超音波エコー映像とディープラーニングを用いて口パクから音声を合成
東京大学とソニーコンピュータサイエンス研究所による研究チームは、 声を出すことなく口パク動作を行うだけで発話内容を認識する、声を出さない音声UI「SottoVoce」を提案しました。本提案は、超音波エコー映像とdeep learningを組み合わせることによって、口パクから音声を合成します。
参照 SottoVoce: An Ultrasound Imaging-Based Silent Speech Interaction Using Deep Neural Networks
声を出さない音声UI、SottoVoceとは
音声によって操作されるデジタル機器の利用可能性は急速に拡大していますが、しかし,音声インタフェースの使用状況は依然として制限されています。たとえば,公共の場で話すことは周囲の人に迷惑になり、秘密の情報を話すことができません。
そこで、研究チームは、口パクから、超音波エコー映像を用いて、利用者の無発声音声を検出するシステム、SottoVoce (ソット・ヴォーチェ、音楽用語で 「ささやくように」)を提案しました。
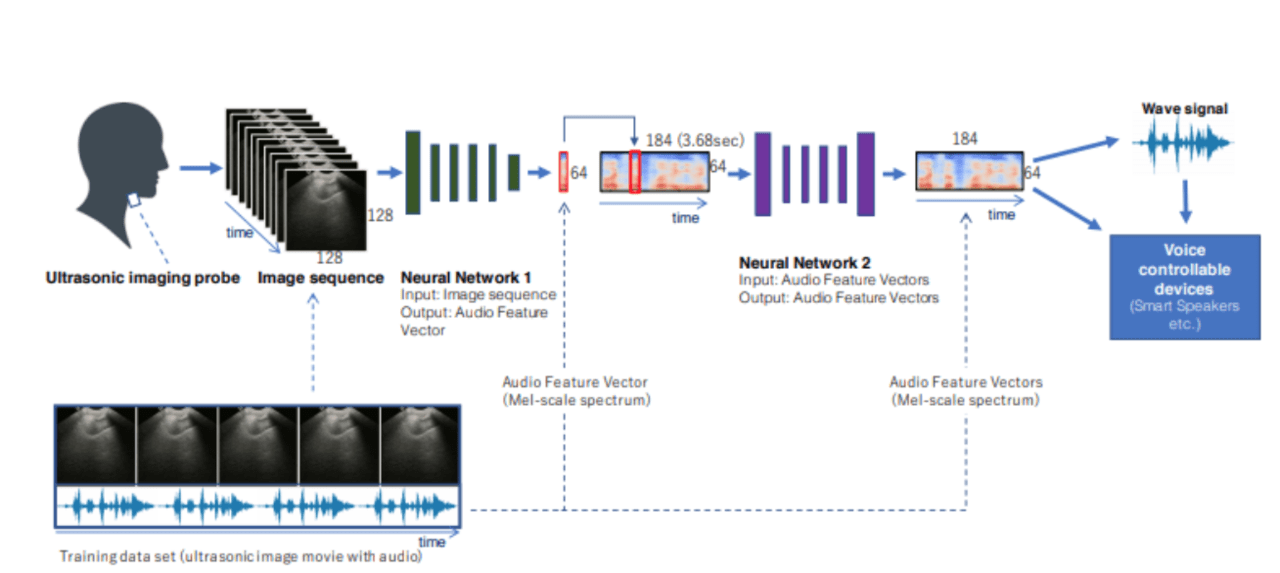
顎の下側に取り付けられた超音波イメージングプローブによって観察される口腔内の情報から、利用者が声帯を振動させずに発話した発声内容を認識。得られた超音波画像をCNNに通すことで、オーディオスピーカから合成音声を出力します。
①超音波エコー映像を用いて口パクから音声情報を計測
②得られた超音波画像をCNNによってベクトル情報に変換
③ベクトル情報をGriffin Lim手法により、音声波形に復元し、オーディオスピーカーで出力
この提案モデルにより,合成したオーディオ信号が Amazon Echo など、既存のスマートスピーカーをコントロールできることを確認したといいます。これにより、人間とコンピュータが緊密に連携した種々のインタラクションが可能になり,新しいウェアラブルコンピュータが構成可能になりました。また、咽頭の障害,声帯機能障害,高齢による発声困難者に対して、声によるコミュニケーションを取り戻すための技術基盤につながるかもしれません。
また、SottoVoceを使うと、利用者のほうから口パクを調整してうまく音声になるように歩み寄る傾向があったとのこと。これは、ニューラルネットが学習しているだけでなく、ニューラルネットによって外在化された人間自身の能力を、人間側も学習していることになります。人間とAIとが一体化した新しいインタラクションの方向を示しているともいえるのではないでしょうか。研究チームはこれを「ヒューマン・AI・インテグレーション」と呼び、今回のような無発声発話だけではなく、楽器の習得や語学習得などにも展開可能だと考えているそう。



この記事に関するカテゴリー