
Autonomous Drone-controlled Reforestation Approach Using MA Reinforcement Learning
3 main points
✔️ Propose an approach to reforesting hard-to-reach areas with autonomous drones using reinforcement learning
✔️ Demonstrate that the communication mechanism of a multi-agent reinforcement learning system enables collaborative work in an environment that is only partially observable
✔️ Variable difficulty depending on topography and forest information Creation of a simulation environment that generates scenarios with varying degrees of difficulty depending on terrain and forest information
Dynamic Collaborative Multi-Agent Reinforcement Learning Communication for Autonomous Drone Reforestation
written by Philipp Dominic Siedler
(Submitted on 14 Nov 2022)
Comments: Deep Reinforcement Learning Workshop at the 36th Conference on Neural InformationProcessing Systems (NeurIPS 2022)
Subjects: Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Multiagent Systems (cs.MA); Robotics (cs.RO)

code :
The images used in this article are from the paper, the introductory slides, or were created based on them.
Introduction
Recently, we have been hearing terms such as Digital Twin and Sim-to-Real more and more often. These are increasingly being used in efforts to move robots and drones in the real world based on information in a simulated environment. Also, attempts are being made to improve accuracy and automation through the use of machine learning and reinforcement learning.
However, group control of drones using artificial intelligence poses several problems for real-world use. For example, there is an undeniable possibility that a drone may not be controlled properly and hit a person. However, by using a simulation environment that assumes various accidents, these accidents can be reduced. Also, a group of people or individuals with interests can be viewed as an entity with agents, and in the real world, cooperation is necessary to achieve higher goals. This can be described as a multi-agent system, and reinforcement learning is often used in the collective behavior of robots and drones, including digital twins.

The research described in this article proposes an approach in which collective control of autonomous drones communicating in a dispersed environment reforests hard-to-reach areas.
summary
The objective is to perform reforestation with a decentralized autonomous system consisting of individual agents capable of making specific decisions in various scenarios. The task of the MA aggregate is to pick up tree seeds, find suitable spots for reforestation along the perimeter of the existing forest, and plant them, and plant them. In addition, the MA assemblage can communicate with each other through communication. We have also developed a simulation environment to train and test different learning mechanisms. This environment can accommodate open-ended learning by generating scenarios that may be challenging due to the topology of the terrain and the sparseness of the forest.
Before going into the detailed methods, as preliminary knowledge, we briefly describe the PPO used in this study and the graph neural network.
Proximal Policy Optimisation (PPO)
The PPO algorithm is defined in two main ways.
- The PPO performs the largest and safest possible gradient ascent learning step by estimating the confidence region.
- Advantage estimates how much better behavior in a particular state is compared to the average behavior.
Advantage can also be described as the difference between the Q and value functions.
Graph Neural Network (GNN)
The basic functionality of GNN is the classification of graphs, nodes, and edges. The characteristics and existence of nodes and edges can be predicted using adjacent nodes and existing edges.
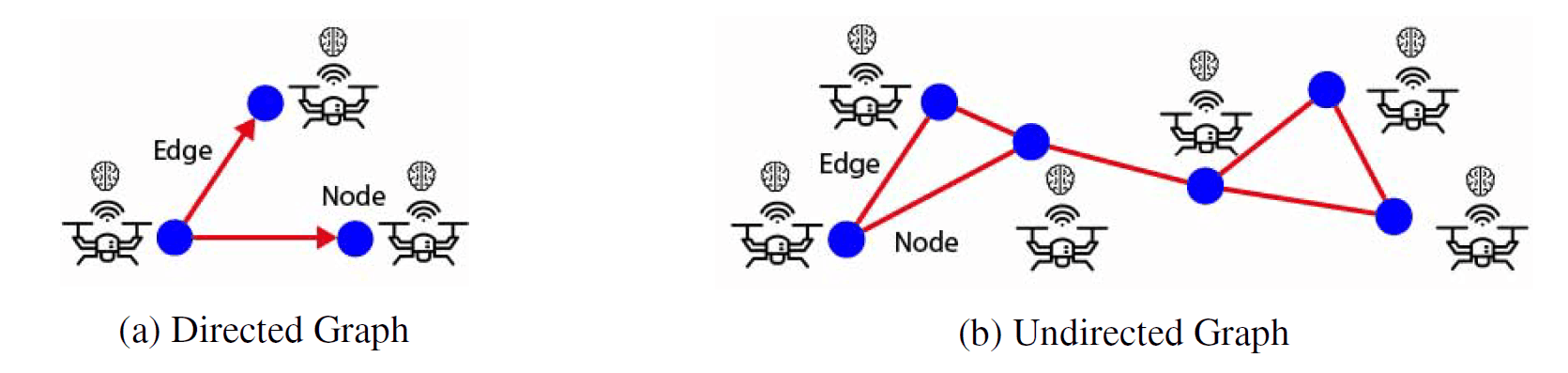 A graph consisting of vertices (blue points) and edges (red lines)
A graph consisting of vertices (blue points) and edges (red lines)
A graph is a data structure based on nodes or vertices and edges (see above), and node and edge objects can hold arbitrary amounts of any type of feature. An edge represents a relationship between two nodes, and a node can have an unlimited number of relational edges with other nodes. Furthermore, the classification of the entire graph can be accomplished with node and edge features and the graph's topology as input.
method
Methods are broadly divided into the drone simulation environment, agent setup, and drone-to-drone communication.
Simulation Environment

A multi-agent (MA) baseline and multi-agent communication setup (MAC) simulation and a 3D reforestation environment developed in Unity will be used for online training. In this environment, agents solve problems by retrieving tree seeds from a drone station, finding the best place to plant the tree seeds, dropping the tree seeds, and returning to the drone station to recharge the battery and retrieve the next tree seed.
All variations of environmental scenarios consist of the following elements
- Procedurally generated terrain using octaves, persistence, and lacunarity-based noise
- Trees (forest) placed in a fixed height area combined with a random noise map, showing only fertile land (here a green lawn)
- The human user interface can show the best and most rewarding areas for reforestation
- The height heatmap is displayed only in the human user interface.
- Networks that define nearest neighbors that are dynamically displayed in cyan only in the human user interface
Agent Setup
The following items are provided as agent setup
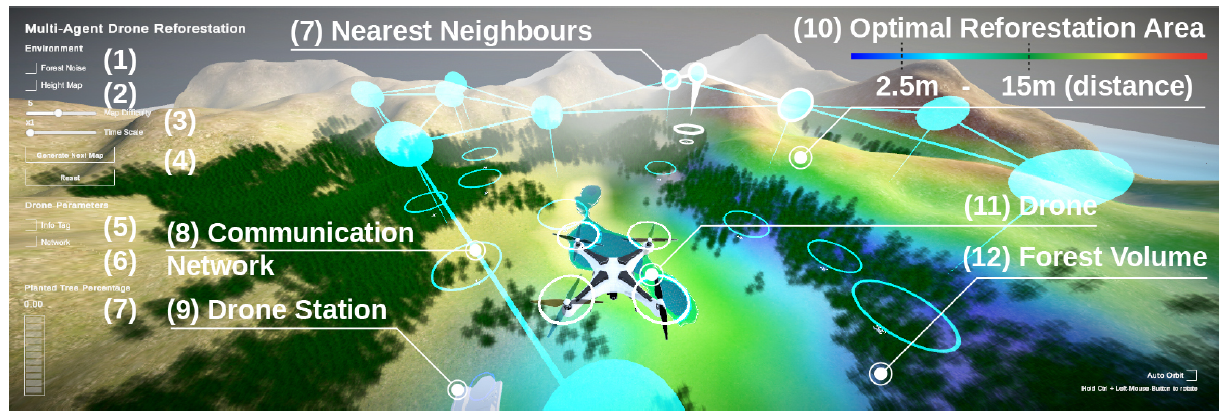
Goal: Each agent will learn to guide the drone to the drone station, where it will be automatically serviced, pick up tree seeds and charge the battery. They then maneuver the drone to find the best place to drop off the tree seeds and return to the drone station, while checking the battery level.
Reward Function: The agent's reward function consists of several parts. If you do not have seeds, your reward increases as you approach the drone station regardless of distance, accumulating to a total of +20. In addition, rewards are +0~+30 depending on where the tree seeds are dropped.
Vector Observations: all vector observations are normalized. The final vector observation has a spatial size of 30, consisting of two stacks of 15 described observations.
Visual Observations: Visual observations are 16x16 grayscale grids taken by a downward-facing camera with a field of view of 120-256 cells mounted on each drone, each with a float value in the range [0-1]. This results in a total observation space size of 286.
Continuous Actions: Each agent has three continuous actions with values ranging from -1 to 1. The constant actions control the drone's movement. Action 0 controls forward/backward movement, action 1 controls rotation and left/right, and Action 2 controls the up/down movement of the drone. In addition, the drone moves at a speed of 1 meter per time step.
Discrete Actions: the space size of a discrete action is 2 and can be described as two trees with values [0, 1]. Discrete Action 0 drops the seed of the tree with a value of 1 and Action 1 stores the location in memory with a value of 1. Both actions do nothing if the value is 0.
Multi-Agent Communication
This learning mechanism allows the agent to receive graph-structured data. Messages can be exchanged when drones are within 200 meters of each other. It can also respond to three nearby agents in a multi-agent communication configuration (MAC) and receive a total of three messages. If there are only two nearby drones, only two messages will be sent and received for each. Sending and receiving messages has no cost and earns no negative or positive reward.

experiment
In the experiment, we trained four different setups.
 test environment
test environment
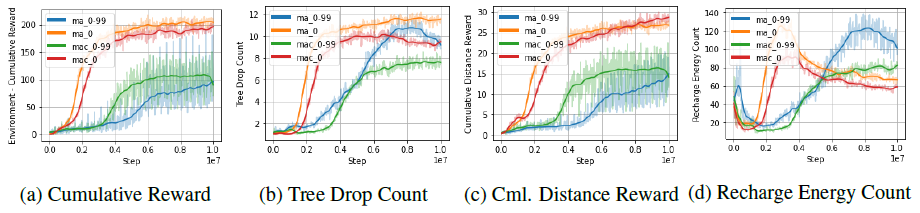 Training Graph
Training Graph
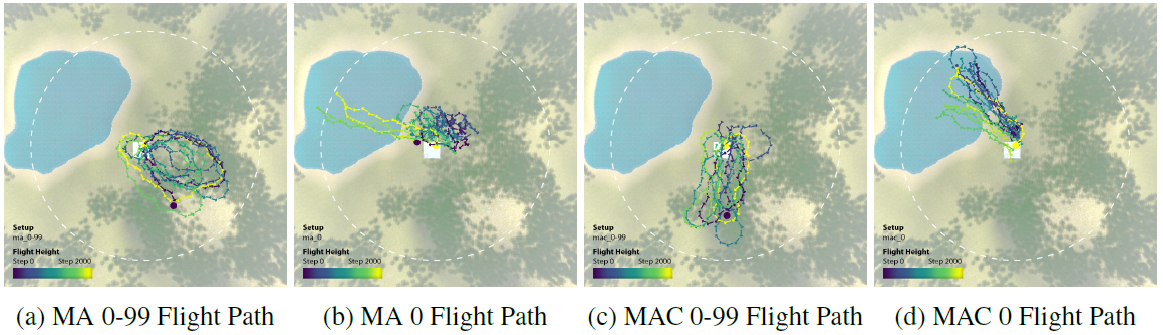
Multi-agent setup without communication capabilities as a baseline; Experiment 1 and Experiment 2 are trained without communication capabilities; Experiment 1 was trained in a terrain scenario with a random seed of 0 and Experiment 2 was trained in a terrain scenario with a sequence of random seeds from 0 to 99. Seeded scenarios with a random seed of 0 and Experiment 2 with a random seed of 0 to 99. Experiments will also be conducted in a multi-agent setting with communication capabilities. Experiment 3 and Experiment 4 will be trained to have communication capabilities. Experiment 3 is a terrain scenario with a random seed of 0 and Experiment 4 is a terrain scenario with a random seed of trained in a series of terrain scenarios with random seed ranging from 0 to 99. All experiments will then be tested on unseen terrain scenarios with random seed 111.
result
The results showed that communication by the multi-agent exceeded the baseline setting of the multi-agent without communication.
 experimental results
experimental results
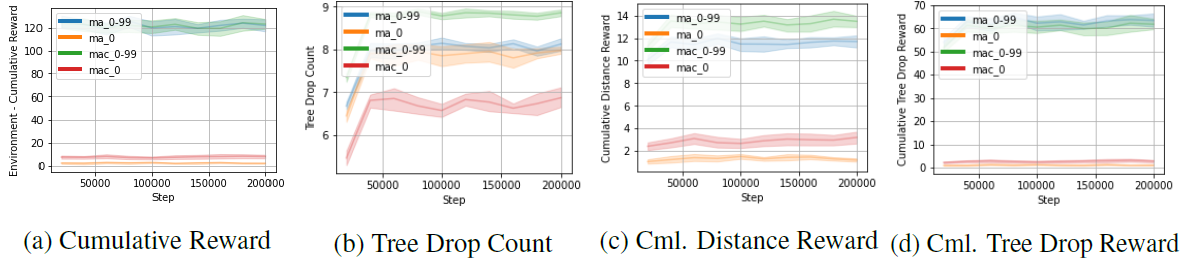 Test Graph
Test Graph
The MA 0-99 set trained on terrain scenarios with the random seed of 0-99 performed very well concerning cumulative reward. Agents trained in multiple scenarios performed better by a large margin compared to agents trained in a single terrain scenario. Additionally, the MAC 0-99 set was observed to achieve the highest number of tree drops and travel the furthest for exploration due to communication (see figure below).
summary
In this study, we explored an approach to reforestation by autonomous drones using multi-agent reinforcement learning (MARL) with a communication layer of graph neural networks (GNNs). The results showed that MARL can handle unknown terrain and that the communication capability improves the performance of the multi-agent population. In addition, there are still many gaps between the simulated environment and the real world.
As research related to this type of digital twin advances, we can expect to see a wider range of applications for virtual environments such as the metaverse. If we can create a mechanism that takes advantage of the advantages of virtual environments and incorporates them into reality, we believe that this will lead to new technological developments.



Categories related to this article





