強化学習のタスクを分割して複雑なタスクを解く新しいアルゴリズム!
3つの要点
✔️ Task ReductionとSelf-Imitationにより複雑なタスクを効率よく解けるSIRを提案
✔️ スパースな報酬の問題に対して有効
✔️ 比較手法と比べてmanipulation taskやmaze taskにて高いパフォーマンスを示す
Solving Compositional Reinforcement Learning Problems Via Task Reduction
written by Yunfei Li, HUazhe Xu, Yilin Wu, Xiaolong Wang, Wi Wu
(Submitted on 26 Jan 2021)
Comments: Accepted to OpenReview
Subjects: compositional task, sparse reward, reinforcement learning, task reduction, imitation learning


Datasets

はじめに
ICLR 2021にアクセプトされた論文を紹介します。近年、強化学習は複雑なタスクを解くことが出来るようになってきましたが、ほとんどの手法において、注意深くデザインされた報酬関数が必要となります。このような報酬関数は、そのタスクのドメイン特有の知識が必要となるという問題点があります。もしくは、Hierarchical RL (階層型強化学習)のような、low-level skillsを学習しhigh-level policy (方策)がどのskillを使うかを学習するような手法がありますが、そのようなlow-level skillsを学習するのは簡単な問題ではありません。本記事では、Self-Imitation via Reduction (SIR)と呼ばれる、複数のタスクで構成された(compositional structure)スパースな報酬の問題を解くことが出来る手法を紹介します。
手法
SIRは主に2つの構成要素、task reductionとimtiation learningから成り立っています。Task reductionはパラメーター化されたタスク空間におけるcompositionality (構成性原理)を利用して、解くことが出来ていない難しいタスクを、すでに解決策を知っている簡単なタスクに単純化していきます。そして、task reductionにより困難なタスクが解くことが出来た際には、解くことによって得ることが出来た軌跡を用いてimitation learningを行い、学習の高速化を図ります。下図は、物体を押すタスクにおけるtask reductionの概要について表しています。タスクが簡単な場合は、青い物体を真っ直ぐに押すだけで解くことが出来ますが、難しいタスクの場合、茶色の障害物が邪魔なために、青い物体をただ押すだけではタスクを解くことが出来ません。そこで、まず茶色の物体が異なる初期状態の簡単なタスク(左図)においてタスクを解き、その後、仮に茶色い物体が塞いでいる場合は、タスクが解くことが出来るような茶色い物体の位置に移動を行うようにtask reductionを行い、reductionされた状態からタスクを簡単に解けるようにします。本章ではこれらtask reductionと、self-imitationについて詳しく説明をしていきます。

Task Reduction
Task reductionでは、解くことが難しいタスク $A \in \mathcal{T}$をagentが学習をして解くことが出来るタスク$B \in \mathcal{T}$に変換し、もとのタスク$A$を解くために、2つの簡単なタスクを解くだけで済むようにします。つまり、タスク$A$から$B$に変換して、タスク$B$を解くということです。これをもう少し詳しく説明すると、agentが解けないタスク$A$の初期状態$s_{A}$とゴール$g_{A}$に対して、初期状態$s_{B}$とゴール$g_{b}$で表され$s_{A}$から$s_{B}$が簡単に到達できるようなタスク$B$を探します。ここでタスク$B$のゴール$g_{B}$はタスク$A$のゴール$g_{A}$と同じです($g_{B} = g_{A}$)。ではどのようにして、タスク$B$が簡単かどうかを測れば良いでしょうか。これは、universal value function $V(\cdot)$を使うことで図ることが出来ます。つまり、下の式を満たすような$s^{\star}_{B}$を探します。
$$s_{B}^{\star}=\arg \max_{s_{B}} V(s_{A}, s_{B}) \oplus V(s_{B}, g_{A}):=\arg \max_{s_{b}}V(s_{a}, s_{B}, g_{A})$$
ここで、$\oplus$はcommposition operatorを表しており、いくつかの選択肢、minimum, average, productなどがありますが、本論文ではproductを用いて$V(s_{A}, s_{B}, g_{A})=V(s_{A}, s_{B})\cdot V(s_{B}, g_{A})$としています。
$s^{\star}_{B}$が見つかり次第、agentは$\pi(a|s_{A}, s^{\star}_{B})$を$s^{\star}_{A}$から実行します。そして、成功となる$s^{'}_{B}$に到達をしたら(つまり$s^{\star}_{B}$周辺)、$\pi(a|s^{'}_{B}, g_{A})$を実行し、最終的なゴールに到達することを試みます。ただし、この2つのpolicyの実行のどちらかが失敗する可能性があることから、いつもtask reductionが成功するわけではありません。失敗の原因として2つ考えられ、一つはvalue functionの近似誤差、そして2つめはタスクAが単に現在のpolicyにとって難しすぎるということです。1つ目に関しては実際に方策を実行してみないとわからないもので、2つ目は、task reductionをタスクを解くことが可能でありそうなときのみ行うようにすることでサンプル効率性を上げることが出来ます。これを行うために、本論文では$V(s_{A}, s^{\star}_{B}, g_{A})$がある閾値$\sigma$を超えたときに、task reductionを実行するようにしています。
Self-Imitation
Task reductionが困難なタスク$A$に対して行われ、$s^{\star}_{B}$を探すことに成功した場合、2つの軌跡、$s_{A}$から$s^{'}_{B}$、そして$s^{'}_{B}$から$g_{A}$を得ることが出来ます。そして、これらの2つの軌跡を合わせることにより、元のタスクのdemonstrationを得ることが出来ます。よって、このdemonstrationを集めることで、imitation learningをこれらの集めたself-demonstrationに対して適用することが出来ます。本論文では、Imitatin learningの目的関数として以下の$A(s, g)$によって重み付けされたものを利用します。
$$L^{il}(\theta; \mathcal{D}^{il})=\mathbb{E}_{(s, a, g) \in \mathcal{D}^{il}}[\log \pi (a | s, g)]A(s, g)_{+}$$
ここで、$A(s, g)$はclipped advantageを表し、$max(0, R-V(s, g))$と計算されます。このself-imitationを行うことにより、agentは効率的に難しいタスクを解くことが出来るようになります。
SIR: Self-Imitation Via Task Reduction
最後に、deep RLとtask reductionによるself-imitationを組み合わせた手法であるSIRについて説明します。SIRはon-policyとoff-policy RLどちらに対しても利用することが出来ます。本論文ではsoft actor-critic (SAC)とproximity policy gradient (PPO)に対して実験を行いました。一般的に、RLアルゴリズムはactorとcriticを集められたrollout data $\mathcal{D}^{rl}$を用いて学習します。このloss関数を$L^{actor}(\theta; \mathcal{D}^{rl})$と$L^{critic}(psi; \mathcal{D}^{rl})$
Off-policy RLでは、単純に集められたdemonstrationをexperience replayのデータと合わせるようにし、以下の目的関数を最適化します。
$$L^{SIR}(\theta; \mathcal{D}^{rl}, \mathcal{D}^{il})=L^{actor}(\theta; \mathcal{D}^{rl} \cup \mathcal{D}^{il}) + \beta L^{il}(\theta; \mathcal{D}^{rl} \cup \mathcal{D}^{il})$$
On-policy RLでは、集められたdemonstrationのみに対してimitation learningを行うようにし、また、$\mathcal{D}^{il}$のデータセットサイズは、$\mathcal{D}^{rl}$のサイズよりも基本的に小さいので、それぞれのLoss関数に対して以下のように重み付けを行った目的関数が利用されます。
$$L^{SIR}(\theta; \mathcal{D}^{rl}, \mathcal{D}^{il})=\frac{||\mathcal{D}^{rl}||L^{actor}(\theta; \mathcal{D}^{rl}) + ||\mathcal{D}^{il}||L^{il}(\theta; \mathcal{D}^{il})}{||\mathcal{D}^{rl}\cup \mathcal{D}^{il}||}$$
実験
本実験では、SIRと主にtask reductionを使わないベースライン手法を3種類のMuJoCoのシミュレーションを利用した環境にて比較しました。3種類の環境は、ロボットが障害物をどけた上で物体を押す"Push"タスク、物体を積み重ねていく"Stack"タスク、そして最後に"Maze"タスクになります。そしてすべてのタスクはスパースな報酬の問題となっており、つまりタスクを解くことが出来た場合にのみ$1$の報酬を得ることができ、さもなければ$0$が与えられます。ベースライン手法として、PushとStackのタスクにはSAC、Mazeに関してはPPOを用いました。
Push Scenario
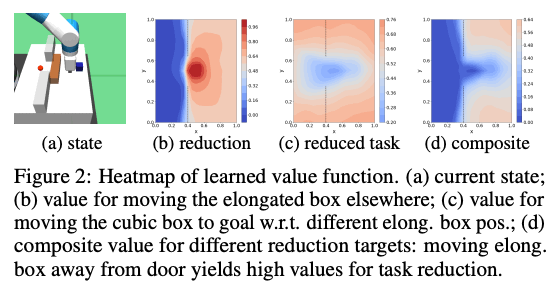
下図の通り、環境には、青い物体と茶色い細長い物体の2つがあり、ロボットは青い物体を赤い点の場所まで動かさなければなりません。下図の(b)は細長い物体を動かすための学習されたvalueを表しており、(c)は異なる細長い物体の位置に関する青い物体をゴールに動かすための学習されたvalue、そして(d)は合わせたvalueとなっています。
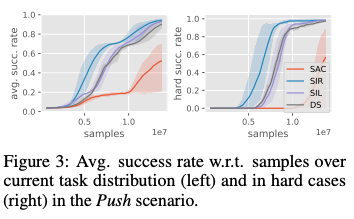
下図はこのタスクに関する結果を示しており、左図は難しいタスクと簡単なタスクの両方からランダムにサンプルされた際のパフォーマンス、右図は難しいタスクのみを用いたパフォーマンスを表しています。下図におけるSILはSACとSelf-Imitationを組み合わせたもので、task reductionが行われない場合です。またDSはSACをdense rewardにて学習を行ったものを表しています。下図の結果から、SIRが難しいタスクにおいてもより効率良く解くことが出来ていることが分かります。
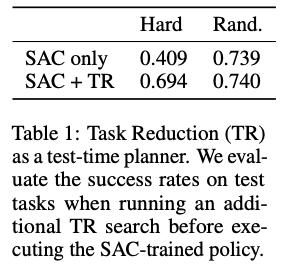
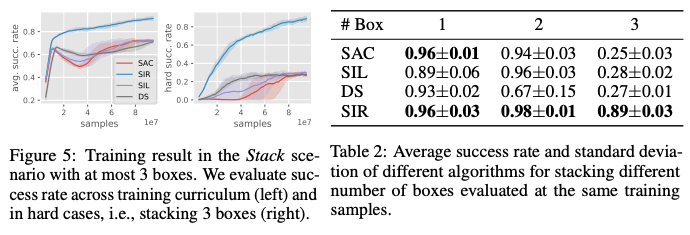
Stack Scenario
このタスクでは、多くとも3つの異なる色の物体が与えられ、ターゲットの色と同様の物体がターゲットに到達するように物体を積み重ねる必要があります。このタスクでは、各エピソードごとで物体の数、初期位置、そして色がランダムに指定されます。このタスク自体がとても難しいタスクであることから、pick-and-placeタスクを補助タスクとして追加をし、はじめは70%をpick-and-place、残りがstackタスクを解くようにし、学習を進めていくごとにpick-and-placeタスクを解く割合を減らし、最終的に30%まで減らしていくことで、このタスクを学習できるようにします。

下図からわかるように、提案手法であるSIRは物体の数が3つであっても高い精度でタスクを解くことに成功しましたが、他の手法では物体の数が多くなるほど成功率が下がり、特に物体の数が3つの際は特に低い成功率となっています。
Maze Scenario
このMazeタスクでは、全部で4つの部屋で成り立っており、次の部屋に行くためには、茶色の細長い壁をどかしてあげなければなりません。また最終的に、タスクを解くために、緑の物体を赤のゴールまで押してあげなければなりません。このタスクにおいて、難しいケースは、物体を別の部屋に移動させなければならない時、そして少なくとも1つのドアが細長い壁によってブロックされていることです。
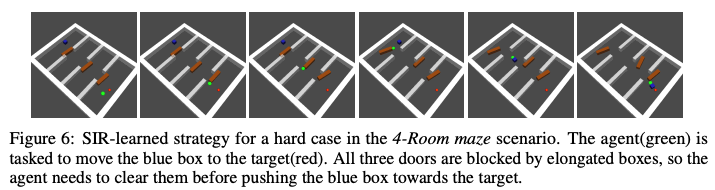
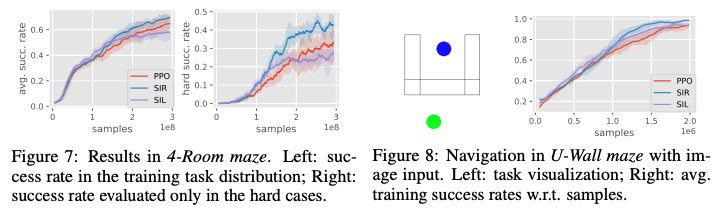
下図右のうちの左側のグラフはタスクの難しいケースと簡単なケースすべてが含まれている場合のタスクの成功率で、右側のグラフが、難しいケースのみの結果となっています。結果からわかるとおり、難しいタスクのケースにおいて、他の手法と比べて提案手法は比較的高めの成功率となっていますが、他の手法は低い成功率となっています。また、今まではstate空間における学習でしたが、画像を入力とした際の学習を下図右のU-Wall mazeに対して行いました。その結果、下図右の右側のグラフから分かるとおり、提案手法であるSIRが一番高いタスクの成功率となっていることから、この手法の有効性が分かりました。
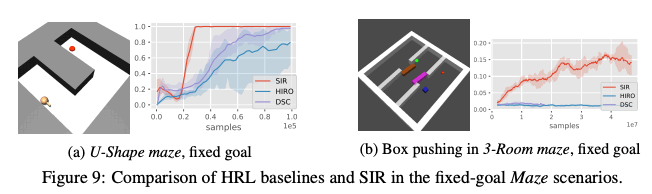
さらに、下図のU-shape mazeとゴールが固定された3-Room mazeにおいて、SIRをHierarchical RL(階層型RL)であるHIROとDSCtode比較を行いました。その結果、下図の通り、SIRの精度が高く、サンプル効率性も高いのに対して、他の手法はサンプル効率性が悪く、そして同等の成功率を達成することが出来なかったことが分かります。
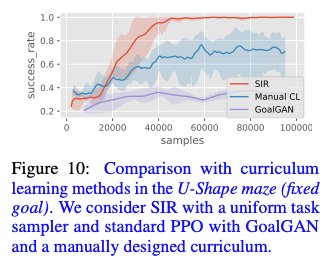
Curriculum Learningとの比較
提案手法であるSIRは、はじめに簡単なタスクを解き、そして難しいタスクをtask reductionによりすでに解くことが出来ているタスクに分割することから、暗にtask curriculumを作っていると考えることが出来ます。よって、ゴールが固定されたU-mazeのタスクにおいて、SIRとcurriculum learningを用いた手法であるGoal-GAN、そして手動でcurriculmを作ったManual CLと比較をしました。下図の結果から、提案手法であるSIRが高い成功率を示していることが分かります。
まとめ
本記事ではSIRと呼ばれる、難しいタスクをtask reductionを行うことによって、すでに解くことが出来ている問題と、その状態にするまでのタスクに分割する手法について紹介しました。RLは比較的簡単かつ綺麗な環境に対してはうまく学習することが出来ますが、本論文のような複雑な環境下では学習があまりうまくいきません。現実世界における問題も複雑な環境下のもであることが多ことからとても重要なトピックだと考えています。





この記事に関するカテゴリー






