[wav2vec 2.0] Facebook AI Unveils A New Speech Recognition Framework! Self-supervised Learning Achieves High Accuracy Without Correct Answer Labels!
3 main points
✔️ Facebook AI releases new speech recognition framework, wav2vec 2.0
✔️ Self-supervised learning with a small amount of transcribed and unlabeled speech
✔️ Highest accuracy for both unlabeled and labeled data
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
written by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
(Submitted on 20 Jun 2020 (v1), last revised 22 Oct 2020 (this version, v3))
Comments: Accepted at NeurIPS 2020
Subjects: Computation and Language (cs.CL); Machine Learning (cs.LG); Sound (cs.SD); Audio and Speech Processing (eess.AS)


Introduction
Facebook AI has released a new speech recognition framework, wav2vec 2.0. The code is also available and is ready for anyone to use right now. The great thing about this paper is that it makes full use of self-supervised learning to achieve high accuracy with only a small amount of transcribed and unlabeled speech data. Previous methods have required thousands of hours of transcribed speech to achieve practical accuracy, but in practice, it is very difficult to obtain transcribed speech in many situations. In fact, such correct data is difficult to obtain for more than 7000 languages.
This is where self-supervised learning comes in. Self-supervised learning is a method that learns a representation from correct labeled data and fine-tunes the model with correct labeled data. In this paper, we encode speech with multiple layers of CNNs to mask latent representations. The latent representation is conveyed to the Transformer network to build a contextualized representation. The model is then trained through contrast learning to distinguish correct and incorrect features.
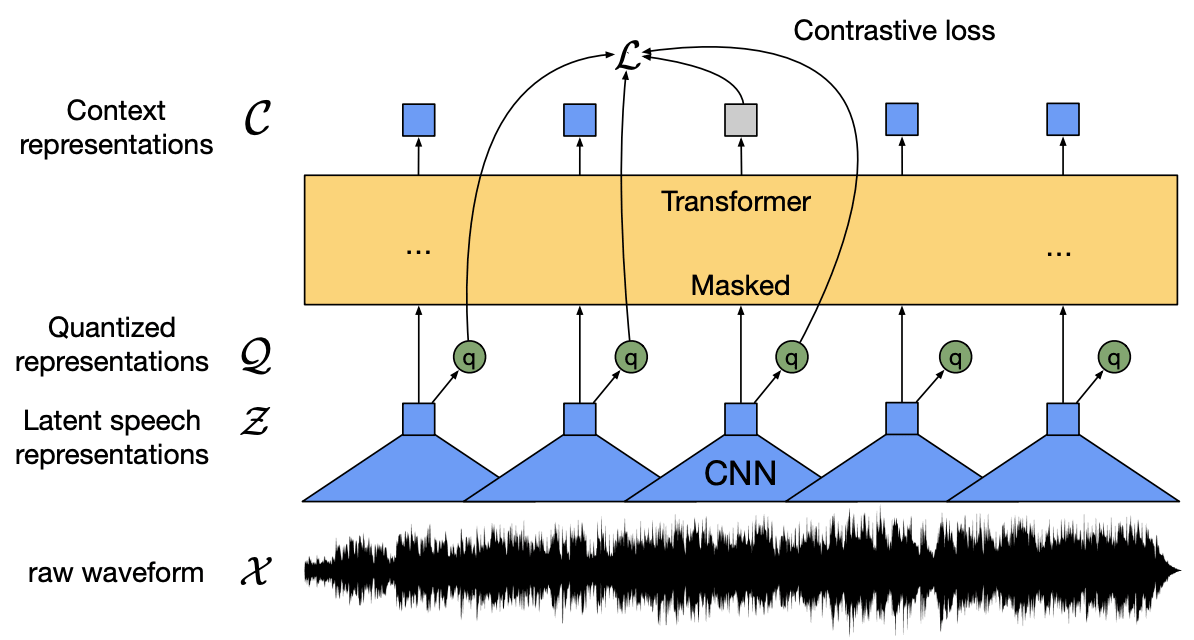
In the training part, we separated the speech units through gumbel softmax, which represents a latent representation in contrast training. We found this contrastive learning to be more effective than quantizing the target without quantization. After pre-training with unlabeled speech, the model was fine-tuned with labeled data by Connectionist Temporal Classification (CTC) loss and used for a speech recognition task.
To read more,
Please register with AI-SCHOLAR.
OR


Categories related to this article






