
Model Lightweight Techniques! Lightweight And High Performance Speech Emotion Recognition Model LightSER-NET!
3 main points
✔️ LightSER-NET, a model for speech emotion recognition, was accepted to ICASSP2022
✔️ Successful weight reduction with simple structure using 3 parallel CNNs
✔️ Achieve SOTA-like performance while reducing weight
Light-SERNet: A lightweight fully convolutional neural network for speech emotion recognition
written by Arya Aftab, Alireza Morsali, Shahrokh Ghaemmaghami, Benoit Champagne
(Submitted on 7 Oct 2021)
Comments: ICASSP 2022
Subjects: Audio and Speech Processing (eess.AS); Signal Processing (eess.SP)
code:

The images used in this article are from the paper, the introductory slides, or were created based on them.
first of all
Techniques for detecting human emotions such as joy, sadness, and surprise directly from speech signals play an important role in human-computer interaction. Existing research, as well as many deep learning models, require a large amount of computational cost, which makes it difficult to integrate them into real systems and use them in applications.
Therefore, in this study, we use three types of parallel CNNs with different filter sizes to simultaneously achieve high-performance and lightweight models using only CNN structures.
Three parallel CNNs are separately responsible for three types of feature extraction: frequency, time-series, and frequency-time-series, which are effective for speech recognition and achieve high dimensional feature extraction. Finally, the resulting feature maps are used for classification to simultaneously achieve model weight reduction and performance comparable to SOTA.
architecture

The overall system consists of three main parts: an input pipeline, a feature extraction block (Body), and a classification block (Head ). Furthermore, the Body part consists of parallel 2D convolution ( Body Part I) and local Feature Learning Blocks (LFLBs).
input pipeline
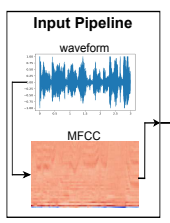
After standardizing the speech signal between -1 and 1, the MFCC is computed. Here, the MFCC is derived by processing the Hamming window function, fast Fourier transform, Melfilter bank, inverse Cosine transform, etc., as well as general processing.
Body Part I
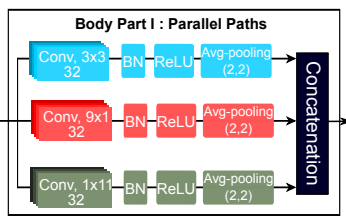
In this step, parallel CNNs are applied to MFCCs to extract features in time-series and frequency direction in a well-balanced manner. It is also known that widening the receptive field of the convolutional network improves the classification performance. In this research, the following innovations are made to widen the receptive field.
- Increase the network layer
- Using subsampling blocks such as pooling and larger strides
- Using dilated convolution
- Using depth-wise convolution
Moreover, for multi-dimensional signals, each dimension can compute the receptive fields separately. So, in this research, we use 9×1,1×11 and3×3 kernels to extract features in frequency, time series, and frequency-time series direction respectively.
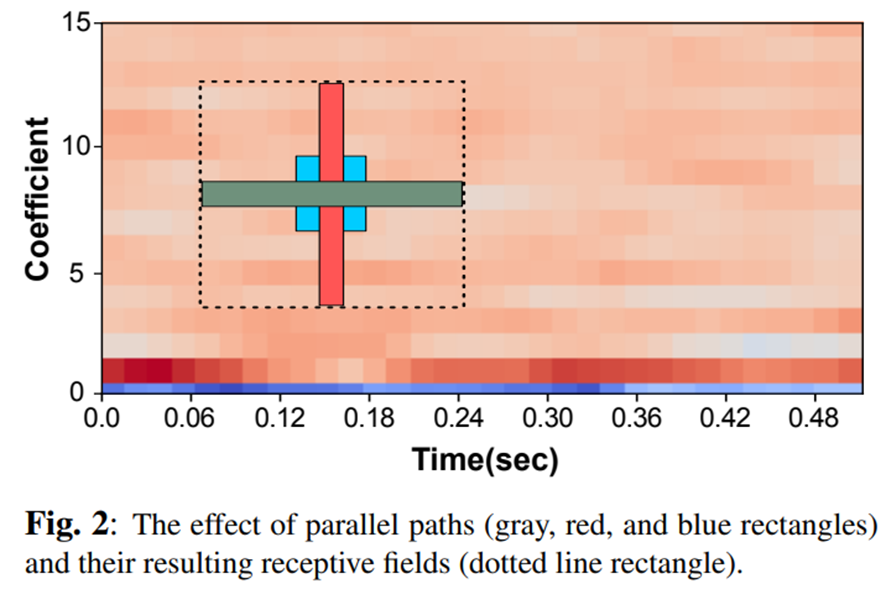
By using this technique of having only one path with the same receptive field size, the number of parameters can be reduced and the computational cost can also be reduced. The figure below shows the receptive field size with parallel CNN.
Body Part II
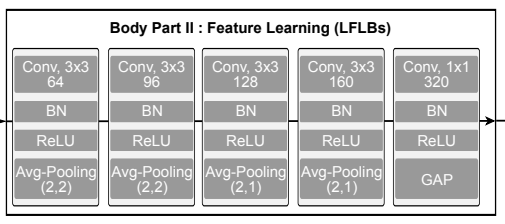
Body Part II consists of several local feature learning blocks and adapts to the features extracted in Body Part I. It consists of a convolutional layer, a batch normalization layer, a ReLU, and a max pooling layer.
In the last block, global average pooling (GAP) is used to allow training on datasets of different lengths without changing the architecture.
head
The body part maps the nonlinear input to linear space, so the all-coupling layer only requires classification. Therefore, the usual dropout layer and softmax functions keep the computational cost low.
experiment
data-set
We have experimented with IEMOCAP and EMO-DB, which are commonly used for speech emotion recognition.IEMOCAP is a multimodal dataset of audio and video, each of which is assigned four labels: happiness, sadness, angry, and natural.
EMO-DB is a German dataset with 10 professional voice actors and is labeled with 7 labels: angry, natural, sadness, fear, disgust, happiness, and boredom.
experimental results
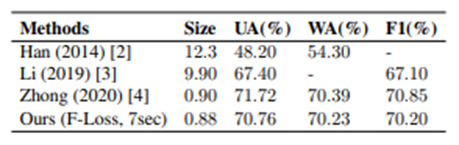
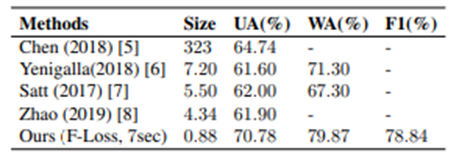
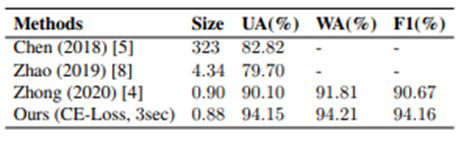
To deal with the bias of the data among the classes in the dataset, we evaluate the data using three metrics: unweighted accuracy (UA), weighted accuracy (WA), and F1-score (F1).
The performance comparison with other speech emotion recognition models is shown in the figure below. It can be seen that the model size is reduced and the performance is comparable to SOTA.
Conclusion.
In this study, three parallel CNNs with different filter sizes are used for effective and lightweight feature extraction.
The lightweight and fast response of the model is essential when integrating it into an application, and we believe that the contents of this presentation will be helpful for those who are working on speech recognition in a practical area.



Categories related to this article






![[wav2vec 2.0] Facebo](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/November2020/Facebook_AIが公開_wav2vec_2.0_2-min-520x300.png)