RRL: Improving The Sample Efficiency Of Reinforcement Learning Using ImageNet
3 main points
✔️ Improve sample efficiency of Visual RL by using ResNet pre-trained on ImageNet
✔️ Higher performance on complex tasks compared to other methods
✔️ Visual RL should be benchmarked on more real-world tasks
RRL: Resnet as representation for Reinforcement Learning
written by Rutav Shah, Vikash Kumar
(Submitted on 7 Jul 2021 (v1), last revised 9 Jul 2021 (this version, v2))
Comments: Accepted by ICML 2021.
Subjects: Robotics (cs.RO)
code:
First of all
In this article, we introduce the paper RRL: Resnet as Representation for Reinforcement Learning, which was accepted to ICML2021. The application of Reinforcement Learning (RL) to robots has attracted much attention in recent years, but learning RL agents using images as input has become very difficult due to the inefficiency of samples. However, when we consider the application to the real world, it is very difficult to obtain information such as the coordinates of an object from the angle of the robot's joint or image information from the camera attached to the robot as information that the robot can receive as input. Then, how can we solve the task efficiently from these inputs such as images and the robot's own joint angle?
Various methods have been proposed for this problem, such as acquiring encoders by pre-training using supervised or unsupervised learning and using them for reinforcement learning. However, there is a problem that it is necessary to collect data for a specific task in order to acquire a representation. In contrast. This paper shows that a very simple method of using image data from ImageNet with an encoder pre-trained in ResNet can effectively increase sample efficiency.
Technique
In the first place, what does a good expression look like? There are four main ways to think about this.
1. a low-dimensional and compact representation
2. features that contain a variety of information for high versatility
3. less susceptible to noise, light, viewpoints, and other task-irrelevant information
4. an effective representation that covers the entire distribution required by the RL policy
To obtain such representations, domain-specific data is mostly required, but in this paper, we explored how it is possible to obtain the above representation without using domain-specific data.
Therefore, this paper proposed a very simple method as shown in the figure below. In this method, instead of training encoders with data from a specific domain, we use ImageNet, which is real-world image data with a sufficiently wide distribution, to pre-train encoders, fix the encoder weights, and then use reinforcement learning to learn measures. In the following, we will explain this method in more detail.

RRL: Resnet as Representation for RL
In reinforcement learning, the most ideal scenario is that the agent receives a low-dimensional state (e.g., coordinates of an object), executes an action, and then receives the next state and reward. This works well, especially in a simulation environment, because it is easy to get a low-dimensional state. However, in the real world, we cannot get the coordinates of objects, etc. Instead, we have to learn from the image information from the camera and the angle of the robot's own joint. Therefore, under such circumstances, it is important to learn and use low-dimensional features effectively from images, which are high-dimensional information. Therefore, in order to satisfy the items of good feature representation mentioned above, this paper shows experimentally that ResNet can be pre-trained with ImageNet and can cope with data of wide distribution by using its encoder. The method is as shown in the figure above. The pre-trained encoder receives the input image and outputs feature values. Here, the weights of the pre-learned encoders are fixed.
Experiment
In this paper, we conduct experiments using a reinforcement learning algorithm called DAPG, which can learn effectively when the input is a low-dimensional state, but does not learn well when the input is high-dimensional data such as images. Therefore, in this study, we experimentally showed whether the DAPG algorithm can effectively learn AGENT using low-dimensional feature representations obtained from images. In this experiment, we confirm the following five things
- Whether RRL can learn complex tasks from images with features pre-trained by large-scale image data?
- Whether the performance of RRL is good compared to other state-of-the-art methods?
- Whether the performance is affected by the choice of the pre-trained model (ResNet)?
- Does the size of the RRL model significantly affect the performance?
- Whether the commonly used task of continuous control with images as input is an effective benchmark?
In our experiments, we tested the Adroit manipulation suite on the manipulation task shown in the figure below. Since these tasks are difficult to learn from states and the images are complex, effective feature representation is required for successful learning.

Result
The figure below shows a comparison between RRL and other baselines such as FERM, DAPG, and NPG (Natural Policy gradient). As shown in the figure below, NPG often fails to solve the task even with only the state, indicating that the task itself is relatively difficult. This can be regarded as an oracle baseline. Although RRL is trained from images, it solves all tasks well, and some tasks are almost the same as DAPG with state as input. Finally, the agent trained using FERM, a sample-efficient framework that uses the latest images as input, succeeds in solving some of the tasks, but the large variance in the results indicates that the learning is very unstable. FERM differs from RRL in that it learns encoders using the task's data rather than ImageNet, so it learns task-specific features.

Effect of Visual Distractors
The graphs in the center and right of the figure below show the results of examining the effect of changing the color of light or objects (visual distractors) on the performance of RRL and FERM. As shown in the following figure, RRL is less affected by visual distractors than FERM. This is because the encoder of RRL is trained from large image data with wide distribution, so the encoder itself is relatively less affected by visual distractor, and as a result, the learned policy is also less affected by visual distractor. FERM, on the other hand, uses encoders trained on task-specific data (fixed light conditions and object colors), so it is more susceptible to visual distractors, resulting in significantly worse performance.

Effect of feature representation
The question is whether the choice of model, ResNet, is only capable of learning effective features by chance in the first place. To address this question, we compared the performance of RRL using ResNet with that of RRL using ShuffleNet, hierarchical VAE (VDVAE), and MobileNet. performance for VAE, but we were able to show that it works well for models other than ResNet.

The figure below shows a comparison between RLL (VAE) using VAE's encoder trained on specific task data and RRL based on Resnet trained on a wide distribution of data. From the figure below, the performance is higher when using Resnet. And it can be said that the encoder trained on large data with wide distribution is more effective than the very brittle encoder trained on task-specific data.

Impact of different inputs on performance
We investigated how the performance of the RRL changes depending on the type of input and noise. The figure below shows a comparison of RRL (Vision) without the robot's joint information obtained from sensors, RRL (Noise) with noise added to the joint information, and RRL (Vision+Sensors) using both image and joint data. As you can see in the figure below, there is some performance degradation, but we were able to show that RRL is robust to noise and performs reasonably well even with only image data.

The effect of the size of RRL measures and reward functions on performance
So, does it affect the results if the reward function is sparse or dense? The left figure below shows the results when the reward function is sparse and when it is dense, and the performance is high in both cases. The left figure below shows the results when the reward function is sparse and when it is dense. The right figure below shows a comparison of the network size of the policy, which also shows no significant performance difference.

Usefulness of the Visual RL benchmarks currently in primary use
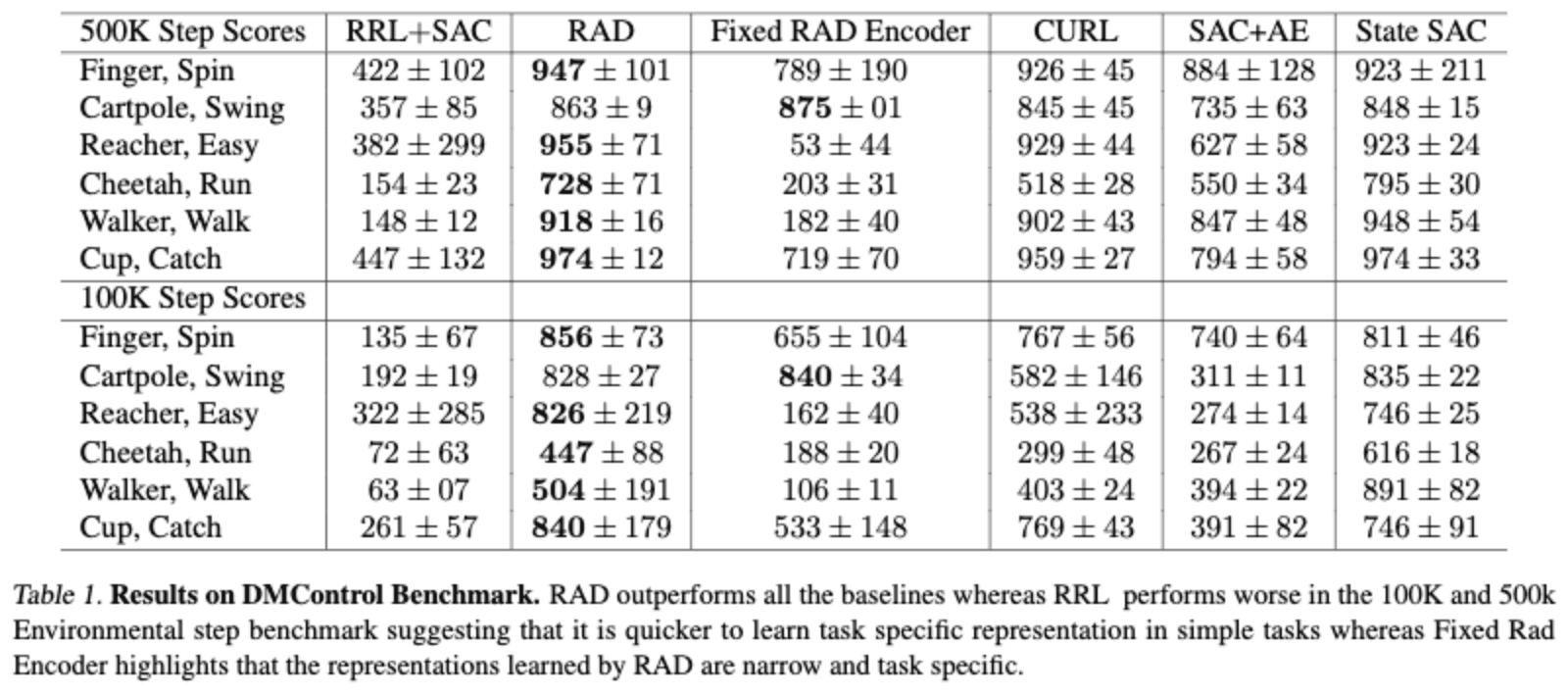
The DMControl environment is often used as a benchmark for RL using images as input (RAD, SAC+AE, CURL, DrQ, etc.). However, it has been shown that such methods work well on DMControld, but do not perform well on Adroit Manipulation benchmark. For example, FERM, which we introduced as a baseline, is trained by using Expert demonstration and RAD, but it is unstable or does not show good performance.
The table below shows the performance of the proposed method on the DMControl task, where the performance of methods such as RAD is higher than that of RRL on the DMControl task where the image information is less complex. The low performance of RRL is thought to be due to the large gap between the real world image data of ImageNet and the image information domain of DMControl, and we appeal for benchmarking tasks that are closer to real world images.
In addition, if we look at the Fixed RAD Encoder, which is an encoder trained on RAD using Cartpole data and RL agent on a task that provides similar image information, we see a significant performance drop compared to RAD, indicating that this Encoder is It is clear that the encoder is learning task-specific features, which shows the low versatility of the encoder. And such task-specific feature representations are easy to learn when the input is a simple image, but the more complex the image is, the more difficult it becomes.
Summary
In reinforcement learning, poor sample efficiency when using images as input is an important issue, and I introduced a paper that showed that sample efficiency can be improved by a very simple method: using ResNet features pre-trained on ImageNet. However, it is not effective if there is a large gap between ImageNet and the domain, and I am curious how well it will work, especially in experiments with robots in the real world. We also think that a large dataset covering a wide distribution, such as ImageNet for Robotics, would make for interesting research.



Categories related to this article






