
Should The Kernel Size For CNN Be Larger?
3 main points
✔️ Proposed CNN architecture with 31x31 large kernels
✔️ Successfully scaled kernels with 5 guidelines including the use of Depth-Wise convolution
✔️ Demonstrates superior downstream task transition performance for pre-trained models
Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
written by Xiaohan Ding, Xiangyu Zhang, Yizhuang Zhou, Jungong Han, Guiguang Ding, Jian Sun
(Submitted on 1 Jul 2021)
Comments: CVPR2022
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
code:

The images used in this article are from the paper, the introductory slides, or were created based on them.
first of all
In a typical convolutional neural network (CNN), a large receptive field is built by stacking small kernels such as 3×3.
On the other hand, in Vision Transformers (ViT), which have recently seen significant development, Multi-Head Self-Stention (MHSA) has achieved a large receptive field even with only a single layer.
In light of these successes of ViT, the question arises whether CNNs can be made to approach ViT by using a small number of large kernels instead of the existing CNN policy of many small kernels to achieve a large receptive field.
Based on this question, in the paper presented in this article, we proposed RepLKNet, a CNN architecture that uses a kernel size of 31×31, which is larger than that of a typical CNN. As a result, we demonstrated excellent performance, including 87.8% Top-1 accuracy on ImageNet and a significant improvement in downstream task performance.
Guidelines for applying large kernels
Simply applying large convolutions to CNNs can lead to performance and speed degradation. Therefore, we introduce five guidelines for effectively using large kernels.
Guideline 1: Large depth-wise convolutions are more efficient in practice.
Using large kernels is computationally expensive because the number of parameters and FLOPs increases quadratically with kernel size, but this drawback can be significantly improved by applying Depth-Wise (DW) convolution.
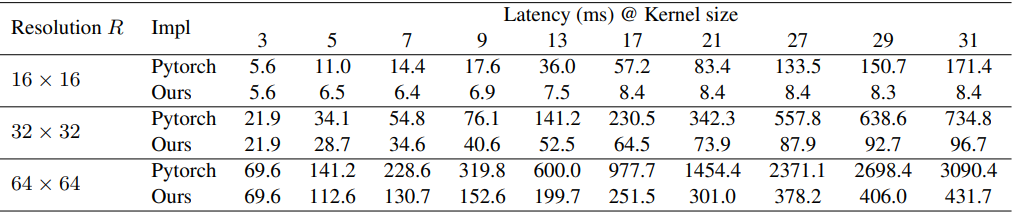
In the proposed method, RepLKNet (details to follow), increasing the kernel size from [3,3,3,3] to [31,29,27,23], the FLOPs and the number of parameters can be reduced to 18.6% and 10.4%, respectively. One concern is that DW convolutional operations may become very inefficient on modern parallel computers such as GPUs. However, since the ratio of memory accesses decreases as the kernel size increases, the actual latency is not expected to grow as large as the increase in FLOPs.
remarks
Common deep learning tools such as Pytorch do not handle large DW convolutions well, so the paper uses an improved implementation as shown in the table below.
Guideline 2: identity shortcuts are essential for networks with large kernels.
Using MobileNet V2 with DW convolution as a benchmark, the results are shown below with 3x3 or 13x13 kernels applied.

As shown in the table, the performance is improved by using a larger kernel when shortcuts are available, but the accuracy is reduced when they are not used.
Guideline 3: Reparameterizing with a small kernel (re-parameterizing()) can improve optimization problems.
If we replace the kernel size of MobileNet V2 with 9x9 and 13x13 and also apply Structural Re-parameterization() method, we can improve the performance as shown in the following table.
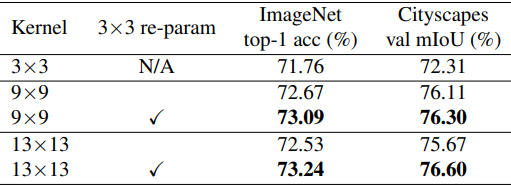
The method is as follows: a large kernel layer and a 3x3 layer are built in parallel, and after training, the Batch Normalization layer and the 3x3 kernel are fused into a large kernel.

Thus, the optimization can be improved by using the re-parameterizing technique.
Guideline 4: Large convolution improves downstream task performance over Imagenet classification accuracy.
The table above shows the performance of a model pre-trained on ImageNet and trained by a metastatic DeepLabv3+() semantic segmentation task on Cityscapes. The accuracy of ImageNet is improved by 1.33% by increasing the kernel size to 9x9, while Cityscapes mIoU improves by 3.99%.
(This trend was also observed in the experimental results of RepLKNet proposed in the paper, which may be because larger kernels lead to an increase in the effective receptive field and shape bias.)
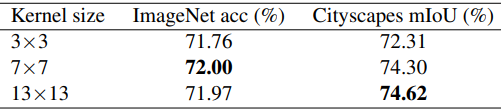
Guideline 5: Large kernels (e.g. 13x13) are valid even when the feature map is small (e.g. 7x7).
For MobileNet V2, the following results are obtained when the kernel size is set large for the feature map.
Based on these five guidelines, a CNN architecture called RepLKNet is proposed in the paper.
Proposed method: RepLKNet
RepLKNet is a pure CNN architecture with a large kernel design and consists of
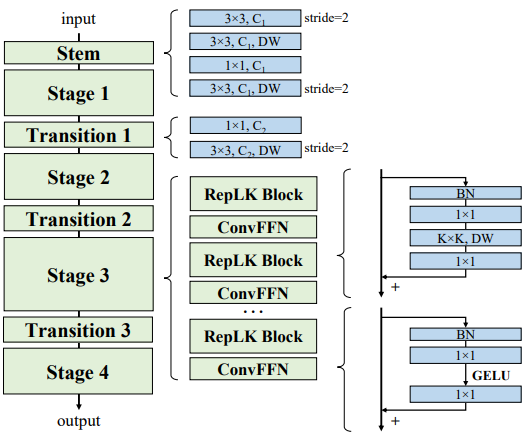
The RepLKNet architecture consists of Stem, Stage, and Transition blocks.
Stem
The stem is the first layer and is designed to allow the first multiple conv layers to obtain detailed information so that high performance can be obtained in the downstream high-density prediction task. As shown in the figure, after the 3x3 convolution and 2x downsampling, the DW3x3 layer, 1x1 convolution, and DW3x3 layer for downsampling are arranged in this order.
stage
Stages 1-4 each contain multiple RepLK blocks and use shortcuts and large kernels of DWs (see Guideline 2,1). Before and after DWconv uses 1x1 convolution, and each DW layer uses a 5x5 kernel for reparameterization (see guideline 3).
Transition block
Transition blocks are placed between stages, with 1x1 convolution for larger channels and DW3x3 convolution for 2x downsampling. In general, RepLKNet has three architectural hyperparameters: the number of RepLK blocks $B$, the channel dimension $C$, and the kernel size $K$. Therefore, the architecture of RepLKNet is defined by $[B1,B_2,B_3,B_4],[C_1,C_2,C_3,C_4],[K_1,K_2,K_3,K_4]$.
experimental results
First, we evaluate the case where the RepLKNet hyperparameters are fixed at $B=[2, 2, 18, 2], C=[128, 256, 512, 1024]$ and $K$ is varied.
Let RepLKNet-13/25/31 where the kernel sizes $K$ are [13, 13, 13, 13], [25, 25, 25, 13], [31, 29, 27, 13] respectively. We also construct a small kernel baseline RepLKNet-3/7, where the kernel sizes are all 3 or 7.
The performance in ImageNet and the semantic segmentation task (ADE20K) performance when the backbone is a model trained on ImageNet are as follows.
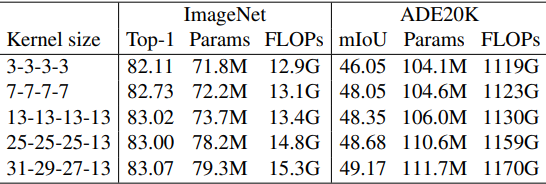
The ImageNet results show that increasing the kernel size from 3 to 13 improves the accuracy, but increasing the kernel size further does not improve the performance.
On the other hand, the performance increases for ADE20K, indicating that larger kernels are important for downstream tasks. In the following experiments, we refer to RepLKNe-31B as the model with the largest kernel size among the settings above and RepLKNet-31L as the model with $C=[192, 384, 768, 1536]$.
Also, $C=[256, 512, 1024, 2048]$ and the DW convolutional layer channel of the RepLK block is set to 1.5 times the input as RepLKNet-XL.
ImageNet Classification Performance
Next, we compare the ImageNet classification performance with Swin, which has similar overall architecture.
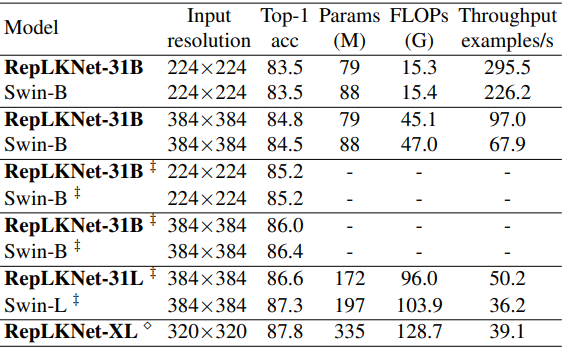
The ‡ mark indicates the case where the image is pre-trained on ImageNet-22K and then fine-tuned on ImageNet-1K, while the unmarked case is trained only on ImageNet-1K.
In general, the results show that although large kernels are not suitable for ImageNet classification as before, RepLKNet shows a good trade-off in terms of accuracy and efficiency. In particular, RepLKNet-31B trained on ImageNet-1K shows good performance, achieving 84.8% accuracy, which is higher than Swin-B, and running 43% faster.
semantic segmentation performance
Next, the results for Cityscapes and ADE20K using the pre-trained model as the backbone are shown below, respectively.
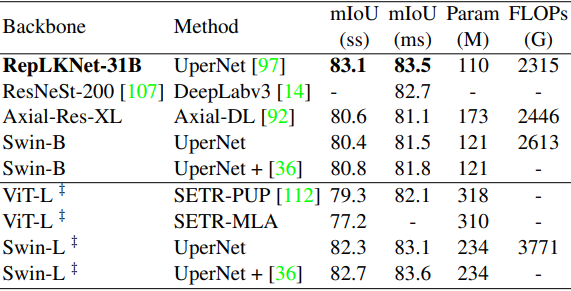
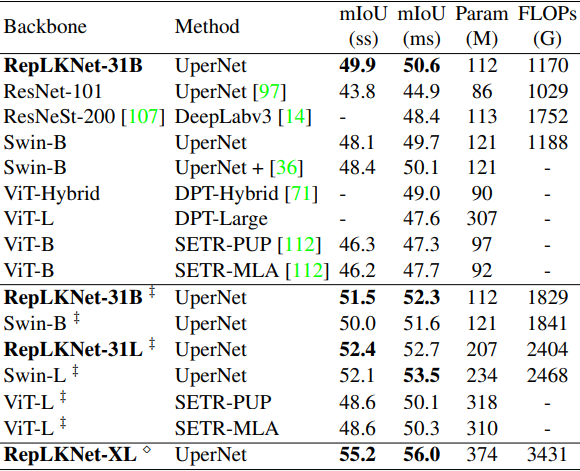
‡ mark indicates pre-trained on ImageNet-22K, and unmarked indicates pre-trained on ImageNet-1K.
In general, RepLKNet-31B outperformed the existing methods and showed very good results. In particular, RepLKNet-31B outperformed Swin-L, which was pre-trained with ImageNet22K, in Cityscapes.
Object detection performance
Next, the results for the object detection task are as follows
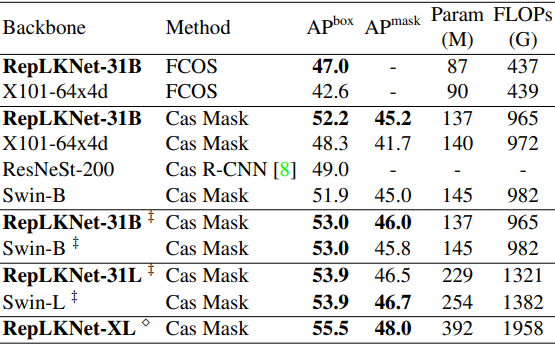
In general, the results show that the proposed method can achieve the same or better performance with fewer parameters and FLOPs than the existing methods by simply replacing the backbone, which indicates the high downstream task performance of the proposed method.
Why is a big kernel effective?
The paper discusses the effectiveness of using large kernels by saying
- 1) CNNs with large kernels have larger ERFs (effective receptive fields) than CNNs with small kernels.
According to the theory of ERF (Effective Receptive Field)(), ERF is proportional to $O(K \sqrt(L))$ ($K$ is the kernel size and $L$ is the number of layers), and the size of kernel leads to the size of the effective receptive field.
In addition, the deep number of layers leads to difficulty in optimization, so by using a large kernel, we can obtain a large ERF with fewer layers that are easier to optimize. The result of visualizing ERFs is shown in the following figure.
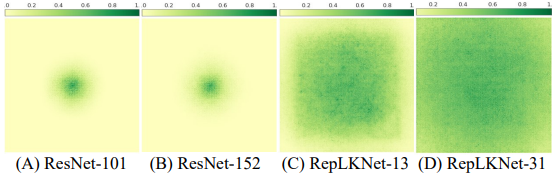
- 2) Large kernel models have a shape bias similar to humans.
- 3) The large kernel design is a generic design element that works with ConvNeXt.
- 4) Larger kernels outperform smaller kernels with higher dilation rates.
(See Appendices C, D, and E of the original paper for more details on these.)
summary
Increasing kernel size has long been neglected in the design of CNN architectures.
In the paper presented in this article, the use of large convolutional kernels, based on five guidelines, has led to significant performance gains, especially in downstream tasks.
The results of this study show that the Effective Receptive Field deserves attention in CNN design and that large convolutionalization significantly reduces the performance gap between CNN and ViT.



Categories related to this article






