A Universal-Scale Object Detection Benchmark
3 main points
✔️ A universal-scale object detection benchmark(USB) for reliable comparison of object detection methods.
✔️ A set of fair, easy, and scalable protocols for evaluating new methods on the USB benchmark.
✔️ Fast and accurate object detectors called UniverseNets that improve the SOTA on several benchmarks.
USB: Universal-Scale Object Detection Benchmark
Written by YosukeShinya
(Submitted on 25 Mar 2021)
Comments: Accepted to arXiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:.
Introduction
Humans are capable of identifying a wide variety of objects, whether they are scenes, texts, or objects in paintings and animations. This is an ability we want Deep Neural Networks to possess and we have certainly come a long way. DNNs benefit from a large and information-rich dataset and DNNs for object detection is no exception. The COCO dataset has played an essential role in object detection. It has been widely used to develop and evaluate new methods for object detection. However, it has a few drawbacks that need to be addressed.
COCO fails to cover variations in object scales and image domains which are necessary for human-level perception. Despite this, several research works solely use the COCO dataset for the assessment of new methods without showing if they generalize to other datasets. This raises a need to establish standard protocols for training and evaluation in object detection.
In this paper we introduce a new benchmark for universal-scale object detection called USB, that enables reliable comparison of object detection methods. We also establish standard USB protocols to enable fair, easy, and scalable comparisons of new methods. Finally, using the USB dataset and new protocols, we train new object detection models called UniverseNets that significantly improve the SOTA on several object detection datasets.
Universal-Scale Object Detection Benchmark(USB)
There are several benchmarks for object detection: WIDER Face and TinyPerson for specific categories, KITTI and WOD for autonomous driving, PASCAL VOC(20 classes), and COCO (80 classes) for generic object detection, ClipArt-1k and Manga108-s for artificial images, and more. Universal-domain object detection benchmark(UODB) combines 11 datasets from various domains but at the same, time lacks variation in object scales.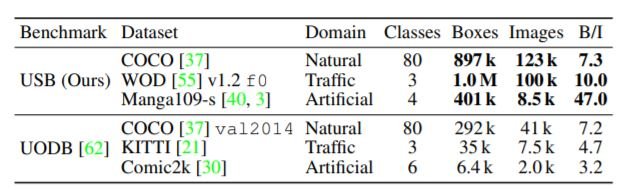
Our dataset USB comprises three datasets: COCO, Manga108-s, and Waymo Open Dataset(WOD). Compared to UODB we focus more on universal-scale i.e. the classes contain more instances including tiny images. Manga108 and WOD consist of many small objects in the artificial image and traffic domains respectively. For the WOD dataset, we extracted 10% subsets from the training (f0train) and validation (f0val) split to get 798 and 202 splits respectively. Each sequence has 20 frames and each frame in turn has 5 images from 5 cameras. We specifically used three categories: vehicle, pedestrians, and cyclists. Also, we carefully selected 68, 4, and 15 volumes of mangas for training(68train), validation(4val), and test (15test) respectively.
USB Training/Evaluation Protocol
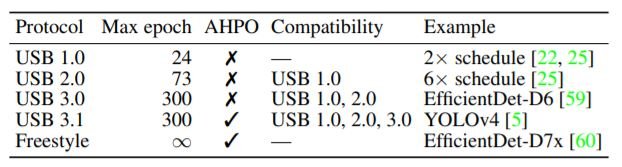
The USB training protocols are shown in the above table. AHPO stands for Aggressive Hyperparameter Optimization. Participants are required to report results not only with higher protocols but also lower protocols. Eg: When a participant trains model with 150 epochs with AHPO, it falls under USB 3.0 protocol. In addition, the participant should train another model with standard hyperparameters for 150 epochs and report the results for 150, 73, and 24 epochs as well.
For models trained with masked annotations, 0.5 is added to the protocol version. Eg: if masked annotations were used in the previous example, the protocol would be called USB 3.5. Moreover, the pretraining dataset is limited to ImageNet and USB. We also recommend that hyperparameters like batch sizes and learning rates be roughly finetuned. When AHPO is used, participants should report both results with and without AHPO.
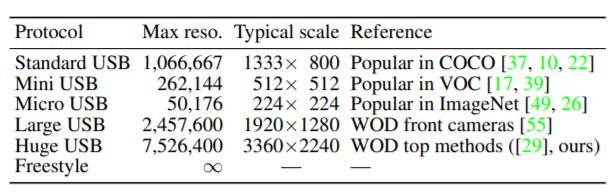
The above table shows the USB evaluation protocols with different input scales. Test-Time Augmentations(TTAs) can make a huge difference in accuracy and inference time. So, when TTAs are used, the details of TTAs, along with results without TTAs must be reported.
UniverseNets
UniverseNet is built on RetinaNet, with ATSS and SEPC (called ATSEPC) without iBN. We used multi-scale training but single-scale testing for efficiency (unless stated). UniverseNet-20.08d is another version that heavily uses Deformable Convolutional Networks(DCN). UniverseNet-20.08 makes light use of DCN to speed up UniverseNet-20.08d and UniverseNet-20.08s further speeds up inference using ResNet-50-C backbone instead of the Res2Net-50-v1b backbone used in other versions.
Experiment

In this section, we present several experimental results to assess the USB benchmark and UniverseNets. The above table shows the default hyperparameters. We used models pretrained on COCO for Faster R-CNN with FPN, Cascade RCNN, RetinaNet, ATSS, and GFL. Furthermore, the CNN backbones of these models had been pretrained on ImagNet.

The above table shows the results of various models on USB. UniverseNet-20.08 shows the most impressive results on all three datasets and attains mCAP score of 52.1. mCAP is the average CAP score of the three datasets. Some models show significant improvements on COCO dataset while they show only slight gains on the other two datasets. In this way, USB is able to expose COCO-biased methods.
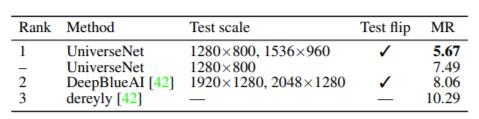
UniverseNet was able to set the new SOTA in NightOwls, a benchmark for person detection at night. For this purpose, a model pretrained on WOD was finetuned on the NightOwls dataset. For more information about the experiments, please refer to the original paper.
Summary
The USB benchmark along with the training and evaluation protocols resolves the ambiguity while comparing different models in object detection. This will enable better models to get more attention and refinement from the research community and industry. One major drawback of UniverseNets is that they had also been pretrained on COCO and were biased towards the dataset. Future works should strive to develop more unbiased universal detectors. The protocols mentioned in this paper can be extrapolated to other tasks in vision or even NLP.



Categories related to this article

![[PETRv2] Estimates T](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/November2023/petrv2-520x300.png)




