
VoxFormer is validated using SemanticKITTI, a dataset of LiDAR sequences. SemanticKITTI is semantically annotated for each LiDAR sweep of the "KITTI Odometry Benchmark," comprising 22 outdoor driving scenarios.
mounting
Stage-1
MobileStereoNet is used to directly estimate depth. Depth, like MobileStereoNet, can generate low-cost pseudo-LiDAR point clouds from stereo images alone.
Stage-2
The cam2 RGB image is cropped to 1220 x 370, image features are extracted using ResNet50, and the third-stage features are captured using FPN to generate a feature map 1/16 the size of the input image size. Two types of VoxFormer are available: VoxFormer-S, which takes only the current image as input, and VoxFormer-T, which takes the current and previous four images as input.
evaluation
We employ intersection over union (IoU) to evaluate the quality of scene completion regardless of the assigned semantic label. As a baseline, we compare the latest SSC with VoxFormer and public resources on the following three points
- MonoScene, a camera-based SSC method based on 2D to 3D feature projection
- LiDAR-based SSC methods including JS3CNet, LMSCNet, and SSCNet, and
- RGB interferometric baselines LMSCNet and SSCNet with pseudo-LiDAR point clouds generated by stereo depth (MobileStereoNet) as input
result
This article will cover the results of the comparison with camera-based and LiDAR-based methods.
Comparison with camera-based methods
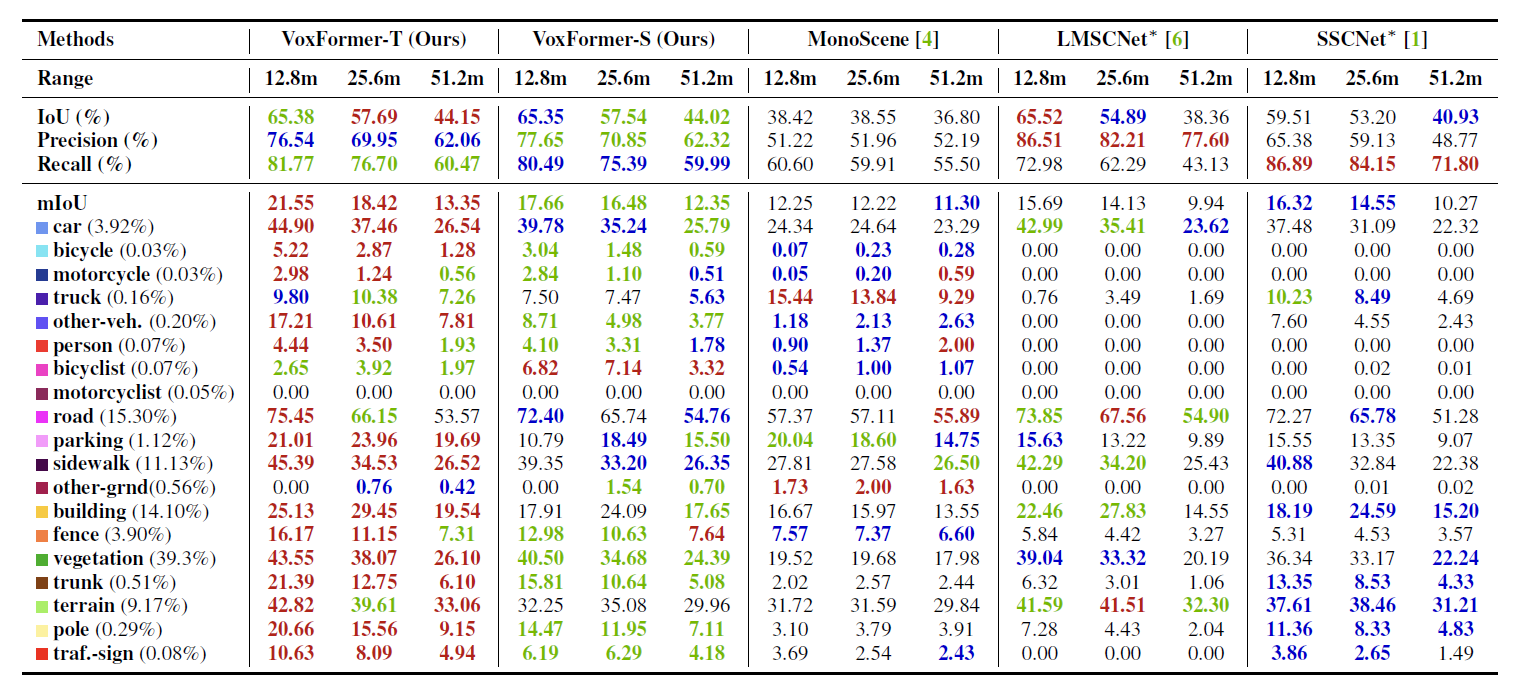 VoxFormer-S outperformed MonoScene by a wide margin in geometric complementarity, indicating that stage-1, with its explicit depth estimation and correction, was able to reduce a lot of white space during the query processing.
VoxFormer-S outperformed MonoScene by a wide margin in geometric complementarity, indicating that stage-1, with its explicit depth estimation and correction, was able to reduce a lot of white space during the query processing.
Comparison with LiDAR-based methods
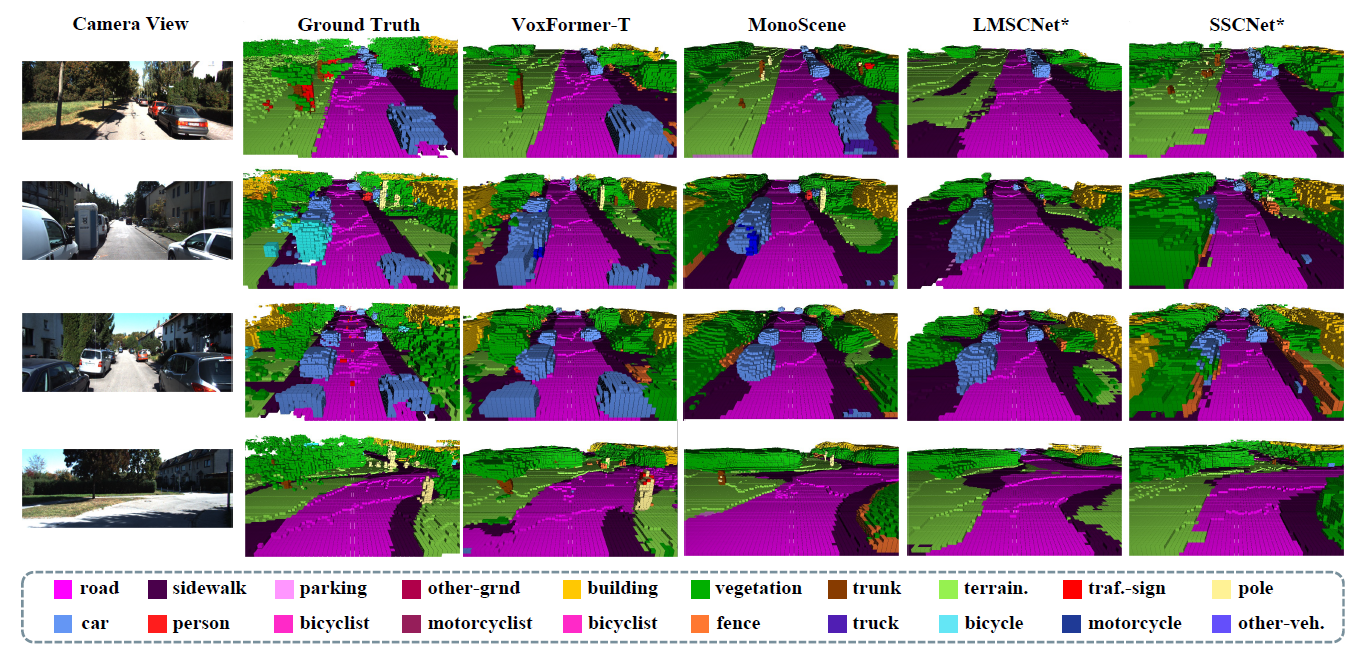
As you approach the Ego Vehicle (a vehicle equipped with an automated driving system), you can visually see that the performance difference between the LiDAR-based method becomes smaller.
summary
Extensive testing on the SemanticKITTI dataset showed that VoxFormer achieves state-of-the-art performance in geometric completion and semantic segmentation. Importantly, VoxFormer showed greater improvement than other solutions in the near-range, where safety is critical. In addition, VoxFormer does not require an expensive camera to infer, an inexpensive camera is sufficient, thus considering not only the technological advances but also the cost aspects of real-world implementation.
In the future, if more research is conducted on more accurate SSC solutions that do not require expensive cameras and sensors like VoxFormer, we believe this will expand the possibilities of automated driving technology.



Categories related to this article
![[PETRv2] Estimates T](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/November2023/petrv2-520x300.png)




