
RT-1 Robot Learning System Operated From Images And Natural Language
3 main points
✔️ Robot learning system based on Transformer using a mobile robotic armRobotics Transformer 1
✔️ Robot arm motion generation and task management from images and natural language instructions
✔️ Real-time control model of the robot and real-world generalize the model using datasets from robot tasks.
RT-1: Robotics Transformer for Real-World Control at Scale
written by Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang-Huei Lee, Sergey Levine, Yao Lu, Utsav Malla, Deeksha Manjunath, Igor Mordatch, Ofir Nachum, Carolina Parada, Jodilyn Peralta, Emily Perez, Karl Pertsch, Jornell Quiambao, Kanishka Rao, Michael Ryoo, Grecia Salazar, Pannag Sanketi, Kevin Sayed, Jaspiar Singh, Sumedh Sontakke, Austin Stone, Clayton Tan, Huong Tran, Vincent Vanhoucke, Steve Vega, Quan Vuong, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Tianhe Yu, Brianna Zitkovich
(Submitted on 13 Dec 2022)
Comments: Published on arxiv.
Subjects: Robotics (cs.RO); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

The images used in this article are from the paper, the introductory slides, or were created based on them.
Introduction
Recently, you have heard a lot about technologies that use artificial intelligence in computer vision, natural language processing, and speech recognition. We have also probably seen more and more robots (drones and catering robots) that use these technologies. However, it is known that it is difficult to generalize machine learning models in robotics. One of the reasons for this is the need to collect data in the real world to generalize the models.
There are two challenges to generalizing models in robotics
- Collection of appropriate data sets - the need for data sets that are both large in scale and broad in scope to cover a variety of tasks and settings
- Design of appropriate models - need models that are efficient enough to operate in real-time and large enough to be suitable for multitask learning
As a solution to these issues, the Robotics Transformer 1 (RT-1) introduced in this article constructs a model capable of real-time control of robots, and by using a dataset obtained from a wide range of robot tasks in the real world, it gets closer to the generalization of the model.
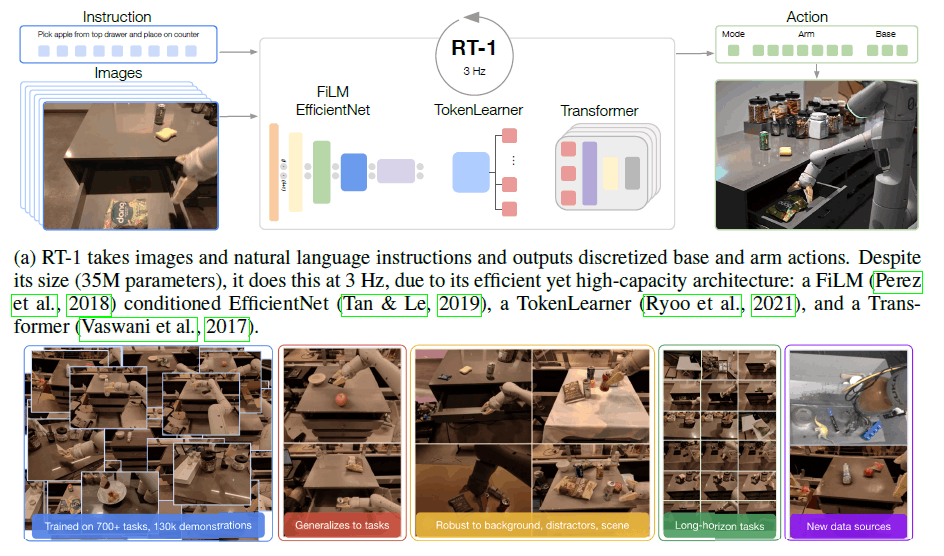
summary
The goal of this research is to build and demonstrate the performance of a general robot learning system that can capture large amounts of data and generalize effectively. The robot used is a mobile manipulator from Everyday Robots with a 7-DOF arm, a two-finger hand gripper, and a mobile base. (Figure (d) below)

RT-1 is an efficient model that can take in large amounts of data, effectively generalize it, and output actions at real-time rates for practical robot control. It takes short image sequences and natural language instructions as input and outputs robot actions at each time step.
RT-1 Architecture
The figure below shows the architecture of the RT-1 model. The components of the model are described at the top of the diagram.
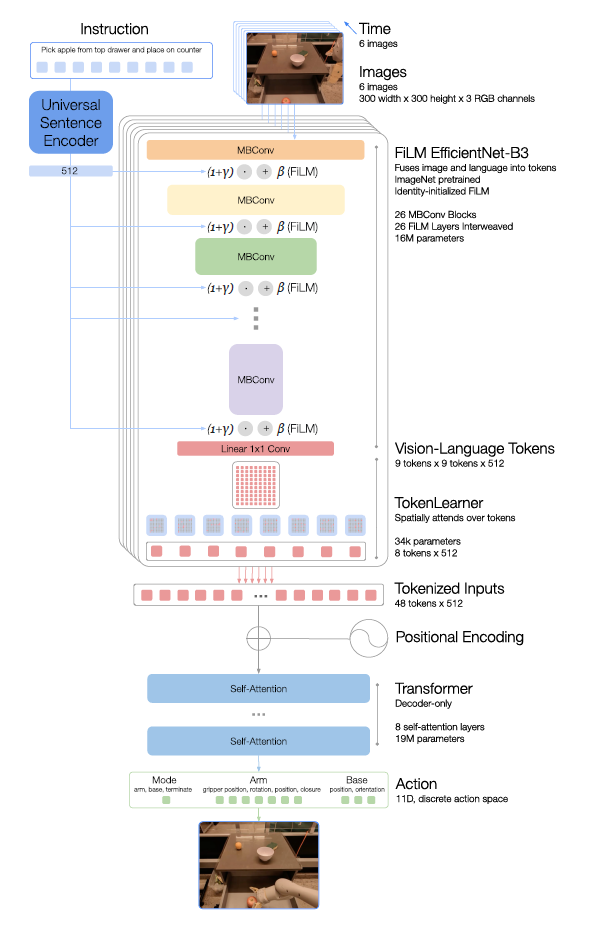
Instruction and image tokenization
The RT-1 architecture relies on data-efficient, compact tokenization of image and language instructions; Images is fed six images with a resolution of 300 × 300, and through ImageNet's pre-trained EfficientNet-B3 model, the last convolution layer produces a shape 9 ×x 9 x 512 spatial feature maps are output.
Instruction receives natural language as an instruction. This instruction is processed by the Universal Sentence Encoder for natural language processing and used as input for identity-initialized FiLM layers that are added to the pre-trained EfficientNet for image encoder conditioning.
TokenLearner
TokenLearner is used to further compress the number of tokens that RT-1 needs to attend to and to speed up inference; TokenLearner is an Element-Wise Attention module that learns to map a large number of tokens to a smaller number of tokens. This allows only important token combinations to be passed to the Transformer layer.
Transformer
Transformer is a decoder-only sequence model with 8 self-attention layers and 19M parameters to output action tokens.
Action tokenization
To tokenize actions, each action dimension in RT-1 is discretized into 256 bins. For each variable defined, such as robot arm motion, the target is mapped to one of the 256 bins.
Loss
We use the standard categorical cross-entropy entropy objective and causal masking utilized by Transformer-based controllers in related studies.
Inference speed
Set the inference time budget to less than 100 ms, which is close to the speed of a human performing the same action (approximately 2-4 seconds).
This process generates actions for the robot arm from the input images and instructions (natural language). The data set used and the instructions sent to the robot and the actions (skills) performed by the robot are also shown below.
data-set
The primary data set consisted of ~130k robot demonstrations collected over 17 months with 13 robots. This extensive data collection was conducted in an office kitchen, as shown in figures (a)-(c) below. In addition, a variety of objects were provided to add variety to the robot arm's movements, as shown in figures (e), and (f) below.
Skills and instructions
It counts the number of language instructions that the system can execute. The instructions correspond to verbs surrounded by one or more nouns and can be sentenced such as "Put the water bottle upright," "Transfer the Coke can to the bag of green chips," "Open the drawer," etc. RT-1 can execute over 700 verbal instructions in multiple real-life office kitchen environments evaluated in the experiment. RT-1 is capable of executing more than 700 verbal instructions in multiple real-life office kitchen environments evaluated in experiments.
Experiments and Results
The following experimental policy was established to determine the performance of the RT-1 model.
- Performance of visible tasks
- Generalization of tasks that are not visible
- robustness
- Long Horizon Scenario
Based on the above, we evaluated the RT-1 in three environments using Everyday Robots' mobile manipulators: two real office kitchens and a training environment that mimics these real kitchens. This article includes a comparison of RT-1 and baseline performance, as well as results when data on the simulation environment is added to the data set.
Overall performance comparison of RT-1 and Baseline
All models are trained on the same data as RT-1, and the evaluation does not compare task sets, datasets, or entire robotic systems, only model architectures.

In the category, RT-1 significantly outperforms its predecessors. In the look-and-do task, RT-1 succeeds in 97% of the more than 200 instructions, which is 25% higher than BC-Z and 32% higher than Gato. Such generalization to new instructions allows the policy to understand new combinations of pre-existing concepts. All baselines are also natural language conditioned, and in principle enjoy the same benefits.
An example trajectory for an RT-1 agent, including instructions covering different skills, environments, and objects, is shown in the board diagram.

Experimental results when simulation data is incorporated into RT-1

Compared to the Real Only data set, we can see that the performance does not decrease with the addition of simulation data. However, the performance for objects and tasks on the simulation has improved significantly, from 23% to 87%, which is almost the same performance as the real data. Performance on unknown instructions has also improved significantly, from 7% to 33%. This is an interesting result given that the object was verified on the real machine and the unknown instructions.
Conclusion
While RT-1 contributes to large-scale robot learning with Data-Absorbent models, it comes with several limitations. As an imitation learning method, it inherits the challenges of the approach, such as the possibility of not being able to exceed the performance of the demonstrator. In addition, generalization to new instructions is limited to combinations of previously seen concepts, and RT-1 is unable to generalize to completely unknown new behaviors.
However, RT-1 can be upgraded to further improve its robustness against backgrounds and environments. For this reason, RT-1 is open-sourced and anyone can contribute to its development.
We believe that the development of RT-1 technology not only by researchers but also by companies and general users will enable the construction of models from various perspectives and further generalization. If various technologies can be integrated and robot models can be generalized, it will not be long before robots are commonplace on the streets of our daily lives.



Categories related to this article



![[HumanoidBench] Simu](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/June2024/humanoidbench-520x300.png)

