
VLMaps To Improve Accuracy By Labeling Directly On 3D Maps
3 main points
✔️ VLMap:spatial map representation combiningreal-world 3D mapswith pre-trainedVisual-Languagemodel features
✔️ Combined with LLM, mobile robots can generate actions
✔️ Extensive experiments show that following more complex language instructions than existing methods Navigation is possible
Visual Language Maps for Robot Navigation
written by Chenguang Huang, Oier Mees, Andy Zeng, Wolfram Burgard
(Submitted on 11 Oct 2022 (v1), last revised 8 Mar 2023 (this version, v4))
Comments: Accepted at the 2023 IEEE International Conference on Robotics and Automation (ICRA)
Subjects: Robotics (cs.RO); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
Introduction.
In recent years, there has been a lot of research on robot behavior generation with artificial intelligence. For example, there are many cases of action generation in which a person orders a mobile robot to "bring an apple on the desk" and the mobile robot brings it. Such mobile robot action generation uses natural language processing to process the commands and image processing artificial intelligence to recognize objects. Pre-trained Visual-Language models can be used for such navigation.
However, while existing Visual-Language models are useful for matching images with natural language descriptions of object goals, they remain disconnected from the process of mapping the environment and thus lack the spatial accuracy of geometric maps.
The VLMaps presented in this article are spatial map representations that address these issues by combining pre-trained Visual-Language model features with a 3D reconstruction of the physical world.
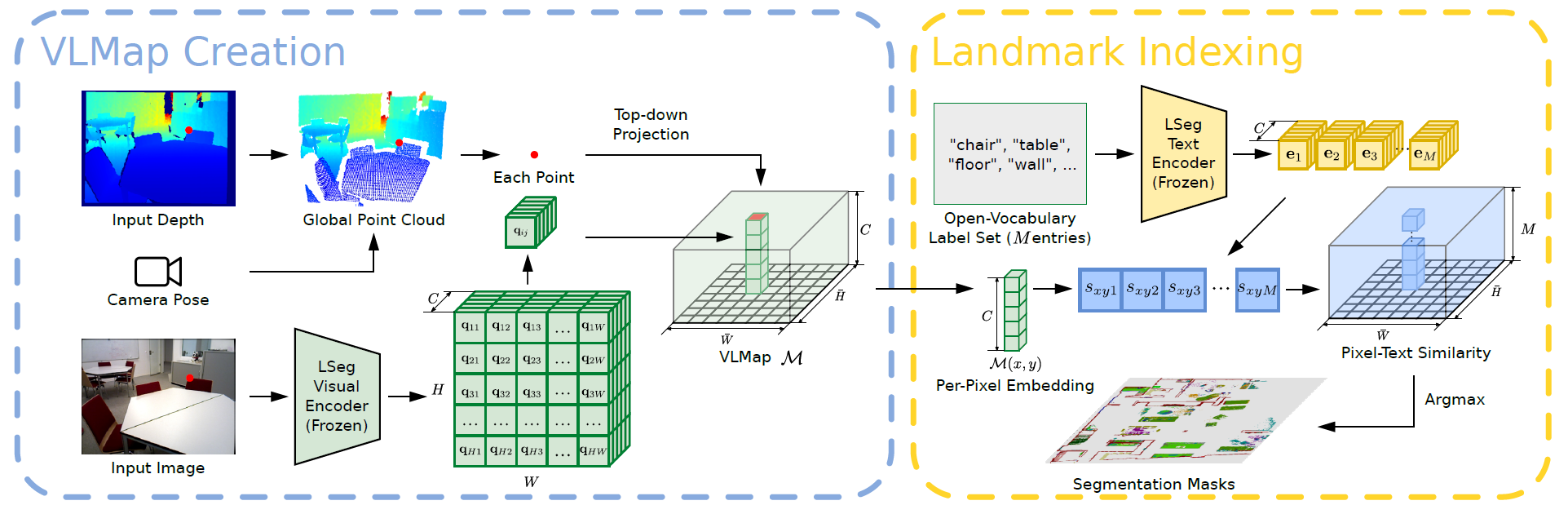
VLMaps Overview
VLMaps is a spatial map representation that addresses these issues by combining pre-trained Visual-Language model features with a 3D reconstruction of the physical world.
It can be constructed autonomously from the robot's video feed using standard search approaches, allowing for natural language indexing of the map without additional labeled data.

Specifically, when combined with a large-scale language model (LLM), it allows
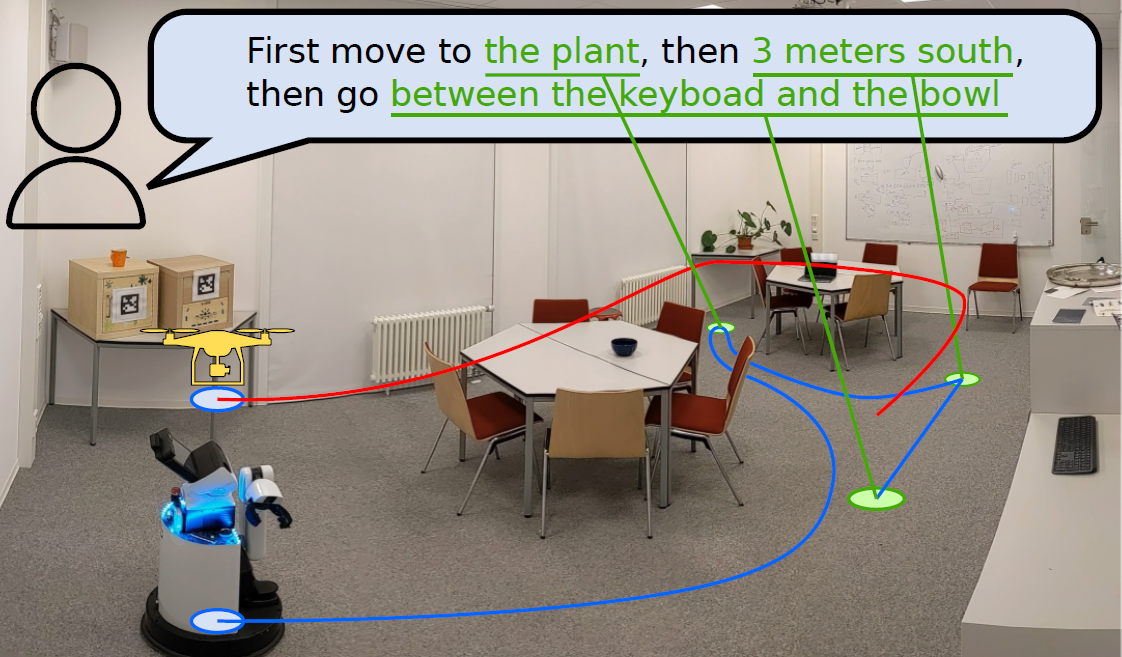
- Convert natural language commands into a sequence of open-vocabulary navigation goals that are localized directly into the map. For example, "between the sofa and the TV" or "3 meters to the right of the chair".
- To generate a new obstacle map without prior preparation, a list of obstacle categories can be used, which can be shared among multiple robots with different implementations.
VLMaps Methods
The goal of VLMaps is to build spatial visual-language map representations that can directly identify landmarks ("sofa") and spatial references ("between sofa and TV") in natural language. VLMaps can be constructed using off-the-shelf visual-language models (VLMs) and standard 3D reconstruction libraries.
 We will now describe the methods of VLMaps, divided into the following sections.
We will now describe the methods of VLMaps, divided into the following sections.
- How to build VLMaps
- How to localize open-vocabulary landmarks using maps
- Method of constructing an open-vocabulary obstacle map from a list of obstacle categories for different robot embodiments
- How VLMaps are used in conjunction with Large Language Models (LLMs) to perform zero-shot spatial goal navigation of real robots from natural language commands
Building a Visual-Language Map
The main idea of VLMaps is to fuse pre-trained visual language features with 3D reconstruction. This is accomplished by computing high-density pixel-level embeddings on the robot's video feed from existing visual language models and back-projecting them onto the 3D surface of the environment captured from the depth data.
VLMaps uses LSeg as the visual language model, a language-driven semantic segmentation model that segments RGB images based on a set of free-form linguistic categories.
The VLMaps approach fuses the pixel embedding of LSeg with the corresponding 3D map locations. This incorporates a powerful language-driven semantic prior with the generalization capabilities of VLMs, without the use of explicit manual segmentation labels.
where H and W represent the size of the top-down grid map and C is the length of the VLM embedding vector for each grid cell. Together with the scale parameter s, VLMapsM represents an area the size of H ×W meters.
To construct the map, for each RGB-D frame, all depth pixels u are back-projected to form a local depth point cloud, which is then converted to a world frame.
Project point PW onto the ground plane to obtain the corresponding position of pixel u on the grid map. Below are the formulas for px map andpy map, which represent the coordinates of the projected point in map M.
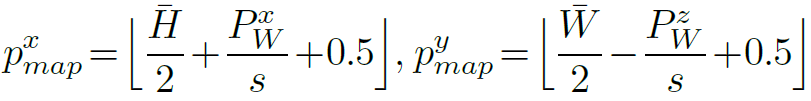
Localizing Open-Vocabulary Landmarks
This section describes how to localize VLMaps landmarks using free-form natural language.
The input language list could be ["chair", "sofa", "table", "other"] or ["furniture", "floor", "other"]. To convert such text lists into vector embedded lists, a pre-trained CLIP text encoder is applied. The map embedding is also flattened into a matrix. In addition, each row represents the pixel embedding in the top-down grid map.
The final matrix is used to compute the most relevant language-based category for each pixel in the grid map.
Generating Open-Vocabulary Obstacle Maps
By building VLMaps, obstacle maps can be generated that inherit the open-vocabulary nature of the VLMs used (LSeg and CLIP). Specifically, it is because, given a list of obstacle categories described in natural language, they can be localized at runtime to generate binary maps for collision avoidance and shortest path planning. A prominent use case for this is the sharing of VLMaps of the same environment between robots with different implementations, which is useful for multi-agent coordination.
For example, simply providing two different lists of obstacle categories, one for large mobile robots (including "table") and one for drones (not including "table"), two different obstacle maps to be used by each of the two robots can be generated from the same VLMaps without prior preparation The two maps can be generated from the same VLMaps without any prior preparation.
To do so, we first extract the obstacle map O where each projected position of the depth point cloud in the top-down map is assigned a 1, otherwise a 0.
To avoid points from the floor or ceiling, point PW is filtered according to its height.
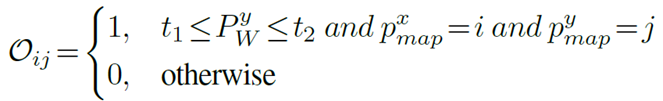
Next, to obtain an obstacle map for a given implementation, a list of potential obstacle categories is defined. open-vocabulary landmark indexing is applied to obtain a segmentation mask of all defined obstacles. For a particular implementation, select a subset of classes from the entire list of potential obstacles and take the sum of their segmentation masks to obtain the obstacle mask; ignore false predictions of obstacles on the floor area of O by taking their intersection with O to obtain the final obstacle map.
Zero-Shot Spatial Goal Navigation from Language
This section describes our approach to long horizon (spatial) goal navigation given a set of landmark descriptions specified by natural language instructions such as

VLMaps can refer to precise spatial goals such as "between the TV couch" or "3 meters east of the chair." Specifically, LLMs are used to interpret incoming natural language commands and decompose them into subgoals. Referencing these subgoals in the language and using semantic translation and affordances, LLM's code-writing capabilities are leveraged to generate executable Python code for the robot.
The code for the robot can represent functions and logical structures and parameterize API calls. At test time, the model can then take in new commands and autonomously reconfigure the API calls to generate new robot code, respectively.
In the two figures below, the prompt is gray, the input task command is green, and the generated output is highlighted.
 |
 |
LLMg not only references the new landmarks mentioned in the language commands, but also generates code that follows the unknown instructions by chaining new API call sequences.
The navigation primitive function called by the language model then uses the pre-generated VLMaps to identify the coordinates of the open-vocabulary landmarks in the map, modified by the offsets defined in the pre-script. It then navigates to these coordinates using a ready-made navigation stack with a body-specific obstacle map as input.
experiment
This article presents a baseline comparison of VLMaps and the results of an actual adaptation to a mobile robot.
Baseline Comparison
We quantitatively evaluated the VLMaps approach against recent open vocabulary navigation baselines in the standard task of multi-object goal navigation.
To evaluate object navigation, 91 task sequences were collected. In each sequence, the starting position of the robot in one scene is randomly specified and four of 30 object categories are selected as subgoal object types.
The robot is required to navigate through these four subgoals sequentially. In each sequence of subgoals, when the robot reaches one subgoal category, it must call a stop action to indicate its progress.
Navigation to one subgoal is considered successful if the distance of the stop from the correct object is within one meter.
To assess the agent's ability to navigate the long horizon, we calculated the success rate (SR) of reaching from one to four subgoals in a row (see figure below).
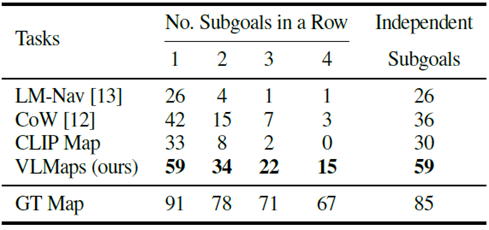
In multi-object navigation (success rate [%]), the VLMaps approach outperforms other open-vocabulary baselines, especially in long horizon tasks with multiple subgoals.
LM-Nav also performs poorly because it can only navigate to locations represented by images stored in graph nodes. To better understand the map-based approach, the object masks generated by VLMaps, CoW, and CLIP Map are shown below, compared to GT.

The masks generated by CoW (Figure: 4d) and CLIP (Figure: 4c) both contain significant false positive predictions. Since planning generates paths to the nearest masked target area, these predictions lead to planning toward the wrong target. In contrast, the predictions generated by VLMaps, shown in Figure: 4e, are less noisy and result in more successful object navigation.
Experiments with mobile robots
We also conducted real-world experiments with HSR mobile robots for indoor navigation with natural language commands, testing VLMaps in semantically rich indoor scenes containing more than 10 different classes of objects. We defined 20 different language-based spatial targets for testing.
During inference, the global localization module of RTAB-Map is also used to initialize the robot pose.
The results showed success in six trials with spatial targets such as "move between the chair and the crate" and "move south of the table," and in three trials with targets relative to the robot's current position such as "move 3 meters to the right and then 2 meters to the left."
Conclusion
How was it? The VLMaps discussed in this article are designed to directly adapt the features of a pre-trained Visual-Language model to a 3D map, so that objects can be explicitly recognized where they are located on the map. In the future, research is expected to add other information to further improve the accuracy of VLMaps.
In addition, the system can be combined with LLM to generate actions for mobile robots. In the future, it is likely to be applied not only to action generation for robots, but also to automatic driving of automobiles.



Categories related to this article



![[HumanoidBench] Simu](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/June2024/humanoidbench-520x300.png)

